
Hugging Faceの最新小型AIモデル「SmolVLM」、ビジョン/テキストタスクで圧倒的コスト削減の可能性
INDEX
さらに進む、AIモデルの小型高性能化
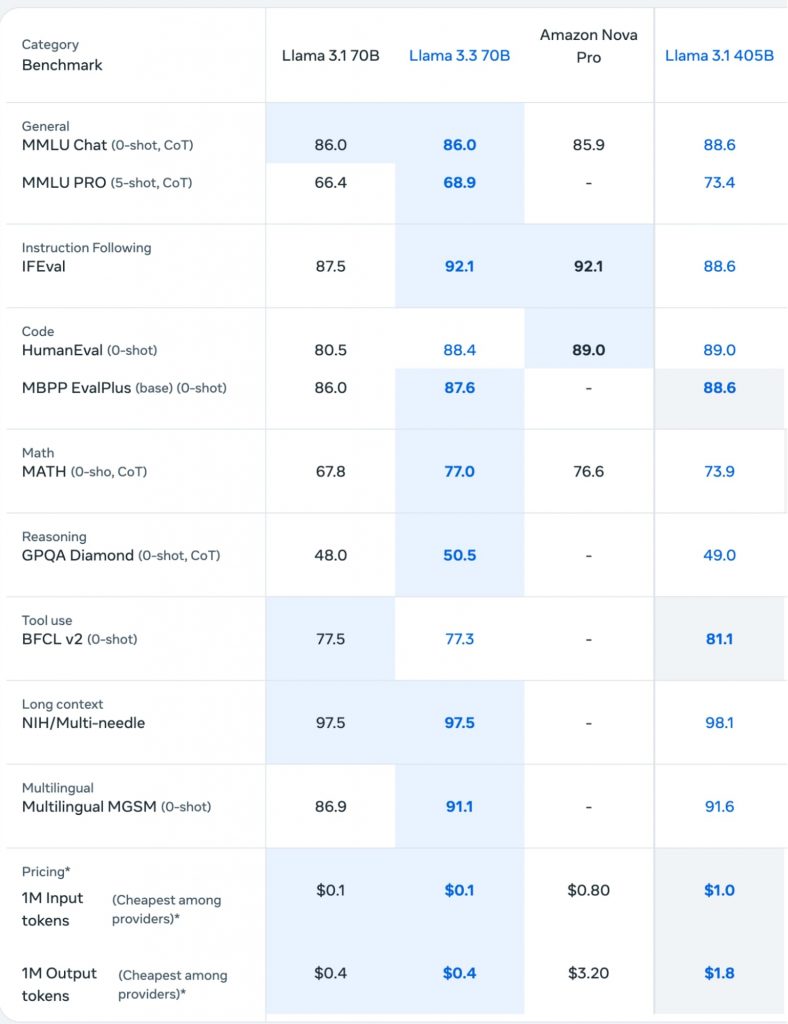
AIモデルの高性能化と小型化の流れが加速している。メタが2024年7月にリリースしたLlama 3.1 405B(4,050億パラメータ)と、その5カ月後にリリースされたLlama 3.3 70B(700億パラメータ)の性能を比較すると、その進化の速さが見て取れる。
Llama 3.1 405Bは基本的な言語理解力を測るMMLU Chatテストで88.6%のスコアを記録したが、パラメータ数が約6分の1のLlama 3.3 70Bも86.0%とほぼ同等の性能を示したのだ。
さらに、指示への追従性を測るIFEvalでは、Llama 3.3 70Bが92.1%とLlama 3.1 405Bの88.6%を上回る結果となった。プログラミングコードの生成能力を測るHumanEvalでも、Llama 3.3 70Bは88.4%と、Llama 3.1 405Bの89.0%に肉薄する数値を叩き出した。
コスト面も大きな改善が見られる。Llama 3.3 70BとLlama 3.1 405Bを比較すると、入力トークンあたりのコストは10分の1、出力トークンあたりのコストは4.5分の1まで縮小。企業のAI導入における課題の一つとして、コンピューティングリソースの確保とランニングコストが挙げられるが、AIモデルの小型高性能化により、精度を維持しつつコストを大幅に下げることが可能になりつつある。
https://www.llama.com/
こうした小型高性能化の流れは、Hugging Faceが2024年11月にリリースした新しい視覚言語モデル「SmolVLM」にも顕著にあらわれている。SmolVLM(22億5,000万パラメータ)は、画像とテキストの両方を処理できるマルチモーダルモデルながら、必要なGPU RAMはわずか5.02GBと、競合モデルのQwen-VL 2Bの13.70GBやInternVL2 2Bの10.52GBと比較して圧倒的に低いメモリを誇る。
Hugging Faceのリサーチチームによると、SmolVLMは基本版、性能強化版、指示対応版の3つのバリエーションが用意されており、ハードウェアのスペックや用途に応じて、柔軟な選択が可能となっている。
SmolVLMの強みとは?
SmolVLMは、どのようなタスクで強みを発揮するのか、また技術的にどのような特徴を持つのか詳しく見ていきたい。
各ベンチマークテストの結果は、数学的視覚理解力を測るMathVistaで44.6%、文書の視覚的質問応答を測るDocVQAで81.6%、テキストと画像の複合的理解力を測るTextVQAで72.7%のスコアを記録した。これらの数字は、必要なGPU RAMが2倍以上のQwen2-VL 2B(それぞれ47.8%、90.1%、79.7%)や、InternVL2 2B(46.3%、86.9%、73.4%)と比較しても、大差のない水準となっている。

https://huggingface.co/blog/smolvlm
SmolVLMの高い処理効率を実現しているのは、画像圧縮技術だ。384×384ピクセルの画像パッチを81トークンにまで圧縮する独自技術により、たとえば1枚の画像と質問文を合わせても1,200トークン程度で処理が可能となった。これに対し、Qwen2-VLは同じ処理に1万6,000トークンを必要とする。この画像圧縮技術により、SmolVLMは、複数の画像を処理する際も、メモリ使用量の増加を最小限に抑えることができるという。
動画処理では、最大50フレームまでの動画を均等にサンプリングし、フレームのリサイズを行わない単純な処理パイプラインを実装。動画の認識能力を測るCinePileベンチマークでは27.14%というスコアを達成、InterVL2(2B)とVideo LlaVa(7B)の中間に位置する性能を示した。定性的なテストでも、シーンの理解や物体認識において高い能力を発揮したと報告されている。ただし、時系列の理解には課題が残るとのこと。
https://huggingface.co/blog/smolvlm
小型モデルがさらに進化する可能性も、OpenAIのo1モデルを踏襲するアプローチ
上記の事例は、既存モデルの性能を維持しつつ、サイズを大幅に縮小するという試みである。一方、小型モデルの性能を大きく向上させるための研究も進んでいる。
HuggingFaceが2024年12月に発表したアプローチはその1つだ。これはOpenAIのo1モデルにヒントを得て開発された「テストタイム・スケーリング」と呼ばれる手法。このアプローチにより、わずか3B(30億)パラメータのモデルで、70B(700億)モデルを上回る性能を引き出すことに成功したという。
この手法の特徴は、AIが答えを導き出す際の「考える時間」を効率的に使うことにある。o1モデルのように、AIにより多くの時間をかけて「考えさせる」ことで、複数の回答案を試行錯誤させ、より正確な答えを導き出すことができるようになった。
この「じっくり考えさせる」方式について、Hugging Faceは複数の手法を提案している。最も基本的な方法は「多数決方式」で、同じ質問を何度もAIに投げかけ、最も多く出てきた回答を採用する。
より発展させたのが「ベストアンサー方式」。これは回答の質を評価する仕組みを使って、複数の回答から最適なものを選ぶ。さらに進化させた「重み付きベストアンサー方式」では、回答の一貫性や確実性も考慮に入れ、より信頼性の高い回答を選び出す。
またHugging Faceは、AIの思考プロセスを段階的に導く「探索方式」も開発。これは、AIが一気に答えを出すのではなく、途中経過を何度も確認しながら、より良い答えへと近づけていく方法となる。各段階で複数の回答案を作り、その中から有望なものを選んで次の段階に進む。これにより、AIの処理能力を最も期待できる回答案に集中させることが可能になる。
ただし、この方式にも課題がある。その1つが、回答の質を評価するために別のAIシステムを同時に動かす必要があることだ。
研究者らは、外部のAIに頼らず、回答を生成するAI自身が答えの正しさを確認できるようにすることを目指している。また現状では、数学やプログラミングのような正解が明確な問題にしか使えず、文章の創作やデザインといった正解が一つではない課題への応用には、さらなる研究開発が必要になるという。
文:細谷元(Livit)