
コーディングタスクでGPT-4超えるモデル続々、フランスや中国発のモデルが猛追
INDEX
Mistral、GPT-4を上回るコード生成AI「Codestral」を発表
1年ほど前に登場し、しばらく市場で最も優れたモデルとして各社のベンチマークとなっていたOpenAIのGPT-4だが、2024年に入り、このGPT-4(オリジナル版)を超えるモデルが続々登場している。特にコーディング分野では、特化型のモデルが多数登場し、コーディング関連タスクにおいて、汎用型のGPT-4を上回る性能を示している。
大規模言語モデル(LLM)のコーディング能力を測るベンチマークテストとして最も広く使用されているのが、Pythonを使ったHumanEvalというテスト。GPT-4オリジナル版は、このテストで67%というスコアだった。
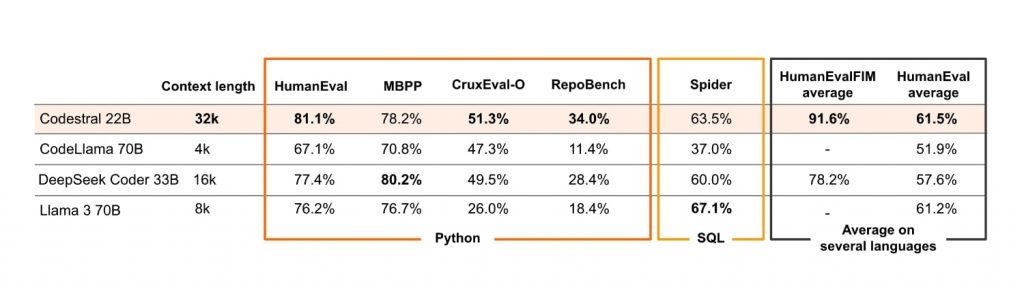
2024年5月に、フランスのMistralが発表したコード特化型モデル「Codestral」は、このGPT-4のスコアを超えるモデルの1つ。Codestralは、80以上のプログラミング言語に対応し、コード生成から補完まで幅広いタスクをこなすことができる220億パラメータのモデルだ。
特筆すべきは、HumanEvalにおける成績だ。Codestralは、このベンチマークテストにおいて81.1%のスコアを達成、GPT-4オリジナル版が記録した67%を大きく上回るパフォーマンスを示したのだ。
Codestralの特徴として、3万2,000トークンという同規模モデルの中では比較的長いコンテキストウィンドウを有する点が挙げられる。また、コード生成だけでなく、関数補完やテスト作成、部分的なコード補完などの機能も備えている。
Mistralは、Codestralの性能を示すため複数のベンチマークテスト結果を公開。たとえば、長文のPythonコード補完を評価するRepoBenchでは34%の精度を達成し、競合するオープンソースモデルを上回ったと主張している。また、Pythonの出力予測を評価するCruxEvalでも51.3%のスコアを記録し、競合の中でトップの座を獲得したと報告している。
https://mistral.ai/news/codestral/
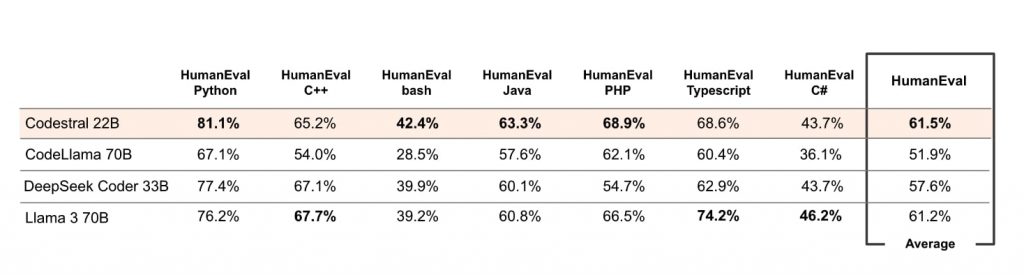
さらに、BashやJava、PHPにおけるHumanEvalテストでも競合モデルを上回る成績を示した。ただし、C++、C#、TypeScriptでは競合モデルの後塵を拝する結果に。しかし、全テストの平均スコアでは61.5%を記録、220億パラメータモデルでありながら、700億パラメータを持つLlama 3 70B(61.2%)を上回った。
https://mistral.ai/news/codestral/
Mistralは、Codestralを非商用ライセンスの下Hugging Faceで公開している。開発者は非商用、テスト、研究目的でこのモデルを利用することが可能だ。
中国発、GPT-4を上回るオープンソースモデル「DeepSeek Coder V2」
中国のDeepSeekが2024年6月に発表した「DeepSeek Coder V2」もコーディング分野で高い性能を示すモデルだ。このモデルは、同社が前月に発表したDeepSeek V2をベースに構築されており、コーディングと数学の両分野に特化してファインチューニングしたモデルとなる。
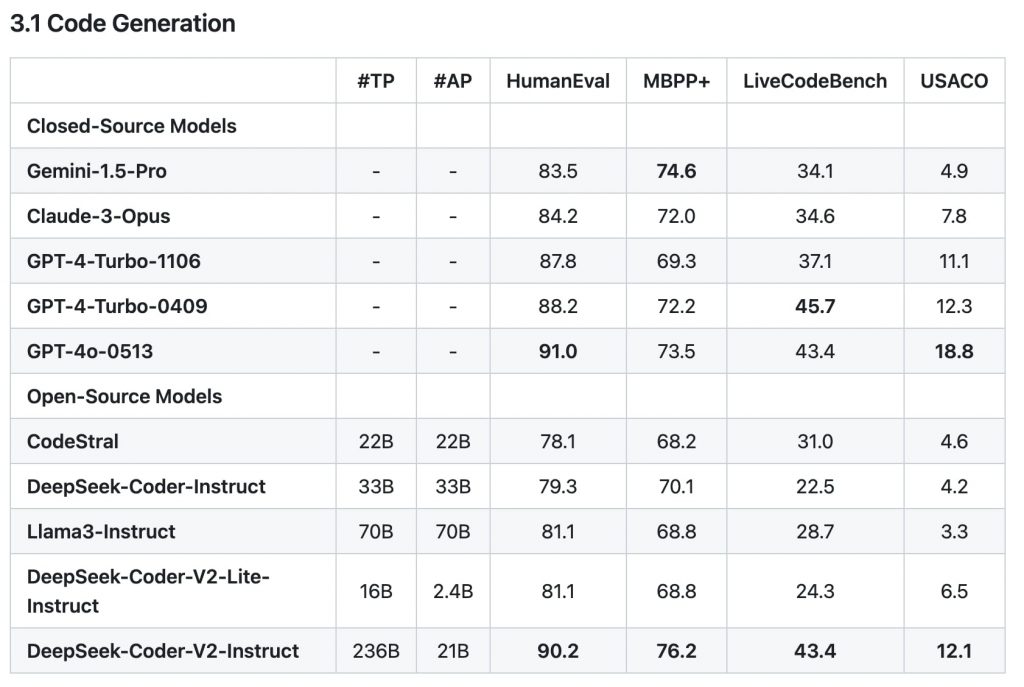
DeepSeek Coder V2が対応できる言語は300以上に上り、性能面では、GPT-4 Turbo、Claude 3 Opus、Gemini 1.5 Proといった主要クローズドソースモデルを上回るという。同社によると、DeepSeek Coder V2のコンテキストウィンドウは、上記Codestralを大きく上回る12万8,000トークン。より複雑で広範囲のコーディングタスクに対応できるほか、一般推論や言語理解の能力も高いとのこと。
コーディング能力を測るHumanEvalでは、90.2%を獲得。これは、GPT-4 Turbo(88%)、Gemini-1.5 Pro(83.5%)、Claude3 Opus(84.2%)などの主要クローズドソースモデルを超える数値だ。
このほかにも、コード生成能力を測るMBPP+、コード修正能力を測るAiderなどのテストでもGPT-4の最新版である「GPT-4o」をも超える性能を示している。
https://github.com/deepseek-ai/DeepSeek-Coder-V2
またDeepSeek Coder V2は、数学分野のベンチマークテストでも高いパフォーマンスを示している。比較的難度が高い数学問題を解くMATHテストでは、75.7%を獲得した。この時点ではGPT-4o(76.6%)に次ぐ2番目となり、大健闘したスコアといえる。
DeepSeek Coder V2のベースとなる汎用モデルDeepSeek V2は、Mixture of Experts(MoE)フレームワークに基づくモデル。DeepSeek Coder V2も、この(MoE)フレームワークを継承しており、今回高いスコアを記録できた要因の1つとされる。もう1つは、データの質と量にある。DeepSeekは、GitHubやCommonCrawlから収集したコードや数学関連のデータを中心とする6兆トークンの追加データセットで、ベースとなるV2モデルをトレーニングしたという。
DeepSeek Coder V2は現在、研究目的および無制限の商用利用を許可するMITライセンスの下で提供されている。ユーザーは、Hugging Faceを通じて160億および2,360億パラメータサイズのモデルをインストラクト版とベース版でダウンロードできる。
クローズドソース汎用モデルも、コーディングで飛躍的向上
オープンソースモデルの急速な進化がある中、OpenAIやAnthropicなどが提供するクローズドソース型の汎用モデルも、コーディング能力において大幅な改善を見せている。
Vellumが公開したHumanEvalコーディングリーダーボードでは、GPT-4oが90.2%でトップに立つ。これに続くのがGPT-4 Turboで87.1%、Claude 3 Opusが84.90%となっている。GPT-4オリジナル版の67%から、大きく飛躍している様子がうかがえる。ただし、このリーダーボードには、GPT-4oよりも新しいAnthropicのClaude3.5 Sonnetが含まれていない点に留意する必要がある。
HumanEvalではなく、より包括的かつ新しい方法でLLMを評価するベンチマークが続々登場しており、LLMを選ぶ際に重宝する存在となっている。
LiveBenchは、そのような新しい評価視点を提供する新規ベンチマークの1つ。LiveBenchの最新版(2024年6月25日)リーダーボードでは、Anthropicの最新モデルClaude3.5 Sonnetが総合スコア61.16でダントツの1位を獲得。2位のGPT-4o(54.96)、3位のGPT-4 Turbo(53)を大きく引き離す実力を見せているのだ。
Claude3.5 Sonnetが特に際立っているのがコーディング分野。スコアは63.21と、2位のGPT-4 Turbo(47.05)や3位のGPT-4o(46.37)を10ポイント以上引き離している。
LiveBenchでは、従来のベンチマークの問題である「データ汚染」の影響を排除する仕組みが導入されており、より正確にLLMの性能を測ることができるとされる。ここで言うデータ汚染とは、テスト問題がLLMのトレーニングデータセットに含まれる問題を指す。テスト情報がトレーニングデータに含まれると、そのテストでは良いパフォーマンスを発揮できるが、初めてみる質問/問題には対応できないという現象が発生するのだ。
HumanEvalは、長年広く使われてきたベンチマークテストであるため、その情報がトレーニングデータに含まれる可能性が高い。このためHumanEvalでは高いスコアが出やすいといわれている。
実際、上記のHumanEvalでGPT-4の各モデルを超える性能を示したDeepSeek Coder V2は、LiveBenchのコーディングテストではスコア41.05と、Claude3.5 Sonnetだけでなく、GPT-4 Turbo(47.05)やGPT-4o(46.37)にも及ばないことが明らかになった。
コーディング能力を見る際の注意点、新たな評価手法「LiveCodeBench」
LiveBenchと同じ問題意識のもと、コーディングに特化して開発されたのがLiveCodeBenchだ。
LiveCodeBenchのコード生成リーダーボードで現在1位となっているのは、Claude3.5 Sonnet。スコアは54.8%。これは1回目の試みで、コーディング問題を解けた割合が平均54.8%だったということ。2位はGPT-4oで45.6%、3位はGPT-4 Turboで44.7%、4位はDeepSeek Coder V2で42.8%だった。
興味深いのは、LiveCodeBenchを用いた評価により、以下のような傾向が観察されたことだ。
まず、データ汚染の可能性を示唆する傾向が挙げられる。DeepSeek、GPT-4o、Codestralといったモデルが、特定の日付以降に公開された問題で急激な性能低下を示すことが観察されたのだ。トレーニングデータに過去問題が含まれていることを示唆する挙動であり、データ汚染が疑われている。
これに関連して、HumanEvalへの過学習問題も観察されたという。LiveCodeBench開発チームの分析によると、一部のモデル、特にファインチューニングされたオープンソースモデルが、HumanEvalでは高いパフォーマンスを示すものの、LiveCodeBenchではそれほど良い成績を残せないことが明らかになった。これは、一部のモデルがHumanEvalにオーバーフィットしている可能性を示唆するもの。HumanEvalでは、LLMのコーディング能力を正確に測ることが困難になりつつある。
LiveCodeBenchの登場により、コード生成AIの評価方法に新たな視点が加わった。今後、この包括的な評価アプローチがどのように発展し、AI開発にどのような影響を与えていくか、注目が集まるところだ。
文:細谷元(Livit)