
AIによる「パソコン操作の自動化」最前線 Anthropicが一歩リード、マイクロソフトやグーグルも注目
INDEX
AIエージェントのフロンティア、パソコン操作、Anthropicが一歩リード
生成AIの活用が拡大する中、AIエージェントの新たな開発フロンティアとして「パソコン操作の自動化」が注目を集めている。この分野で一歩リードするのが、OpenAIの最大のライバルと目されるAnthropicだ。
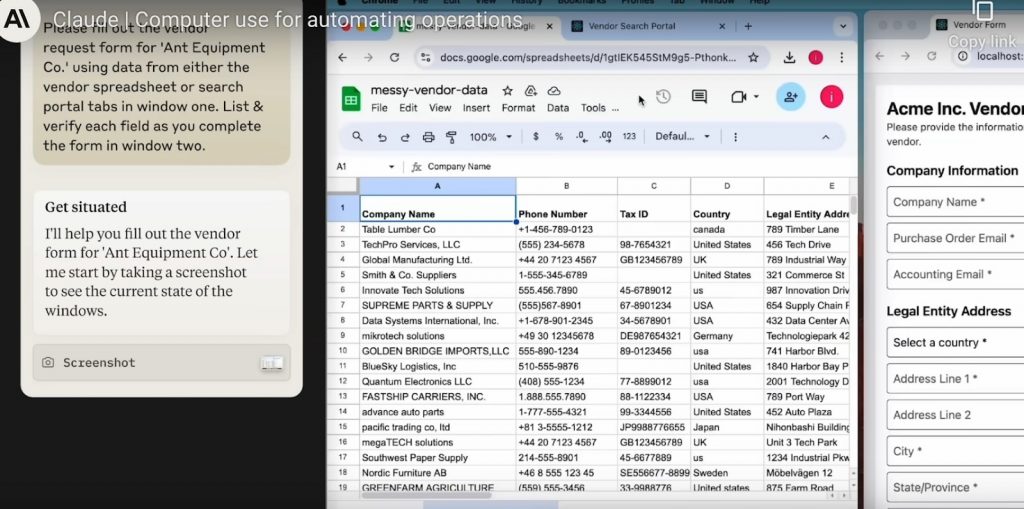
Anthropicは2024年10月22日、同社のAIモデル「Claude 3.5 Sonnet」のアップグレード版を発表。これと同時に、人間のようにパソコンを操作できる機能「Computer Use(パブリックベータ版)」を公開した。
この機能により、AIエージェントはパソコンのスクリーンショットを通じて画面を「見て」理解し、マウス操作やキーボード入力を行うことができるようになる。たとえば、スプレッドシートを開いてデータを分析し、ビジュアライゼーションを作成したり、顧客情報システム(CRM)を操作して情報を更新したりといった作業が可能になる。
すでにGitLab、Canva、Replitなどの企業が、この新機能の活用を開始。たとえばコーディングプラットフォームのReplitは、アプリケーション開発におけるテストの自動化にこの機能を活用しているという。ソフトウェア開発は、テストプロセスがボトルネックになる場合が多く、開発スケジュールの遅延要因になっている。テストプロセスの自動化がうまくいけば、開発コストを大幅に削減できる見込みだ。
https://www.youtube.com/watch?v=ODaHJzOyVCQ
Anthropicによると、この新機能は、特定のワークフローやソフトウェアに限定されず、様々なアプリケーションに対応できる柔軟性を備えている点で、従来の自動化ツールとは一線を画す。たとえば、取引先の情報を入力するフォームを完成させる際、必要な情報がスプレッドシートにない場合、自動的にCRMシステムに移動してデータを取得し、フォームに入力することができる。
ただし、現時点ではスクロールやズームといった人間にとって容易な操作がAIにとっては課題となっている。このため、Anthropicはリスクの低いタスクから開始することを推奨。スパムや誤情報、不正行為などの脅威に対する新たな経路となる可能性も踏まえ、安全性を優先するアプローチにより開発を進める方針だ。
この分野の開発動向は、OSWorldというベンチマーク/リーダーボードで確認することができる。このベンチマークは、AIモデルのパソコン操作能力を評価するテスト。2024年11月26日時点では、AnthropicのClaude 3.5 Sonnetが、2位のモデル(17.04%)に5ポイントの差をつけ、22%で首位を走る。
マイクロソフト、AI画面操作で異なるアプローチ
マイクロソフトもAIエージェントによるパソコン操作分野で取り組みを進めている。
同社は2024年10月、スクリーンショットをAIエージェントが理解しやすい形式に変換する「OmniParser」をオープンソースとして公開した。このモデルは、AI開発プラットフォームHugging Faceで最も注目を集めるモデルに急浮上。Hugging Faceの共同創業者兼CEOのクレム・デランジュ氏によると、エージェント関連のモデルとしては初の快挙になるという。
OmniParserの特徴は、3つの異なるAIモデルを組み合わせたアプローチにある。画像認識モデル「YOLOv8」がボタンやリンクなどの操作可能な要素を検出し、その座標情報を提供。次に、マルチモーダルモデル「BLIP-2」が検出された要素の目的を分析し、たとえば特定のアイコンが「送信」ボタンなのか「ナビゲーション」リンクなのかを判断する。そしてGPT-4Vが、YOLOv8とBLIP-2から得られたデータを基に、ボタンのクリックやフォームの入力といったタスクを実行する。さらに、OCR(光学文字認識)モジュールがGUI要素周辺のテキストを抽出することで、文脈理解を助けている。
https://microsoft.github.io/OmniParser/
OmniParserはオープンソースとして公開されているためGPT-4V以外にも、マイクロソフトのPhi-3.5-V、メタのLlama-3.2-Vなど、さまざまなビジョン言語モデルと連携できる柔軟性を持つ点も強みの1つとなる。
ただし、OmniParserにも課題は残されている。たとえば、同じページ内に複数存在する「送信」ボタンの区別が難しく、特に異なる目的で使用される類似のボタンの識別に苦心している状況だ。また、OCRコンポーネントにおいても、テキストが重なり合う場合の認識精度に問題があり、クリック位置の予測が不正確になることがあるという。
オープンソースという特性により、今後は多くの開発者がコンポーネントの微調整やインサイトの共有に貢献することが予想され、それに伴いモデルの能力も高まる見込みだ。
グーグルもUIに特化したビジョン言語モデルを開発
この分野では、グーグルやアップルも研究開発を進めており、この先Anthropicやマイクロソフトのようなプロダクトとしてリリースされる可能性もある。
たとえば、グーグルが2024年3月に発表した「ScreenAI」が挙げられる。これはパソコンやモバイルのユーザーインターフェース(UI)やインフォグラフィックに特化したビジョン言語モデルで、UIのボタンや入力欄の位置を把握し、クリックなどのアクションにつなげることができる。
https://research.google/blog/screenai-a-visual-language-model-for-ui-and-visually-situated-language-understanding/
グーグルによると、UIやインフォグラフィックスは、人間とコンピュータの対話において重要な役割を果たすが、その複雑さと多様な表現形式により、モデル化は困難な課題とされてきた。ScreenAIは、画像認識の基本設計としてグーグルの「PaLI」という技術を採用。さらに、画像の縦横比(アスペクト比)を崩すことなく処理できる独自の画像分析手法を取り入れることで、スマートフォンの縦長の画面からPCの横長の画面まで、様々な形状の画面に対応できるようになった。
ScreenAIは50億パラメータという比較的小規模なモデルでありながら、同規模のモデルと比較してチャート読み取り能力を測るChart QA、ドキュメント認識能力を測るDocVQA、インフォグラフィック認識能力を評価するInfographicVQAなどのベンチマークテストで高いパフォーマンスを実現。また、ウェブの構造認識能力を測るWebSRCやMoTIFなどのUIベースのタスクでも良好な結果を示したという。
ScreenAIの開発は、事前学習と微調整という2段階で進められた。第1段階の事前学習では、AIが自ら学習する「自己教師あり学習」を用いて画像認識モデル(ViT)と言語モデルの訓練データを自動的に生成。第2段階の微調整では、人間が直接確認・評価したデータを使用してモデルの精度を高める作業が実施された。
事前学習データセットの作成にあたっては、デスクトップ、モバイル、タブレットなど、様々なデバイスのスクリーンショットを収集。DETR(物体検出)モデルをベースとしたレイアウトアノテータを使用して、画像、ピクトグラム、ボタン、テキストなどのUI要素とその空間的関係を特定・ラベル付けした。また、アイコン分類器を用いて77種類のアイコンタイプを区別し、未分類のアイコンやインフォグラフィックス、画像に対してはPaLI画像キャプションモデルを使用して説明を生成したという。
ただし、グーグルは現時点でもScreenAIが大規模モデルに比べて性能面で劣ることを認めており、このギャップを埋めるためにはさらなる研究が必要だとしている。
注目されるパソコン操作の自動化という新たなフロンティア。各社の開発競争の激化は避けられなさそうだ。
文:細谷元(Livit)