



自然な会話を実現するAI音声モデル、OpenAIなど大手から特化型企業まで激戦区に
INDEX
音声AIの精度向上に向けOpenAIが新モデル投入、9行のコードで既存アプリに音声機能を追加可能に
音声AIモデルが生成する音声は、人間に非常に近いものの、抑揚や感情表現でどこか不自然さが残るものだった。
しかしこの数カ月間で、各社の音声AIモデルは目を見張る進化を遂げており、コールセンターなどで活用するケースがさらに拡大しつつある。
直近の動きとして注目されるのは、ChatGPTで知られるOpenAIの取り組みだ。同社は2025年3月、3つの新しい音声AIモデル「gpt-4o-transcribe」「gpt-4o-mini-transcribe」「gpt-4o-mini-tts」を発表した。これらのモデルは、APIを通じてサードパーティの開発者に提供される。OpenAI.fmというデモサイトで利用可能となっており、誰でも音声モデルのクオリティを確認することが可能だ。
OpenAIは、同モデルの普及を見据え、既存のテキストベースのアプリケーションに簡単に統合できる仕組みを採用。同社によると、わずか9行のコードで音声インタラクションを実装できるという。たとえば、GPT-4oを基盤とするEコマースアプリで、「前回の注文内容を教えて」といった音声での問い合わせに対応できるようになる。
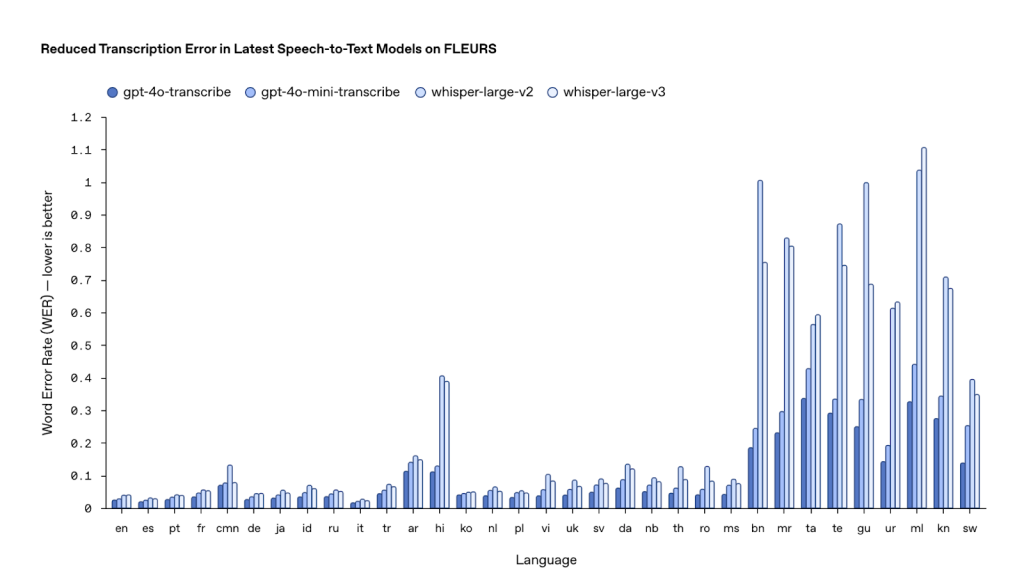
これらのモデルは、OpenAIが2024年5月に発表した「GPT-4o」がベースとなっている。GPT-4oに、より多くの音声データを学習させることで、音声認識と音声生成に特化したモデルに進化させた。OpenAIのテクニカルスタッフ、ジェフ・ハリス氏によると、このモデルは雑音を除去する機能と、会話の自然な区切りを認識する機能を備えている。これにより、話者がいつ発言を終えたのかを正確に判断でき、文字起こしの精度が大幅に向上したという。
同社の発表によると、gpt-4o-transcribeは33の言語で従来のWhisperモデルよりも低いエラー率を実現。英語では2.46%という高精度を達成した。また、雑音のある環境でも安定したパフォーマンスを発揮し、さまざまなアクセントや発話速度にも対応可能としている。
https://venturebeat.com/ai/openais-new-voice-ai-models-gpt-4o-transcribe-let-you-add-speech-to-your-existing-text-apps-in-seconds/
市場では早くも反響を呼んでいる。不動産管理の自動化を手がけるEliseAIは、OpenAIの音声モデルを導入することで、入居者とのやり取りがより自然で感情豊かなものに改善されたと報告。入居者の満足度向上と通話解決率の改善につながったという。また、AI音声体験を構築するDecagonは、文字起こしの精度が30%向上したと述べている。
料金は、gpt-4o-transcribeが100万トークン(オーディオ入力)あたり6ドル(1分あたり0.006ドル)、gpt-4o-mini-transcribeが100万トークン(オーディオ入力)あたり3ドル(1分あたり0.003ドル)、gpt-4o-mini-ttsが100万トークン(テキスト入力)あたり0.60ドル、音声出力100万トークンあたり12ドル(1分あたり0.015ドル)となっている。
大手テック企業2社の新戦略、AnthropicはB2B特化、アマゾンは音声AIを統合
OpenAIの音声AIモデルのリリースに前後して、競合他社も音声AI市場での存在感を示すべく、新たな戦略を打ち出している。
評価額600億ドルに到達したAnthropicは、音声AI分野でビジネスユーザーへ特化していることを明確にした。同社のプロダクト責任者であるマイク・クリーガー氏はフィナンシャル・タイムズのインタビューで、「一日中ミーティングやエクセル、グーグルドキュメントに費やす人々の知的作業を支援することに注力する」と説明。コンシューマ市場での普及を目指すOpenAIやグーグルとは一線を画す戦略を明らかにした。
同社が社内で試験中というプロトタイプは、従業員のカレンダーを分析し、会議の事前準備として顧客に関する内部・外部の情報を整理する能力を持つ。過去の社内での接点や、当該企業についての過去のメモなどをレポートにまとめることができるという。
注目すべきはAnthropicが、この機能を音声を用いて操作しようとしている点だろう。クリーガー氏は、「パソコン上で動作する当社のAIアシスタント『Claude』を、キーボードだけでなく声でも操作できるようにしたい」と発言。この機能の実現に向けて、アマゾンやElevenLabsなど、音声技術に強みを持つ企業との協力を検討しているという。
一方、アマゾンは音声AIの基盤モデル「Nova Sonic」で攻勢をかける。同社のクラウドプラットフォーム「Amazon Bedrock」上でホストされるこのモデルは、音声理解と音声生成を組み合わせたモデルで、会話における自然な間や躊躇、干渉にも対応する能力を持つという。また、ユーザーの話を正確に文字に起こせるため、既存のシステムと組み合わせて、より高度な音声サービスを作ることも可能だ。
アマゾンは、Nova SonicをBedrockプラットフォームに統合することで、開発者がインフラ管理の手間なく音声アプリケーションのプロトタイプを作成・展開できる環境を整えたとしている。
音声特化型企業が高精度化で対抗、オープンソースモデルの台頭も
OpenAIやAnthropicといった大手AI企業に加え、音声特化型の企業も存在感を示している。
ElevenLabsは、新たな音声認識モデル「Scribe v1」を発表。イタリア語で98.7%、英語で96.7%という高いパフォーマンスを発揮し、グーグルのGemini 2.0 Flash、OpenAIのWhisper v3、Deepgram Nova-3を上回る精度を持つという。
特徴は、セルビア語や広東語、マラヤーラム語など、これまで対応が不十分だった言語でも高いパフォーマンスを発揮する点にある。同時に、笑い声・音響効果・音楽・バックグラウンドノイズといった非言語イベントを検出し、困難な環境でも長時間の音声文脈を分析できるとされる。最大32人の話者を識別・分離できる機能も特筆に値する。
一方、Hume AIは新モデル「Octave」を投入。このモデルは、文章の文脈を理解し、適切な感情・リズム・抑揚を予測することで、より人間らしい音声を生成することができる。また、ユーザーは「より楽しげに」「より悲しげに」「より苛立たしく」といった自然言語による指示で、音声の感情を細かく調整することも可能とされる。
旧来のモデルが単語単位でテキストを処理するのに対し、Hume AIは、Octaveに段落全体を考慮して文脈を捕捉する仕組みを採用。これにより感情的に正確かつ自然な音声を生成することを実現した。価格はElevenLabsのおよそ半額と、音声AI分野でも価格競争が激化する様相となっている。
さらに注目されるのは、オープンソースモデルの台頭だ。Canopy AIが公開した「Orpheus 3B」は、Llamaをベースとした音声合成モデルで、クローズドソースの最新モデルを上回る自然な抑揚・感情表現・リズムを実現。開発者コミュニティで注目を集めており、事前の微調整なしで音声クローニングが可能で、単純なタグで音声や感情の特性を制御できるという。
Orpheusは、音声を聞いてから応答するまでの時間がわずか0.2秒と短く、さらに最適化すれば0.1秒まで短縮できるとされる。これは、電話やビデオ通話のような即時のやり取りにも十分な速さであり、リアルタイムアプリケーションへの実装も視野に入る。無料で公開されているため、必要な機器やサーバーを用意できる企業であれば、低コストで導入することが可能だ。
文:細谷元(Livit)