
DeepSeek R1が示すAI開発の新潮流 低コストで実現したOpenAI o1級の性能、その実態を探る
INDEX
DeepSeek R1とは、OpenAIの主要モデルを圧倒的低コストで開発か?
AI市場は、中国発のDeepSeekが大きな話題となっている。
その発端となったのが、同社が2024年12月に発表した「DeepSeek R1」モデルだ。OpenAIのo1モデルと同等の性能を持ちながら、開発コストはo1の3〜5%程度に抑えたとされる。これにより、AI開発におけるGPUの必要性が最高されることとなり、NVIDIAの株価下落にも影響を及ぼした可能性がある。
DeepSeekは、中国の投資ファンドHigh-Flyer Quantから2023年にスピンオフした企業。同社は独自のチャットボット開発を進める過程で、社内向けAIモデルを開発。その後、それらをオープンソース化する戦略を取った。技術的な土台としては、メタの公開モデル「Llama」や機械学習ライブラリ「Pytorch」などを活用していたとされる。
コスト削減の鍵は、大規模なGPU調達と効率的な運用戦略にある。DeepSeekは、米国の輸出規制が本格化する前に、NVIDIAのGPUを10,000台以上確保。その後、代替ルートを通じて50,000台規模まで拡大したといわれている。
しかし、開発コストの詳細は依然として不透明な部分が多い。NVIDIAのエンジニア、ジム・ファン氏によると、DeepSeekはベースモデル「V3」を558万ドルのコストで2カ月かけて開発したという。ただし、これは公表された一部の情報に過ぎず、50,000台規模のGPUを稼働させると仮定すれば、実際の開発費用は数億〜十数億ドル規模に達する可能性が指摘されている。
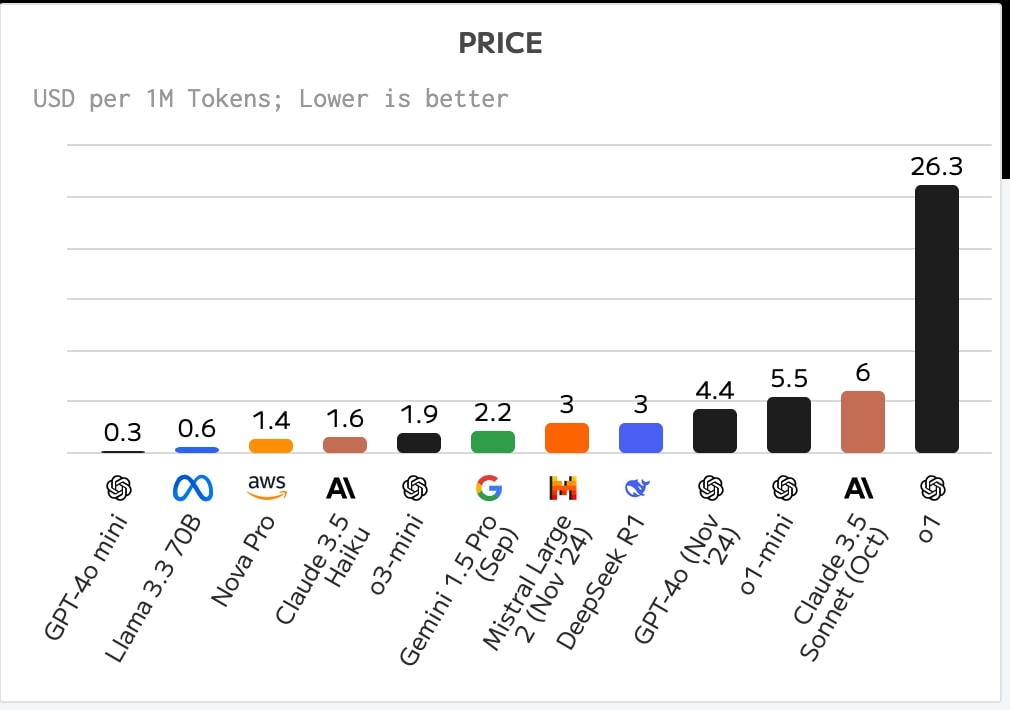
そして2025年1月末、この競争はOpenAIが「o3-mini」をリリースしたことで新たな段階に突入する。o3-miniのAPIの利用料金は100万トークンあたり入力1.1ドル、出力4.4ドルに設定され、o1と比べて実に93%のコスト削減を実現。さらに1秒あたり184トークンという圧倒的な処理速度を記録し、実質的に現時点の主要モデルの中では最高性能かつ、最速スピードを持つモデルとなり、DeepSeekを引き離す格好となった。
DeepSeek R1、数学とコーディングで高い能力を発揮
DeepSeek R1の最大の特徴は、従来のAIモデル開発手法を大きく覆す独自のアプローチにある。同社は「DeepSeek V3」をベースモデルとしつつ、教師あり学習(SFT)を最小限に抑え、強化学習(RL)を中心とした開発手法を採用した。
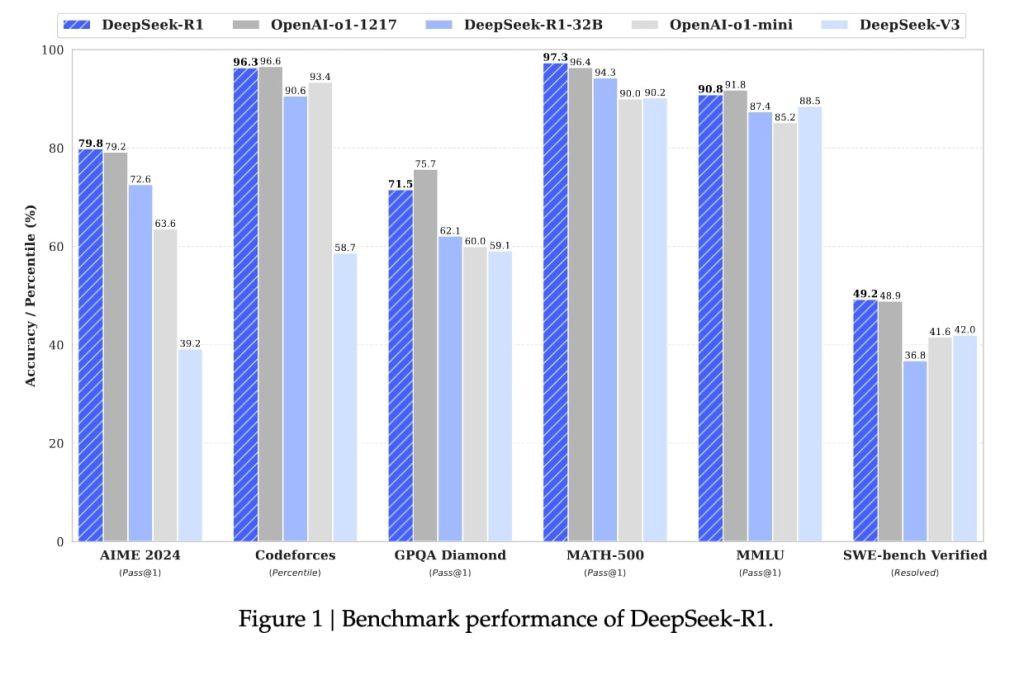
この取り組みの成果は、数々のベンチマークテストで証明されている。数学オリンピック予選を兼ねた米国のテスト「AIME」(2024年版)では79.8%、別の数学テストMATH-500では97.3%というスコアを達成。また、プログラミング競技プラットフォーム「Codeforces」では、人間のプログラマーの96.3%を上回る成績を記録した。これらの数値は、OpenAIのo1モデルと同等、もしくはそれを上回るものとなる。
https://huggingface.co/deepseek-ai/DeepSeek-R1
開発の過程では、まず「DeepSeek R1-Zero」と呼ばれる、強化学習のみで訓練されたモデルを開発。これは、教師データを使わずに、試行錯誤を通じて自己進化する能力を獲得したモデルだ。研究者らによると、数千回の強化学習を経て、AIMEテストの正答率は15.6%から71.0%まで向上。さらに多数決による判定を導入することで、86.7%という高スコアを達成したという。
しかし、R1-Zeroには可読性の低さや言語の混在といった課題も存在した。そこで同社は、少量の教師データによる事前学習と強化学習を組み合わせる手法を採用。これにより、DeepSeek R1は最終的にOpenAIのo1-1217と同等の性能を実現することに成功した。
その後、DeepSeekはR1の技術を活用し、より小規模なモデルの開発も進めている。たとえば、「Qwen」モデルをベースに開発された1.5B、7B、14B、32Bのモデルや、「Llama」をベースにした8B、70Bのモデルなど、様々なサイズのモデルを公開。特に「DeepSeek R1-Distill-Qwen-32B」は、OpenAIのo1-miniを上回る性能を発揮したことが報告されている。
Artificial Analysisのまとめによると、DeepSeek R1のAPI利用料(入力・出力混合)は、100万トークンあたり1ドルと、o3-miniの1.9ドル、Claude 3.5 Sonnetの6ドルと比較すると、非常に魅力的な価格設定となっている。この価格競争力を武器に、どこまでシェアを伸ばせるのかが注目される。
https://artificialanalysis.ai/
DeepSeek R1の実際の評価、この1カ月で見えてきた課題
AI市場に衝撃を与えたDeepSeek R1だが、実際の運用では新たな課題も浮上している。
最大の懸念は、セキュリティ面での脆弱性だ。コスト面での優位性は確かなものの、そのトレードオフとして、深刻なリスクを抱えているのだ。
たとえば、DeepSeek R1は50回のジェイルブレイク(システムの制限を回避する攻撃)試行すべてに対して脆弱性を示したことが、セキュリティ研究者らによって報告されている。これは企業での実導入を検討する上で、大きな障壁となる可能性が高い。
一方、OpenAIは新モデル「o3-mini」で「deliberative alignment(熟考的整合)」と呼ばれる新たな安全対策を導入。これは、モデルが安全性のガイドラインを理解・分析した上で適切な回答を生成する仕組みだ。結果として、ジェイルブレイクへの耐性が大幅に向上したとされる。
AnthropicもまたAIの安全性向上に注力している。同社が最近発表した人間の価値観に基づいたAIシステムの行動原則をモデルに組み込む「constitutional classifiers」は、同社のモデル「Claude 3.5 Sonnet」へのジェイルブレイク試行の95%以上を防御することに成功している。
さらに、実際の運用面でもDeepSeek R1には課題が残る。処理速度は1秒あたり19トークンと、主要モデルの中で最も遅い。これに対しo3-miniは1秒あたり184トークンという圧倒的な速さを誇る。また、AnthropicのClaude 3.5 SonnetもCursorなどのコーディングプラットフォームとの統合が深化しており、開発現場では依然として強い人気を維持している状況だ。DeepSeek R1のユースケース特定にはしばらく時間がかかるものと思われる。
全体としてDeepSeek R1は、コスト面での革新は評価できるものの、企業の文脈においては、依然としてOpenAIやAnthropicが提供する、安全で高速なモデルが優位な選択肢となりそうだ。
文:細谷元(Livit)