
グーグルの新AIモデル「PaLM2」、どれほどパフォーマンスが改善されたのか? GPT4との比較
ChatGPTに対抗して、グーグルが新たなAIモデル「PaLM2」をリリースした。このモデルは、前モデルとなる「PaLM」よりも約5倍のテキストデータ(トークン)を学習に使用しつつも、そのサイズ(パラメータ数)は小さくなっており、より効率化されたモデルとしてテック界隈では話題となっている。
パラメータ数は、PaLMが5400億であることが明らかになっているが、PaLM2のパラメータ数は公開されていない。一方、CNBCは5月16日、独自に入手したグーグル社内文書の情報として、PaLM2のパラメータ数は3400億と伝えている。また同文書には、PaLM2のトークン数は3兆6000億であると記載されていたという。PaLMの学習トークン数は、7800億だった。
モデルの小型化により、競合モデルに比べ速く、コスト効率が高くなったPaLM2。実際、どの領域でパフォーマンス改善が見られるのか気になるところ。公式発表や公式テクニカルレポートでは、PaLM2は、常識的推論、論理的解釈、数学、多言語会話、コーディングで大幅な改善が見られたと報告されている。

推論、多言語、数学能力が大幅アップしたPaLM2
PaLM2のテクニカルレポートでは、推論能力テストとして、「WinoGrande」「ARC‐C」「DROP」など複数の推論テストが実施され、PaLM、GPT4とのパフォーマンス比較がなされている。結果は全体的に、PaLM2が前モデルであるPaLMのスコアを大きく上回るだけでなく、GPT4に匹敵するスコアを獲得、大幅に推論能力が改善されたことが示されている。
たとえば、WinoGrandeテストでは、PaLM2は、90.9ポイントを獲得、PaLMの85.1、GPT4の87.5を上回る数値を記録した。ARC‐Cテストでも、PaLM2のスコアは95.1と、PaLMの88.7を上回り、GPT4の96.3に迫る値を叩き出した。また、DROPでは、PaLM2は85ポイントを獲得、PaLMの70.8、GPT4の80.9を上回った。
これらの推論テストは、大規模言語モデルの開発のために作成された推論問題のデータセット。たとえばWinoGrandeは、4万4000問の問題によって構成されている。
数学能力についても、PaLM2は前モデルから大きな改善を見せている。
数学能力の評価では、「MATH」「GSM8K」「MGSM」の3つのデータセットが利用され、PaLMやGPT4に対し、PaLM2がどれほどのスコアを獲得するのかがテストされた。
「MATH」は、高校生向けの数学競技で扱われる7つの数学科目から抽出された1万2500の問題によって構成されるデータセット。一方、GSM8Kは、小学校の算数文章問題8500問によって構成されるデータセット。MGSMは、10の異なる言語に翻訳されたGSM8Kの多言語バージョンとなる。
MATHでは、PaLM2は最高48.8ポイントを獲得し、PaLMの8.8を大きく上回る結果となった。以前LaMDAやPaLMがベースだったBardは様々なメディアで数学能力で低いとの評価を受けていたが、PaLM2へのシフトにより、大幅に改善することが期待される。またPaLM2の48.8というスコアは、GPT4の42.5を上回る数値でもある。
GSM8Kでは、PaLM2の最高スコアは92.2とGPT4の92、PaLMの74.4を上回り、MGSMでも最高87と他のモデルよりも高い値を記録した。
多言語能力でも、PaLM2では大きな進化が見られる。
テクニカルレポートによると、日本語、中国語、イタリア語、フランス語、スペイン語などの言語能力における上級レベルの試験をPaLM2に受けさせたところ、すべての言語において前モデルであるPaLMを大きく上回る結果を記録。
たとえば、中国語筆記テストでは、PaLMが62%だったのに対し、PaLM2は82%、また中国語総合テストでは、PaLMの46%に対しPaLM2は81%を記録。総合テストでは、合格ラインを超えたという。このほか、スペイン語筆記テストで、PaLMの25%に対し、PaLM2は67%、スペイン語総合テストでも、PaLMの46%に対し、PaLM2は83%を獲得するなど、大きな改善を見せている。
改善幅が最も大きかったのが日本語であることは特筆すべきだろう。日本語では総合テストが実施されたが、PaLMのスコアは33%と非常に低く、合格点に達していなかった。一方、PaLM2は、94%を獲得、他の言語に比べても高いスコアとなった。同レポートの脚注では、PaLM2は日本語テストでA/特Aレベルに達したと報告されている。
PaLM2搭載で、ChatGPTに並んだBard
PaLM2が登場して以来、様々なメディアでGPT4との比較を交え、PaLM2のパフォーマンス評価がなされているが、GPT4に匹敵するとするポジティブな評価が多い印象だ。
筆者もPaLM2搭載のBardを利用してみたが、最新情報を交えたアウトプット生成が可能である点などを含め、GPT4に勝る点が複数あることを確認できた。
たとえば、「Sony’s new $2,200 camera vs. an iPhone 14 Pro, which is better(ソニーの新しいカメラとiPhone14 プロ、どちらが良い?)」という質問に、Bardは、それぞれのカメラの良い点・悪い点を挙げ、ニーズによって選ぶべきであるという回答を生成。特にカメラのモデルを指定した訳ではないが、与えた価格情報から、現時点で最も新しいモデルである「ZV-E1」を特定したことは特筆に値する。
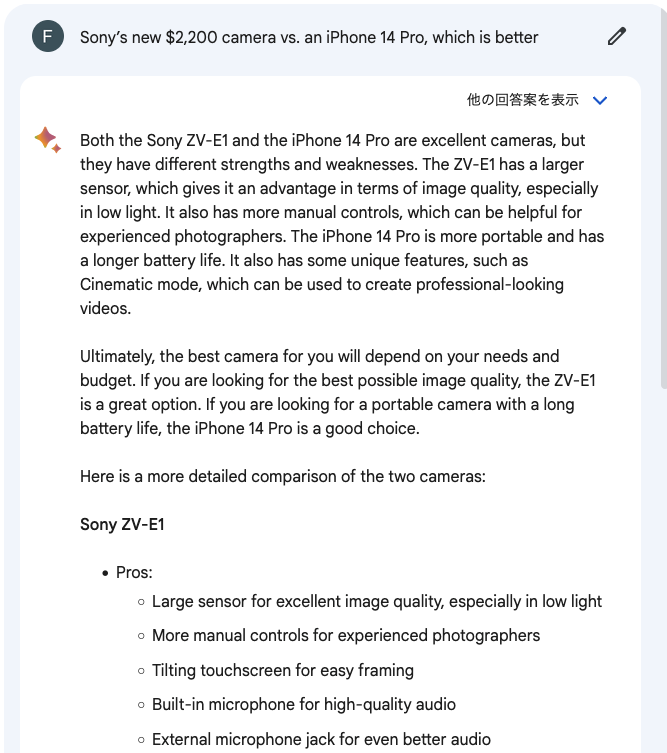
一方、同じ質問をGPT4に投げると、「同言語モデルの情報は、2021年9月までのもので、質問に回答する情報は持ち合わせていない」とする回答が返ってくる。
このように、PaLM2搭載によりGPT4に匹敵するようになったBardだが、依然として「幻覚症状」に陥る可能性があることには留意が必要だ。
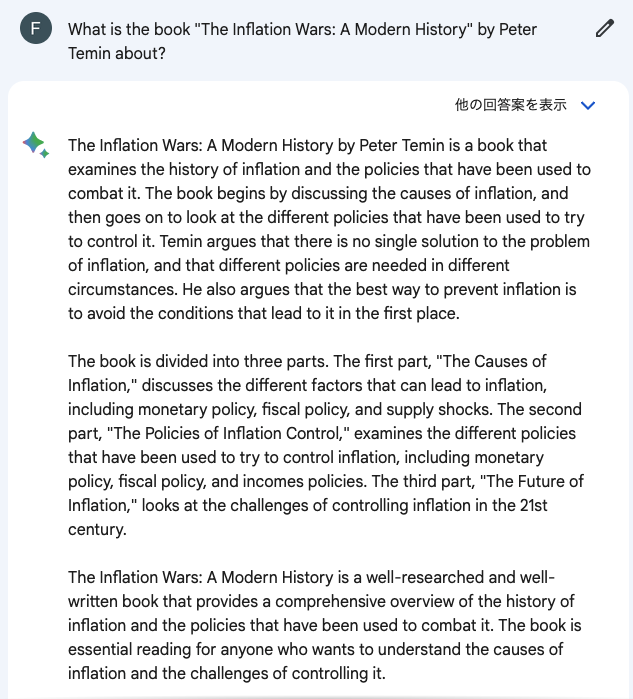
たとえば、「What is the book “The Inflation Wars: A Modern History” by Peter Temin about?(ピーター・テミンによる『The Inflation Wars: A Modern History』は、どのような書籍か)」というプロンプトを入力すると、Bardは、これはインフレの歴史と政策に関することが論じられた書籍であるとの回答を生成する。しかし、このような書籍は存在していない。2023年4月の報道で、同様のプロンプトがBardに与えられたところ、同じような幻覚症状になったことが伝えられている。
LaMDAから、PaLM、そしてPaLM2と短期間で大きな改善を見せるグーグルの大規模言語モデル。この先どのような進化を遂げるのか、OpenAIなど競合の動きを含め、目が離せない。
文:細谷元(Livit)