
生成AIで文書のデジタル化が進化、MistralがLLMで実現する99%超の精度
INDEX
LLMで進化するOCR技術の最前線
文書のデジタル化技術であるOCR(光学文字認識)の歴史は長く、これまで多くの改善が続けられてきた。この取り組みにより、従来型のOCRであっても、印刷された文字に対して95~98%の認識精度を達成している。しかし、手書き文字や複雑なレイアウトへの対応には課題を残していた。
この状況は大きく変わりつつある。LLM(大規模言語モデル)との融合により、OCR技術は新たな段階に入ったのだ。2025年第1四半期には、LLMを活用したOCRシステムが標準的な文書で99.56%という高精度を記録。従来のOCRが苦手としていた低品質画像でも、20~30%の精度向上を実現したとされる。
最近の動向で特に注目されるのが、多言語対応能力の向上だ。PaddleOCRに代表される新世代OCRツールは、80以上の言語に対応。複雑な文字体系でも高い認識率を発揮する。手書き文字の認識精度も向上し、従来型OCRの平均64%から、クリアな文字であれば80~85%まで改善されたという。
コスト面でも革新が進んでいる。グーグルのGemini 2.0 Flashは、6,000ページの処理を1ドルで実現。大規模な文書デジタル化プロジェクトの経済的障壁を大きく下げる可能性を示している。
一方で、課題も存在する。LLMを活用したOCRは従来型と比べて処理速度が2~3倍遅く、プライバシーの懸念やデータの誤認識(ハルシネーション)といった問題も指摘されている。また、元の文書のレイアウトが保持されにくいという特徴もある。
しかし、業界での活用事例を見ると、これらの課題を上回るメリットが確認されている。ある大手金融機関では、LLM搭載OCRの導入により、処理速度が80%向上し、データ入力エラーは95%減少したと報告されている。さらに、メール処理の効率は60%改善され、全体的な業務効率は25%向上した。
新たな技術フレームワークの開発も進む。文書の前処理から後処理までを一貫して最適化するKnowledge-Aware Preprocessing(KAP)は、特に非定型文書の処理精度を大幅に向上させており、その開発動向に注目が集まっている。
Mistral OCR、その全容
AI企業によるLLMを活用したOCRの改善取り組みも進んでいる。
たとえば、フランスのAIスタートアップMistralが発表したMistral OCR。手書きメモや活字テキスト、画像、表、数式など、PDFや画像から多様なコンテンツを高精度で抽出し、構造化されたフォーマットで提供できる能力を持つ。
Mistralの最高科学責任者であるギヨーム・ランプル氏は、この技術が企業におけるAI導入の重要なステップになると指摘する。すでに数百万人のユーザーが利用する同社のチャットアプリ「Le Chat」に統合され、開発者向けプラットフォーム「la Plateforme」でも提供されている。また、高度なセキュリティ要件を持つ組織向けにはオンプレミス展開のオプションもある。
価格面では、1ドルあたり1,000ページの処理が可能。バッチ処理を利用すれば、同じ1ドルで2,000ページまで処理できる。サービスの試用は、同社のチャットボットLe Chatで無料で可能だ。
従来型のOCRと異なり、Mistral OCRはLLMと組み合わせることで、文書の”理解”も可能にする。文書の内容に関する質疑応答や、情報の自動抽出、要約作成、複数文書の比較分析、文脈を考慮した応答など、高度な処理を実現した。
この背景には、企業の文書処理における課題がある。企業情報の85〜90%が非構造化データとされ、その活用が大きな課題となっている。非構造化データとは、メールやソーシャルメディア投稿、動画、画像、音声ファイルなど、特定のフォーマットや構造を持たないデータを指す。従来のデータベースでは適切に扱えないため、自然言語処理や機械学習などの特殊な技術が必要とされてきた。
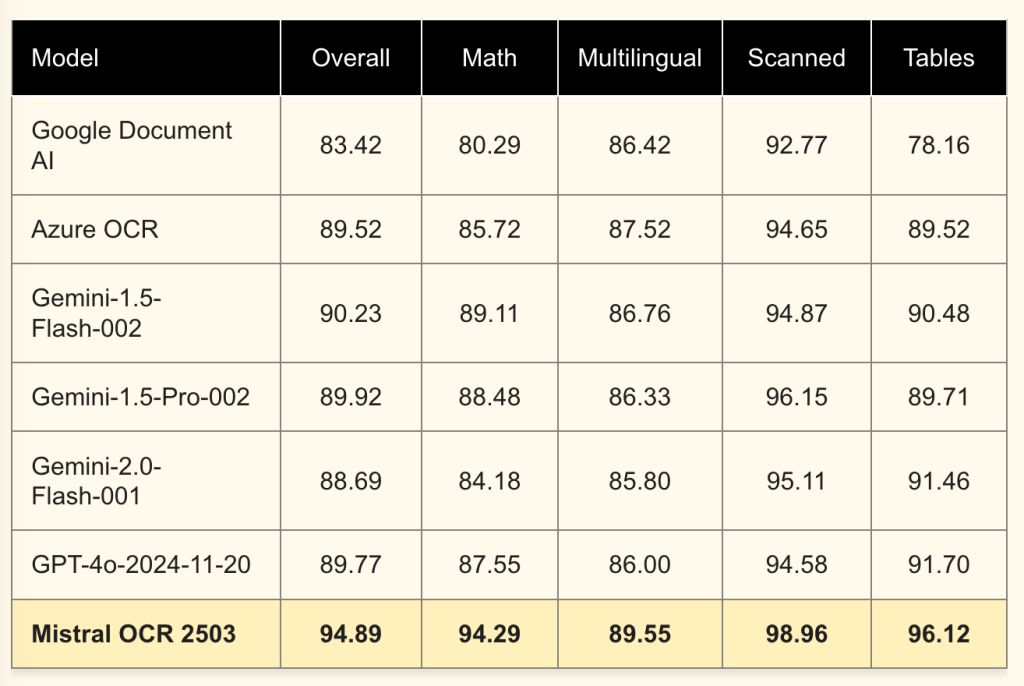
Mistral OCRは、こうした課題に対して、マルチモーダル処理と高速な処理能力で応える。1ノードで毎分2,000ページまでの処理が可能な高速性を実現し、ベンチマークテストでは、グーグルのDocument AI、AzureのOCR、OpenAIのGPT-4oなど、主要な競合モデルを上回る精度を達成している。特に数式認識、スキャン文書、多言語テキスト処理において高いスコアを記録した。
企業での活用シーンと実用性
企業向けAIサービスにおいて、導入のハードルとなるのが運用面での課題だ。Mistral OCRは、これらの課題に対して実用的な解決策を示す。
その特徴の一つが、ドキュメント階層構造の保持機能である。基本的なOCRモデルと異なり、ヘッダー・段落・リスト・表などの書式要素を維持したまま、テキストを抽出することができる。これにより、後工程でのデータ活用は大幅に容易となる。また、JSONやマークダウンなど、構造化された出力形式に対応し、他のAIワークフローとの統合も可能だ。
セキュリティ面では、オンプレミス導入オプションを提供。機密性の高いデータや規制要件の厳しい業界でも、内部インフラを活用しながらAIによる文書処理が可能になる。
実際の活用シーンは多岐にわたる。たとえば、金融・医療・法務・コンプライアンス分野では、大量の文書処理作業が業務のボトルネックとなっている。Mistral OCRを導入することで、管理業務の負担を軽減し、運用効率を高められる。また、コンテンツ管理プラットフォームやCRMソフトウェア、法務テックソリューション、AI駆動型アシスタントなど、既存の企業システムとの統合も容易にできる。
LLMによるOCR処理には、従来にない柔軟性も備わる。サプライヤーごとに異なる請求書レイアウトでも、追加の設定や事前定義のテンプレートなしで、重要なデータを抽出できる。また、単純な文字認識の誤り(「1」と「O」の混同による「10」と「1O」の誤認識など)も、文脈理解により防止。手書きメモや低品質画像からの情報抽出にも効果を発揮する。
ただし、留意点もある。2023年の分析によると、チャットボットの場合、約27%の確率でハルシネーションが発生し、生成されたテキストの46%に事実誤認が含まれていたという。特に、高精度が求められる業界では、LLMのみに依存することはリスクとなる可能性がある。
このため、低容量の文書処理や、出力の検証が容易で単純な自動化には適しているものの、正確性が求められる文書や、大容量の文書処理、完全自動化されたワークフローには、追加の検証プロセスやエラー検出の仕組みを組み込むことが推奨されている。
文:細谷元(Livit)