
NTT、独自の大規模言語モデル「tsuzumi」開発 軽量かつ日本語処理が得意なLLM 商用サービスとして2024年3月より提供開始へ
日本電信電話(以下、NTT)は、大規模言語モデル(LLM)の普及に伴い課題となっている電力やコスト増加などの課題解決に向け、軽量でトップレベルの日本語処理性能を持つ大規模言語モデル「tsuzumi」を活用したNTTグループ発の商用サービスを、2024年3月に提供開始すると発表した。
なお「tsuzumi」は、2023年11月14日~17日に開催する「NTT R&D FORUM 2023 ― IOWN ACCELERATION」のIOWN Pickupの展示ブースでも見ることができ、同フォーラム内の基調講演・特別セッションにおいても具体的な取り組み・展望などを紹介するとのことだ。
■「tsuzumi」の特長
(1)軽量なLLM
・パラメタサイズが6億の超軽量版と70億の軽量版の「tsuzumi」を開発。
・Open AI社のGPT-3の1750億パラメタと比べ、およそ約300分の1(超軽量版)および25分の1(軽量版)と軽量。
・軽量版は1GPUで、超軽量版はCPUで高速に推論動作可能であり、チューニングや推論に必要なコストを抑えることが可能。

GPUクラウドの利用料金に換算すると、学習コストを約300分の1(超軽量版)および25分の1(軽量版)、推論コストを約70分の1(超軽量版)および20分の1(軽量版)に低減可能。
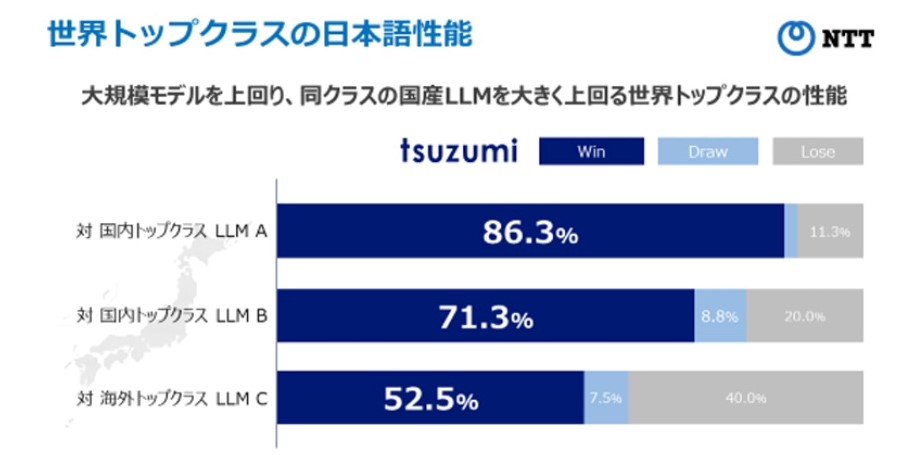
(2)日本語と英語に対応~特に日本語が得意なLLM~
「tsuzumi」は日本語と英語に対応しており、特に日本語処理性能については長年の研究で得た知見を活かすことで、高い性能を具備。生成AI向けのベンチマークであるRakudaではGPT-3.5や国産トップのLLM群を上回ることを確認。英語でも、世界トップクラスと同程度の性能を実現しており、多言語にも今後対応。
(3)柔軟なチューニング~基盤モデル+アダプタ~
効率的に知識を学習させることのできるアダプタにより、例えば特定の業界に特有の言語表現や知識に対応するようなチューニングを、少ない追加学習量で実現可能。
(4)マルチモーダル~言語+視覚・聴覚・ユーザ状況理解~
言語化されていないグラフィカルな表示や音声のニュアンス、顔の表情などを理解し、現実世界での人との協調作業を可能とするような、マルチモーダルへの対応を予定。
NTTは「tsuzumi」が志向する方向性について、まずは業界に固有なデータを柔軟・セキュアに学習することが可能となる点を生かし、業界に特化した領域にフォーカスしていくとしている。
全ての知識を集約した1つの巨大なLLMが存在するのではなく、専門性や個性をもった小さなLLMの集合知が多種多様なAI群と連携してリアルワールドの社会課題を解決する世界を目指すとのことだ。
なお、NTTは今後、商用サービス提供後もチューニング機能の充実やマルチモーダルの実装についても順次展開を予定。また、サイバーセキュリティ分野への応用、自律的に連携し議論するAIコンステレーション等の開発を進めていくとのことだ。