
中国発DeepSeek R1を安全に使い倒す 米国製ハードウェアが実現する驚異の処理速度
INDEX
DeepSeek R1を安全に使う方法
世間を騒がせている中国発のAIモデルDeepSeek R1は、開発コストに関するさまざまな憶測が流れ、また利用に関するリスクが指摘されている。それでも性能面とコスト面を鑑みると、使い方次第では、コストを抑えつつ生産性を大きく改善できる可能性を秘める。
実際、同モデルのAPI利用料(入力・出力混合価格)は100万トークンあたり1ドルと、OpenAIのo3-miniの1.9ドル、AnthropicのClaude 3.5 Sonnetの6ドルと比較して、非常に魅力的な価格設定となる。
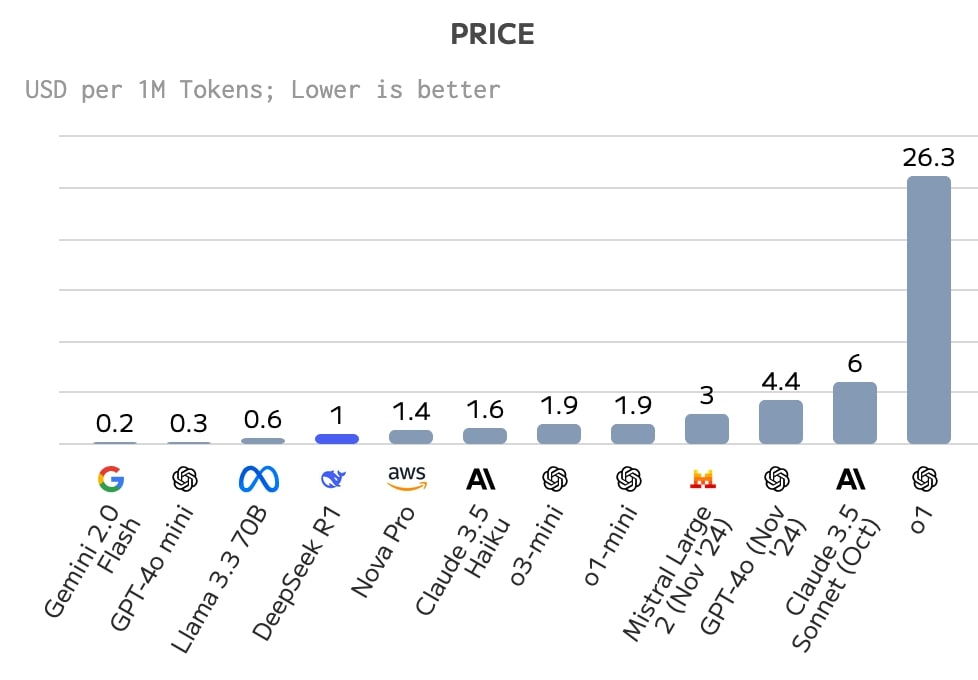
https://artificialanalysis.ai/models/deepseek-r1/providers
そこで注目されるのがR1のリスクを下げつつ利用する方法だ。企業での活用を想定した場合、DeepSeek R1を利用する方法は大きく2つ。中国拠点のDeepSeek社が提供するAPIを使うか、他のプロバイダのAPIを使うか。米国や欧州拠点のプロバイダであれば、基本的に中国国外のサーバーを利用していることが想定されるためリスクを下げつつ利用できるようになる。
選択肢としては、米カリフォルニア拠点のTogether AI、Fireworks AI、Hyperbolic、DeepInfra、オランダのNebius、カナダのCentMLなどが挙げられる。これらのプロバイダは、ほとんどのケースにおいて既存のGPUクラスタにオープンソースモデルを搭載し、クラウドAPIでそれらのモデルを提供している。これらのプロバイダを使うことで、DeepSeek R1を安全に利用することが可能となる。
ただし、GPUベースの従来型インフラに依存したこれらのAPIサービスは、処理速度の面で大きな課題を抱えているのが現状だ。Artificial Analysisの調査によると、現時点でR1を最も高速で提供しているFireworks AIでも1秒あたり86.7トークンにとどまり、OpenAIのo3-miniが示す184トークンという処理速度には遠く及ばない。Together AIも83.9トークンと同水準だ。Microsoft Azureは9.9トークン、DeepInfraは8.2トークンと、さらに低速という結果となっている。
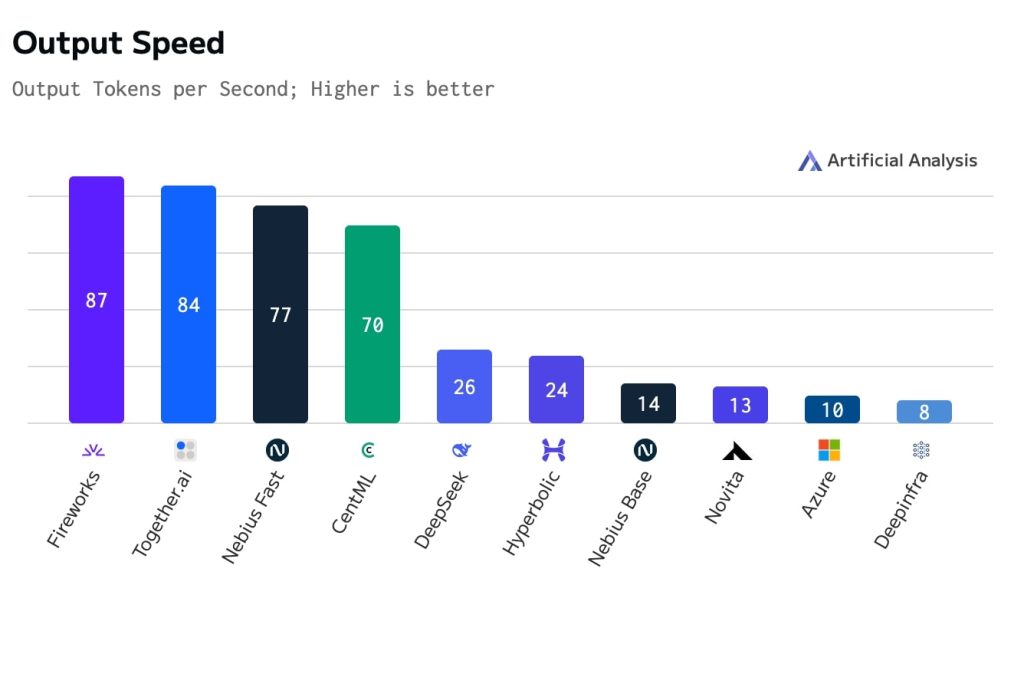
https://artificialanalysis.ai/models/deepseek-r1/providers
一方、この状況を打開する新たなアプローチが、次世代のハードウェアを採用する企業から登場しており、安全かつ爆速でDeepSeek R1を利用できる環境が整いつつある。
安全かつ爆速でDeepSeek R1を使う方法、その1:CerebrasのAPI
爆速でDeepSeek R1を提供する企業の1つが米国のAIチップ企業Cerebrasだ。
同社は、DeepSeek R1の700億パラメーターモデルを自社開発のウェハースケールハードウェア上で稼働させることで、1秒あたり1,500トークン以上という圧倒的な処理速度を実現したと発表した。
Cerebrasが実現した処理速度の優位性は、具体的な数値で示されている。標準的なコーディングプロンプトの処理において、OpenAIのo1-miniが22秒を要するのに対し、Cerebrasのシステムはわずか1.5秒で完了。実に15倍の高速化を達成した。
また最も近い競合であるGroqと比較しても約6倍、従来のGPUベースのソリューションと比較すると約57倍の高速性を誇る。この圧倒的な性能差は、同社独自のチップアーキテクチャによって実現されている。AIモデル全体を単一のウェハーサイズのプロセッサ上に保持することで、GPUベースのシステムで問題となるメモリボトルネックを解消したという。
さらに重要な点は、このソリューションが米国内のデータセンターで運用される点だ。同社のシニアエグゼクティブであるジェームス・ワン氏は「DeepSeekの公式APIを利用した場合、データは中国に送信される。この点が、多くの米国企業が導入を躊躇する重大な懸念事項となっている」と指摘している。
現在、DeepSeek R1のAPIは早期ユーザーからの予想を超える需要により、ウェイトリストによるアクセスコントロール状態にある。
安全かつ爆速でDeepSeek R1を使う方法、その2:SambaNovaのAPI
Cerebrasだけでなく、SambaNovaも独自のハードウェアアーキテクチャを用いたDeepSeek R1の高速処理を実現した。同社は、RDU(Reconfigurable Dataflow Unit)と呼ばれる独自チップを活用し、1秒あたり198トークンという高速処理を達成。特筆すべきは、SambaNovaが700億パラメーターの縮小版ではなく、6710億パラメーターの完全版R1モデルを稼働させている点だ。
AI研究の第一人者でLanding AIの創業者兼CEOであるアンドリュー・ウン氏も「完全版R1モデルをSambaNovaの驚異的な速度で実行できることは、開発者にとってゲームチェンジャーとなる。R1のような推論モデルは、優れた出力を生成できるが、多くの推論トークンを必要とするため、従来のLLMよりも処理時間が長くなる。それだけに、この高速化の意義は大きい」と高い評価を下す。
完全版は、縮小版では難しい推論を実行することが可能で、実際、完全版R1が自身の実行効率を改善する方法を推論し特定した事例などが報告されている。
SambaNovaのRDUチップは、DeepSeek R1のような大規模なMixture of Experts(MoE)モデルの処理に最適化されている。データフロー方式のアーキテクチャと3層メモリ設計を採用したSN40L RDUにより、GPUベースのソリューションでは40ラック(320基のGPU)を必要としたDeepSeek R1(6,710億パラメーター)をわずか1ラックのみで運用できるようになった。
同社はまた、米国内のデータセンターでの運用に加え、企業の自社データセンターへのハードウェア導入オプションも提供。プライバシーとセキュリティを重視する企業のニーズにも対応する体制を整えている。
この効率性を武器に、SambaNovaは2025年末までにDeepSeek R1モデルの処理能力を大幅に拡大する計画だ。
現在SambaNovaのDeepSeek R1モデルAPIを利用するには、ウェイトリストに登録する必要がある。
(文)細谷元(Livit)