
DeepSeek R1モデルを超えるOpenAIの最新モデル「o3-mini」、その驚異的な実力
INDEX
OpenAIの切り札「o3-mini」とは?
2025年1月末、OpenAIが新たな推論モデル「o3-mini」を正式リリースした。o3モデルは実質的に、「o1」モデルの後継モデル。同じ名前の通信企業「o2」との著作権問題を避けるために、この名称が採用された。
同社は昨年12月の段階で、o3とo3-miniの2つのモデルを発表していた。このうち低コストで利用できるo3-miniを先行リリースすることで、グーグルやDeepSeekなどの競合の存在感が高まる推論モデル市場で、優位性を維持するのが狙いとみられる。o3-miniには、3つの推論モード(low、medium、high)が用意されており、ChatGPT上では、mediumとhighが選択できるようになった。
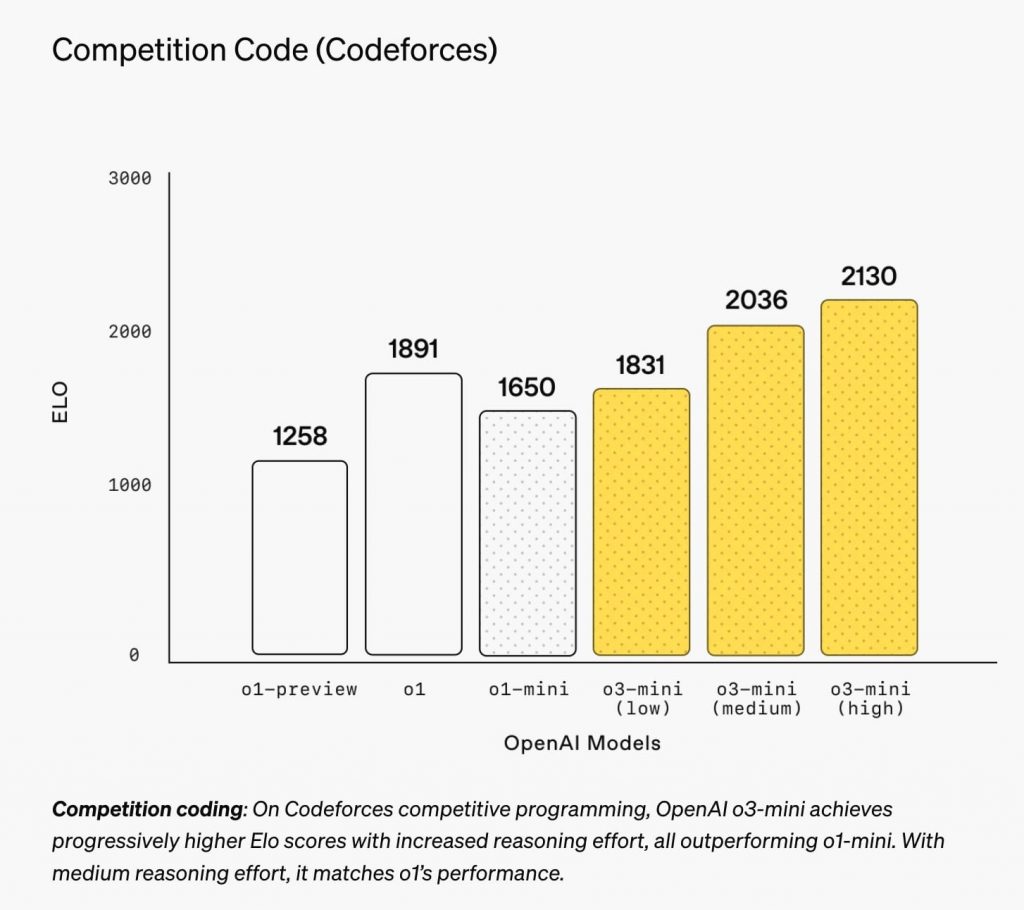
o3-miniは、企業におけるユースケースが最も多いコーディング分野で高いパフォーマンスを示す。プログラミング競争プラットフォーム「Codeforces」のタスクでは、o1(1,891ポイント)を大きく上回る2,130という驚異的なスコアを達成。また、ソフトウェアエンジニアリング能力を測る「SWE-Bench Verified」でもo1を上回る結果を示した。
https://openai.com/index/openai-o3-mini/
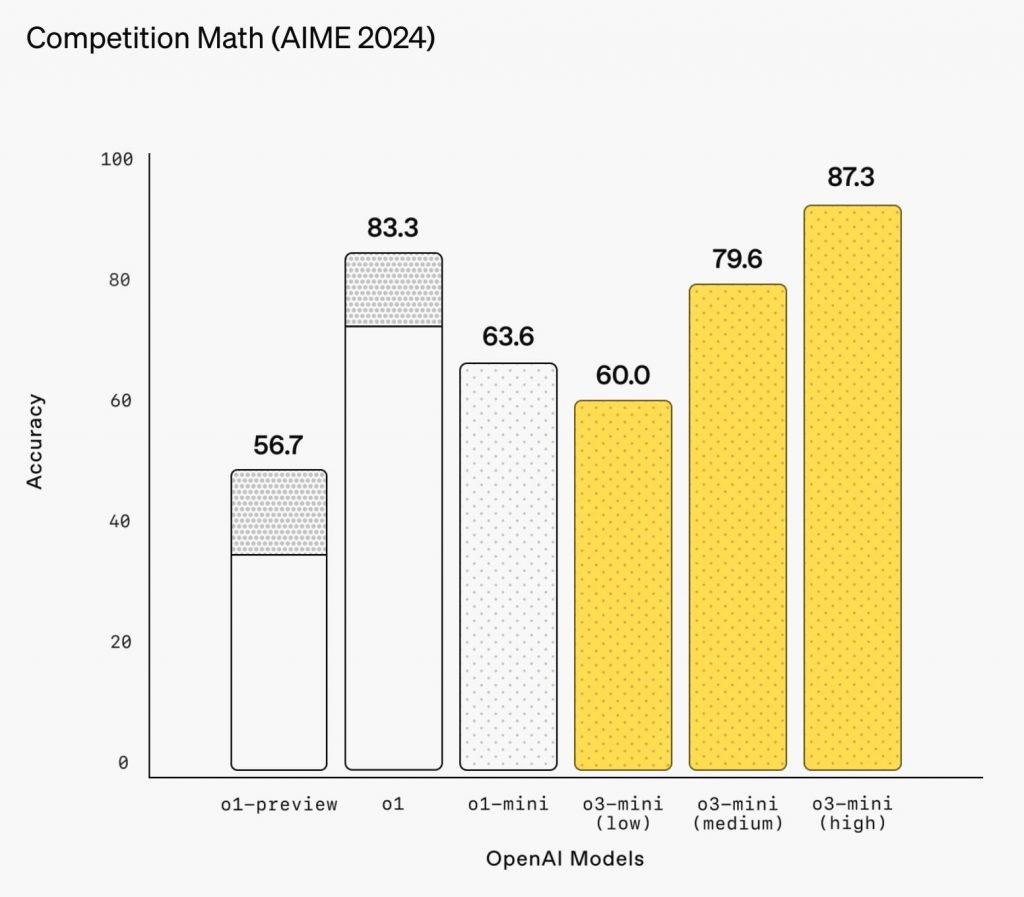
数学分野でも圧倒的な強さを見せつける。米国数学オリンピック予選を兼ねた「AIME 2024」試験では、87.3%という高い正答率を記録、ここでもo1(83.3)を超える数値を叩き出している。
https://openai.com/index/openai-o3-mini/
企業での採用を見据え、o3-miniには新たな安全対策が組み込まれている。「deliberative alignment(熟考的整合)」と名付けられたこの仕組みは、まずモデルが安全性のガイドラインを理解・分析し、その上で適切な回答を生成する。これは、人間が「これは危険なので避けるべき」と判断するのと同じように、AIが自ら安全性を判断してから行動を起こすアプローチといえる。この結果、競合モデルと比べて、ジェイルブレイク(制限を回避しようとする攻撃)への耐性が大幅に向上したという。
このような高い性能と安全性を備えたo3-miniだが、コスト面でも大きな優位性を持つ。APIの利用料金は100万トークンあたり入力1.1ドル、出力4.4ドルと設定され、o1-miniと比べて63%、o1と比べて実に93%のコスト削減を実現している。
o3-miniは、ChatGPTのフリープラン、Plus、Team、Proの各ユーザーに提供される。特にPlusとTeamユーザーについては、1日あたりのメッセージ制限が50から150に引き上げられるなど、利便性も大幅に向上する見込みだ。
サードパーティ評価で露呈するDeepSeekとの競争、スピード/価格、安全性が焦点
OpenAIのo3-miniのリリースは、中国DeepSeekのR1モデルに対抗した動きとして見られている。どちらも高い能力を持つ推論モデルであるが、両者どのような強み・弱みを持つのか。AIモデル評価を専門とするArtificial Analysisが実施した最新のベンチマークテストに両者の違いを見て取ることができる。
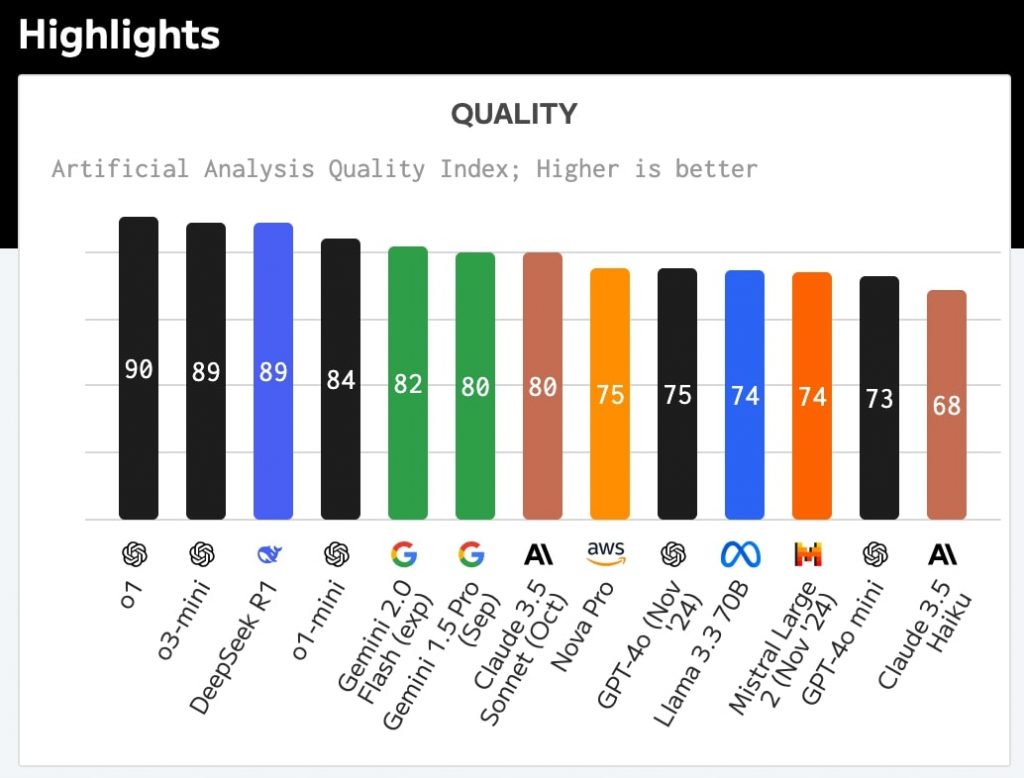
まず、モデルの性能面を見るModel Quality Indexにおいて、o3-miniは89点を獲得。DeepSeek R1と同スコア、前モデルのo1-mini(84点)から5ポイントの改善を見せた。ただし、o1(90点)には及ばない結果となった。
https://artificialanalysis.ai/
科学的推論能力を測るテストでも、o3-miniは75%という高スコアを達成。o1(77%)には若干及ばないものの、DeepSeek R1(70%)、Claude 3.5 Sonnet(59%)、GPT-4o(45%)など、競合モデルを大きく引き離す結果を示した。

https://artificialanalysis.ai/
性能面で肩を並べるo3-miniとDeepSeek R1だが、処理速度で両者の強み・弱みがはっきり分かれる。
o3-miniは1秒あたり184トークンという圧倒的な処理速度を記録。これは、実験段階のGemini 2.0 Flash(168トークン)を上回り、実質的に現時点の主要モデルの中では最速スピードとなる。これに対しDeepSeek R1は、1秒あたり19トークンと、主要モデルの中で最も遅い速度を記録。コーディングタスクなどにおける生産性に大きな差が出る可能性は想像に難くない。
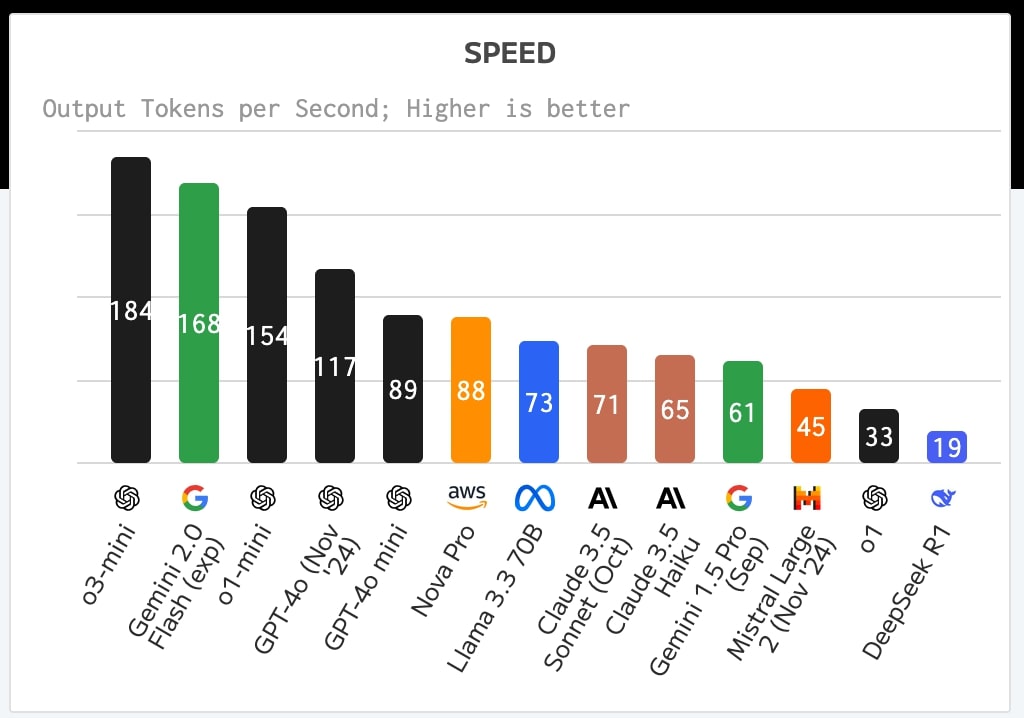
https://artificialanalysis.ai/
価格面でもo3-miniは、DeepSeek R1に対して優位性を持つ。入力と出力を合わせた100万トークンあたりの混合価格は、o3-miniが1.9ドルなのに対しDeepSeek R1は3ドルと、o3-miniはDeepSeek R1に対し3分の2以下の価格で利用できることになる。ただしo3-miniは、GPT-4o mini(0.3ドル)やLlama 3.3 70B(0.6ドル)と比べると、依然として割高な価格設定となっている。
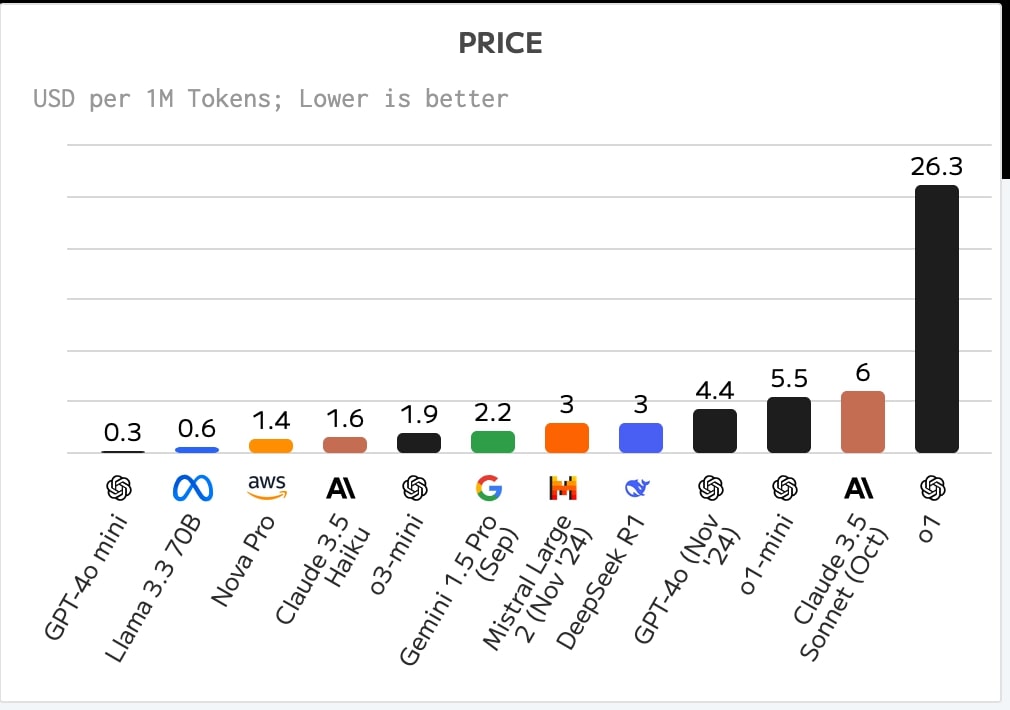
https://artificialanalysis.ai/
DeepSeekはセキュリティ面での懸念も指摘されており、米国や欧州の企業にとってはOpenAIの方が好ましい選択肢になると見られている。実際、セキュリティ研究者らによる最近の調査では、DeepSeek R1は50回のジェイルブレイク試行すべてに対して脆弱性を示したことが報告されている。一方、o3-miniは「deliberative alignment」によって高い安全性を維持しており、これらの点が企業ユーザーをひきつけられるかどうかを決める要素になると考えられる。
LiveCodeBenchが示すo3-miniの本領、高難度タスクでの際立つ性能
o3-miniの登場で、コーディング分野におけるAIモデル開発競争は新たなステージに移行する可能性が高まったと言えるだろう。第三者の中立的なコーディング能力評価「LiveCodeBench」の最新データで、o3-miniの驚異的な実力が明らかになったのだ。
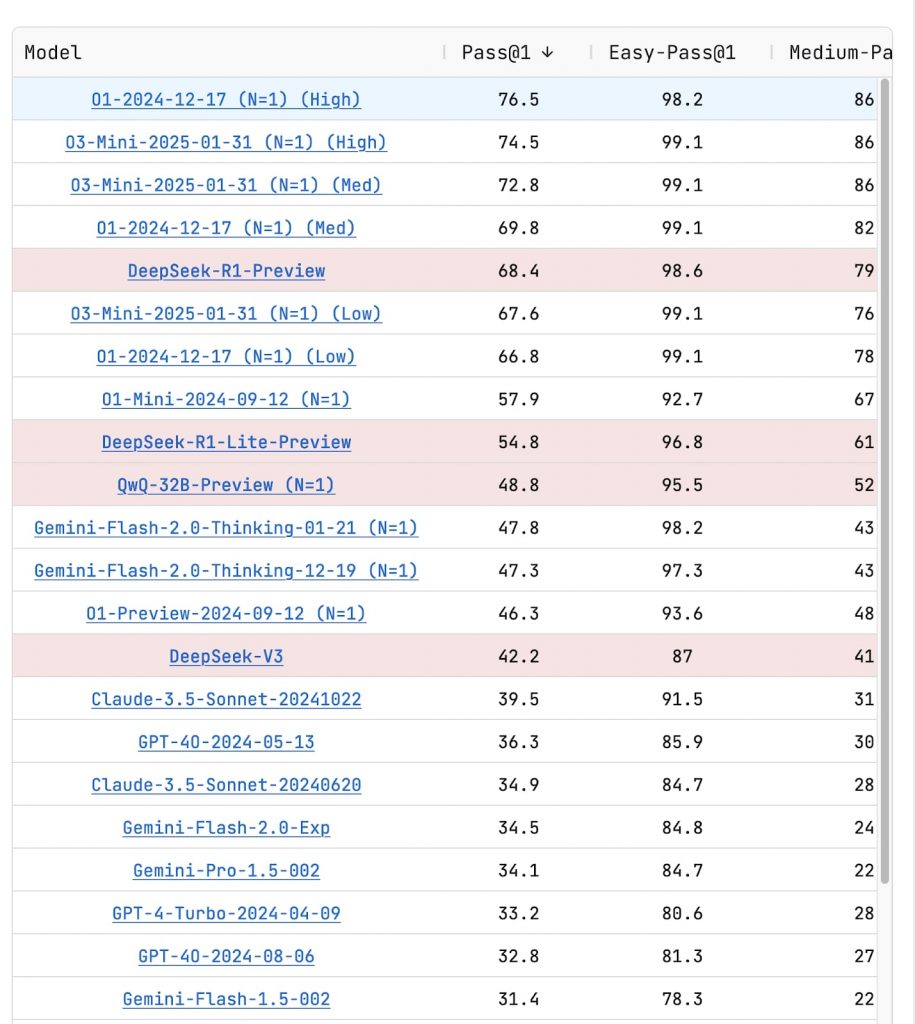
https://livecodebench.github.io/leaderboard.html
まず特筆すべきは、推論モードを「High」に設定した際のパフォーマンスだ。o3-miniは総合的な正答率(Pass@1)で74.5%を記録。これは、o1のHigh設定(76.5%)に迫る高水準であり、DeepSeek R1(68.4%)を上回る数値となる。
特に初級レベルのタスク(Easy-Pass@1)では、o3-miniは99.1%という驚異的な正答率を達成。これはo1と同等のスコアであり、実質的に完璧な精度でコード生成が可能なレベルに達したことを示唆する数値だ。
中級レベルのタスク(Medium-Pass@1)でも、o3-miniは86.9%という高い正答率を維持。これもo1と同じスコアであり、実務で頻繁に遭遇する程度の複雑さを持つタスクであれば、ほぼ確実に対応できる能力を備えたと言っても過言ではないかもしれない。
より難しいタスクになると、若干の性能差が表れる。上級レベルのタスク(Hard-Pass@1)では、o3-miniは46.5%の正答率を記録。これはo1(52.2%)には及ばないものの、DeepSeek R1(37.8%)やGemini Flash 2.0(15.9%)を大幅に上回る数値だ。
推論モードを「Medium」に設定した場合でも、o3-miniは総合で72.8%という高いスコアを維持できる点も注目に値する。この数値は、o1のMedium設定(69.8%)を上回っており、効率性と性能のバランスが取れていることを示すものとなる。
また、推論モードを「Low」に設定した場合でも、o3-miniは67.6%という堅実なスコアを記録、競合モデルのDeepSeek R1-Lite(54.8%)やQwQ-32B(48.8%)を上回る実力を示した。特に初級タスクでは99.1%という高精度を維持しており、シンプルな開発タスクであれば、最小限の計算リソースでも十分な性能を発揮することが期待できる。
LiveCodeBenchの結果は、o3-miniが実用的なコーディング支援ツールとして十分な能力を備えていることを裏付けるもの。特に推論モードに応じて計算リソースを調整できる柔軟性は、開発現場で重宝されることになるはずだ。
文:細谷元(Livit)