
「点取りゲーム」に終止符? 本当に使えるAIを見極める4つの評価基準
INDEX
「忖度なし」独立系評価の決定版、Artificial Analysisの独立性
AIモデルの性能を測る指標は数多く存在するが、その評価が本当に信頼できるかどうかは別問題だ。開発元の企業が自社モデルの優位性を強調するベンチマーク結果を発表することは珍しくない。そこで注目されているのが、AI開発会社とは一切関係を持たない第三者機関による評価である。
その代表格がArtificial Analysisだ。その公開ウェブサイトは、エヌビディア、メタ、Mistral AI、TechCrunch、ウォール・ストリート・ジャーナル、OECDなど、AI革新をリードする企業や報道機関によって広く参照されている実績を持つ。
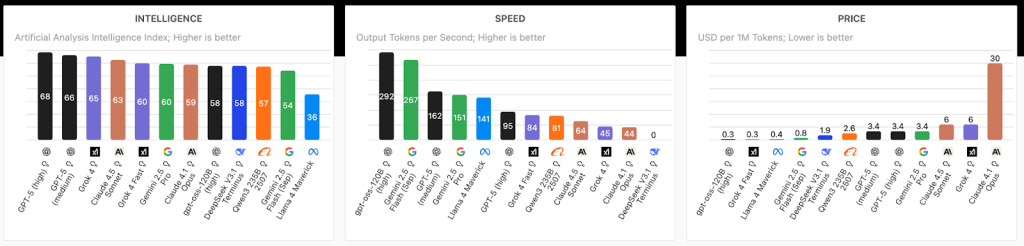
Artificial Analysisの特徴は、単一の指標ではなく、速度、精度、コスト効率を同時に評価する包括的なアプローチにある。言語モデルAPIに対して1日8回、約3時間ごとにパフォーマンステストを実施。100トークンから10万トークンまで、さまざまなワークロードを想定したテストを行っている。測定結果は過去72時間の中央値で示されるため、一時的な性能変動に左右されず、持続的なパフォーマンスを把握できる仕組みだ。
評価指標も多岐にわたる。最初のトークンが返ってくるまでの時間(Time to First Token)、1秒あたりの出力トークン数(Output Speed)、100トークン生成にかかる総時間(Total Response Time)など、実際のビジネス利用を想定した測定項目が設定されている。こうした厳密な測定方法により、企業は自社のユースケースに最適なAIモデルを客観的に選択することが可能となった。
https://artificialanalysis.ai/
とりわけ、スピードとコストの2要素を直感的に把握できる点は特筆に値する。AIアプリ開発では、ユーザー体験(スピード)とコスト・利益率のバランス問題が常に付きまとう。Artificial Analysisのインサイトを活用することで、効率的に、スピードとコストを考慮した最適なAIモデルの選択が可能になる。AIモデルの性能、スピード、コストを一目で把握した場合、Artificial Analysisが示すデータは非常に有用と言えるだろう。
100万人が選んだ「本当に使えるAI」ランキング
独立系の評価機関が客観性を担保する一方で、実際にAIを使う人々の声を集めた評価も重要な役割を果たしている。その代表格が、カリフォルニア大学バークレー校の博士課程学生だったアナスタシオス・アンジェロプロス氏とウェイリン・チアン氏が2023年に立ち上げたChatbot Arena、現在のLMArenaだ。
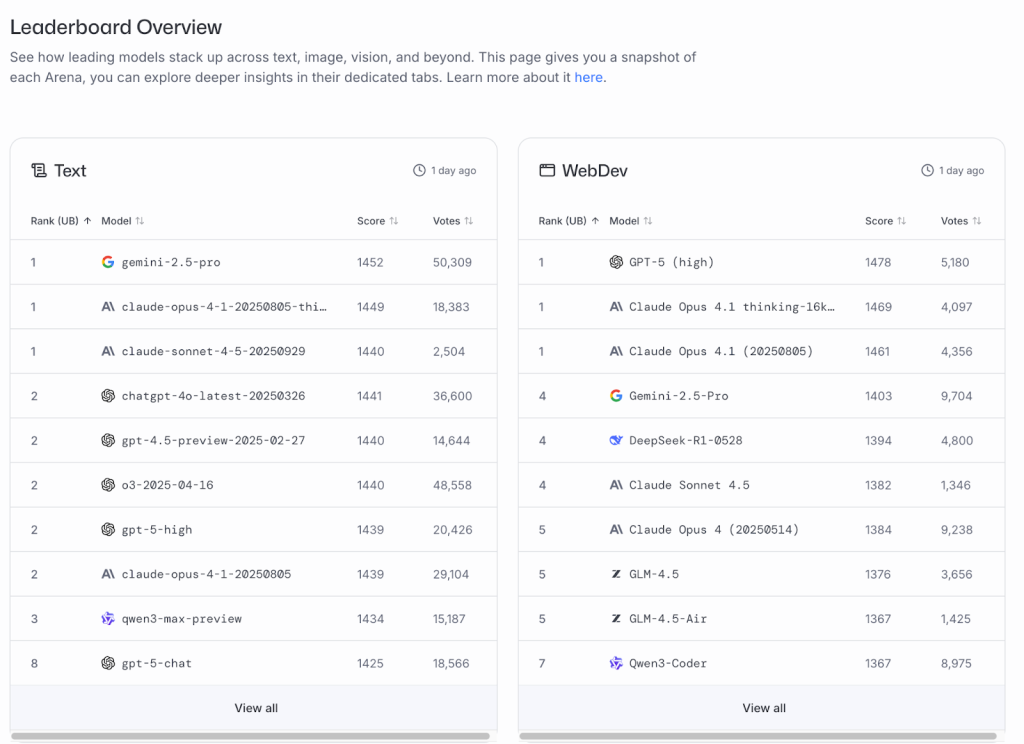
この仕組みはシンプルだが効果的である。ユーザーが質問を入力すると、2つの匿名化されたAIモデルがそれぞれ回答を生成。ユーザーは優れた回答を選び、投票後に初めてモデルの正体が明かされる。この盲検方式により、ブランドイメージに左右されない純粋な評価が可能になった。
https://lmarena.ai/leaderboard
集まった投票データは、統計モデルのブラッドリー・テリーを使ってEloレーティングに変換される。チェスのレーティングシステムと同様の仕組みだ。2025年4月時点で300万以上の対決が記録され、400を超えるモデルが評価された。月間のユニークユーザー数は平均100万人を超え、100以上の言語で利用されている。
この規模と透明性が、業界での信頼獲得につながった。数百万を超えるAI評価が実施されたことを受け、ウォール・ストリート・ジャーナルは「AI業界が熱中するもの」と表現。テック企業の幹部やエンジニアがウォール街のトレーダーが市場を見るようにLMArenaを注視していると報じた。実際、グーグル、OpenAI、xAIといった大手企業は、一般公開前のモデルをこのプラットフォームでテストしているとされている。
中国のAI企業DeepSeekが2025年1月にApp Storeのトップに躍り出て業界を驚かせたとき、Arena利用者はすでに数カ月前からDeepSeekモデルのランキング上昇を目撃していたという逸話もある。
LMArenaは、「ユーザー視点で、どのAIモデルが評価されているのか」を知りたい場合の第一選択肢になるはずだ。
ただし、ユーザー投票による評価にも限界はある。次のセクションでは、実際のアプリケーション環境での評価という、さらに実践的なアプローチを見ていく。
実験室を飛び出した「現場主義」評価法
専用サイトでの評価が普及する中、さらに実践的なアプローチを追求する動きも出てきた。アリババ系列のInclusion AIが提案するInclusion Arenaは、実際に稼働しているアプリケーション内でAIモデルを評価する仕組みだ。
従来のベンチマークは、静的なデータセットやテスト環境でモデルの能力を測定してきた。LMArenaのような専用サイトも、ユーザーが意識的にモデル評価のために訪れる場所であるため、ある種のバイアスがかかっている可能性も否定できない。一方、Inclusion Arenaは、人々が日常的に使うアプリの中にモデル対決を組み込むことで、より自然な使用状況での性能を把握しようとする試みだ。
具体的には、キャラクターチャットアプリのJoylandと教育コミュニケーションアプリのT-Boxという2つのアプリに評価システムを統合。ユーザーが普段通りアプリを使っている最中、入力された質問に対して複数のAIモデルが裏側で回答を生成する。ユーザーは提示された回答の中から好みのものを選ぶが、どのモデルが生成したかは知らされない。
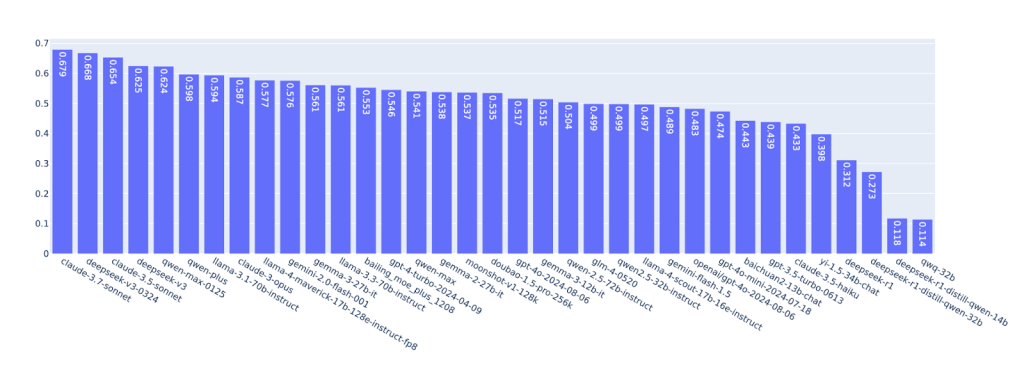
2025年7月までに、4万6,611人のアクティブユーザーから50万1,003件のペア比較が集まった。この規模は、実際のアプリケーション環境での評価としては画期的といえる。ランキング計算にはLMArenaと同様のブラッドリー・テリー法が採用されており、統計的に安定した評価を実現している。
https://arxiv.org/pdf/2508.11452
初期実験の結果、最も高い評価を得たのはClaude 3.7 Sonnet、DeepSeek v3-0324、Claude 3.5 Sonnet、DeepSeek v3、Qwen Max-0125といったモデルだった。
研究チームは現時点での統合アプリが限定的であることを認めており、オープンアライアンスを構築してエコシステムを拡大する計画だという。
開発現場の実力を測る「SWE-bench」の実践性
実用性を重視する流れは、コーディング分野で特に顕著だ。その代表格がSWE-benchである。このベンチマークは、実際のソフトウェア開発現場で発生した問題をAIがどれだけ解決できるかを測定する。
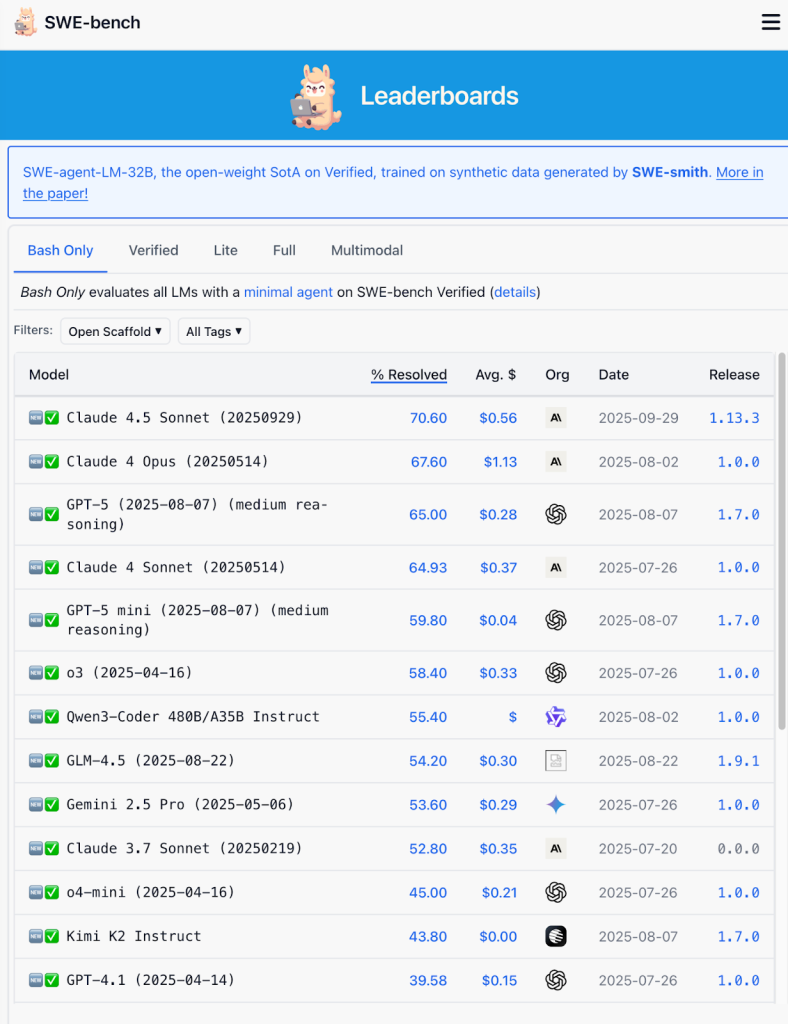
SWE-benchの特徴は、12の人気Pythonリポジトリから採取した実際のissueとpull requestを使うことにある。従来のDefects4Jのような既存ベンチマークは、問題を特定するためのテストケースが事前に用意されていた。しかしSWE-benchは、開発者が実際に直面する状況、つまりテストケースがない状態での問題解決能力を評価する設計となっている。
評価指標は「% Resolved」、つまり解決できた問題の割合だ。フルセットには2,294のインスタンスが含まれ、精度を高めたVerified版では500インスタンス、コスト効率を考慮したLite版では300インスタンスが用意されている。2025年9月時点のリーダーボードでは、Claude 4.5 Sonnetが70.60%で首位に立ち、Claude 4 Opusが67.60%、GPT-5が65.00%と続く。
https://www.swebench.com/
このベンチマークは2023年10月の開始以来、学術機関だけでなく、アマゾン、IBM、グーグルといった大手企業から小規模スタートアップ、さらには個人開発者まで、多様な参加者を集めてきた。
プリンストン大学の研究者が開発したSWE-agentのように、LLMをソフトウェアエンジニアリングエージェントに変換するツールも登場。こうした実践的な評価環境が、AIコーディング支援ツールの進化を加速させている。
結局のところ、AIモデルを選ぶときは、単一の評価方法だけに頼るのではなく、独立系の客観評価、ユーザー投票、実アプリでの性能、そして用途に特化したベンチマークなどを組み合わせて多面的に判断することが重要だ。
文:細谷 元(Livit)