
LLMの革新、トークンからバイトへ メタが開発した新アーキテクチャ「BLT」の全容
INDEX
大規模言語モデル開発の課題:トークン利用における非効率性
AI研究コミュニティは、大規模言語モデル(LLM)の新たな改善方法を模索し続けている。
特に注目される課題の1つとして、既存LLMが依拠するトークンベースアーキテクチャにおける非効率性が挙げられる。
そもそも、LLMの文脈における「トークン」とは、事前に定義されたバイト(データの最小単位)の組み合わせのことを指す。LLMは、入力テキストをこのトークンに分解して処理する。これにより、計算リソースを効率的に使用することが可能となるのだ。
例えば「intelligence」という単語を考えてみたい。コンピュータ上では、この単語は「i」「n」「t」「e」「l」「l」「i」「g」「e」「n」「c」「e」という12個の文字(バイト)として保存されている。しかし、LLMはこの単語全体を「intelligence」という1つのトークンとして扱うことができる。これは、人間が文字を1つずつ読むのではなく、「intelligence」を1つの意味のある単位として瞬時に認識するのと似た仕組みだ。このように単語やよく使われる文字の組み合わせを1つのトークンとして扱うことで、LLMはテキストをより効率的に処理できるようになる。
しかし、このトークンベースのアプローチには、いくつかの重大な課題が存在する。その1つが、固定された語彙に起因する処理の偏りだ。特にウェブ上での出現頻度が低い言語を処理する際、その言語の単語が語彙に含まれていないために、処理が遅くなったり、コストが増大したりする問題が発生する。
たとえば「computer」という単語は1つのトークンとして処理できるが、ウェブ上で出現頻度の低い言語の単語は、「co」「mp」「ut」「er」のように複数の小さなトークンに分割して処理せざるを得ない場合がある。これは、その言語の単語が事前に定義された語彙に含まれていないため起こる。このような分割処理は、計算コストの増加や処理速度の低下、さらには精度の低下にもつながる可能性がある。
また、スペルミスへの対応も大きな課題となっている。入力テキストに誤字があった場合、モデルが不適切なトークン分割を行う可能性があり、結果として処理精度が低下する。さらに、文字レベルのタスク、たとえば文字列の操作などにおいても、トークンベースのモデルは苦手とする傾向にあるとされる。
トークン語彙の修正や拡張にも大きな制約がある。語彙を変更するには、モデルの再学習が必要となるのだ。またトークン語彙を拡張する場合、モデルのアーキテクチャ自体の変更が必要となり、追加された複雑性に対応するための調整が求められる。
代替案として、LLMを単一のバイトで直接学習させる方法も考えられる。これにより、上述した多くの問題を解決できる可能性がある。しかし、この方法にも大きな課題がある。バイトレベルのLLMは、大規模なモデルを学習させるためのコストが法外に高く、また非常に長いシーケンスを処理することができない。これが、現在のLLMにおいてトークン化が必須のプロセスとして残されている主な理由である。
メタの研究者らが発表したトークンに依拠しないアプローチ、その概要
こうした課題に対し、メタとワシントン大学の研究者らが画期的な解決策を提示した。それが新しいアーキテクチャ「Byte Latent Transformer(BLT)」だ。
BLTは、トークナイザーを使用せずに生のバイトデータから直接学習できる初のアーキテクチャとして注目を集めている。
BLTの中核となるのは、バイトを動的にパッチにグループ化する手法だ。このアプローチでは、データの複雑さに応じて計算リソースを柔軟に配分することが可能となる。たとえば、単語の末尾部分のように予測が比較的容易な部分には少ないリソースを割り当て、文の最初の単語など、予測が困難な部分により多くの計算リソースを配分する。
アーキテクチャは3つのブロックで構成されている。2つの軽量なバイトレベルのローカルモデル(エンコーダー/デコーダー)と、1つの大規模な「潜在グローバルトランスフォーマー」だ。エンコーダーは入力バイトをパッチ表現に変換し、デコーダーはパッチ表現を生のバイトに戻す役割を担う。そして、グローバルトランスフォーマーが学習と推論の主要な処理を行う。
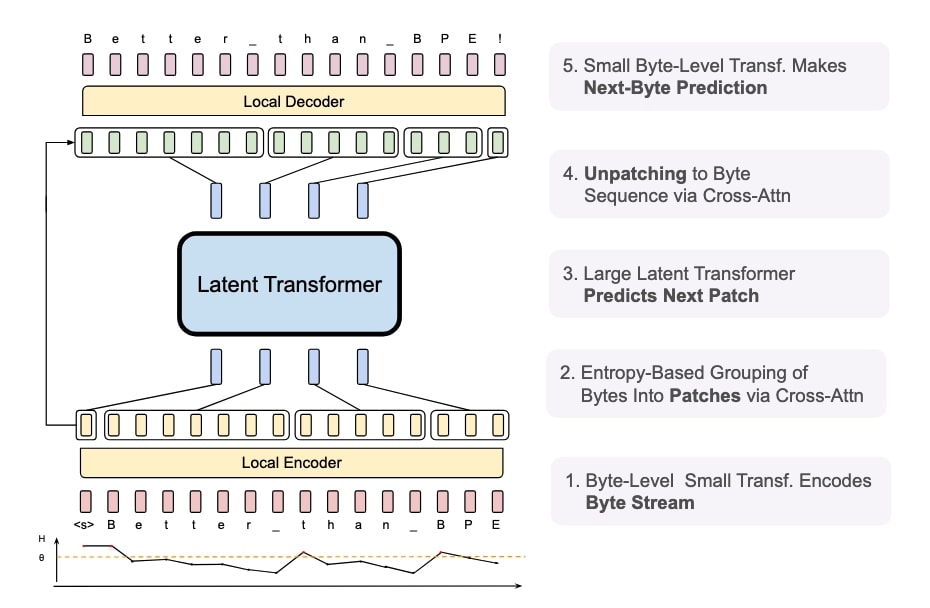
これは、多言語の会議での通訳システムのようなものと言えるだろう。エンコーダーは、参加者の発言(入力データ)を一定のまとまり(パッチ)に整理して、会議の共通言語(パッチ表現)に変換する通訳者の役割を果たす。グローバルトランスフォーマーは、その共通言語で行われる会議の本体であり、実際の議論や意思決定(主要な処理)を行う。そして、デコーダーは、会議での決定事項を再び各参加者の言語(出力データ)に翻訳して伝える通訳者の役割を担う。このように3つの要素が連携することで、効率的な情報処理を実現している。
一方、従来のLLMは、事前に定義された固定の辞書(トークナイザー)を使用する仕組みだ。この会議の例で言えば、全ての参加者が同じ辞書を使って発言を定型的な表現に変換してから会議に参加するようなものである。この方法は効率的である一方で、辞書に載っていない表現や新しい言い回しに対応できないという制約がある。これに対しBLTは、入力される情報の特性に応じて柔軟に処理方法を変えることができ、より自然な言語処理を実現できるのだ。
この新しいアプローチの特筆すべき点は、従来のトークンベースのモデルと同等のパフォーマンスを達成しながら、推論効率を大幅に改善できる点にある。研究チームの実験によると、BLTはLlama 3と同等の学習性能を示しながら、推論時のFLOP(浮動小数点演算)を最大50%削減することに成功している。
また、BLTは固定語彙を持たないため、任意のバイトグループをパッチとしてマッピングできる。これにより、エンコーダーとデコーダーの軽量な学習モジュールを通じて、柔軟なパッチ表現の生成が可能となった。研究チームは、この手法がトークンベースのモデルよりも効率的なコンピューティングリソースの配分を実現すると指摘している。
さらに、BLTは従来のトークンベースモデルが抱える効率性とパフォーマンスのトレードオフ問題も解決している。従来モデルでは、処理できる単語や表現の種類(語彙)を増やすと、一度に処理できるデータ量は増えるものの、その分だけモデル全体で必要となる計算処理量も大きく増加してしまうという課題があった。BLTは、データの複雑さに基づいてコンピューティングリソースのバランスを取ることで、この問題を克服している。
BLTアプローチ、特に注目すべき点
トークンに依存しないBLTの性能評価において、特に注目すべき点が3つある。
1つ目は、推論効率における大幅な改善だ。上記でも言及したが、研究チームの実験によると、BLTはLlama 3と同等の性能を維持しながら、推論時のコンピューティングコストを最大50%削減することに成功。データの複雑さに基づいて計算リソースを動的に配分する手法を採用したことが奏功した。
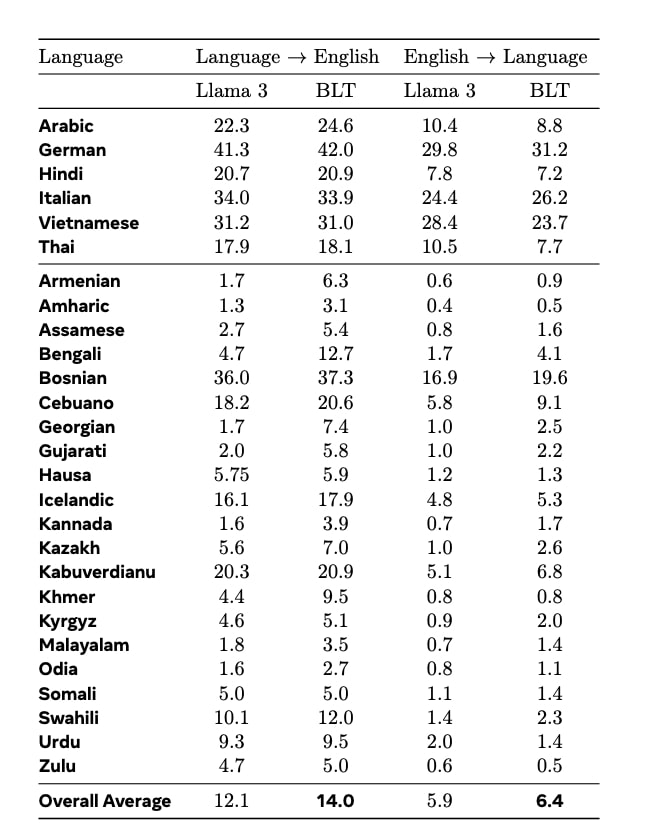
2つ目は、低頻出言語への対応力の向上だ。BLTは、101の異なる言語間の翻訳精度を測定する「FLORES-101」ベンチマークにおける低頻出言語の翻訳タスクで、Llama 3トークナイザーを使用したモデルを上回る性能を示した。英語への翻訳では2ポイント、英語からの翻訳では0.5ポイントの優位性が確認された。特にアルメニア語(1.7%から6.3%へ)、ベンガル語(4.7%から12.7%へ)などの言語で顕著な改善が見られた。
https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
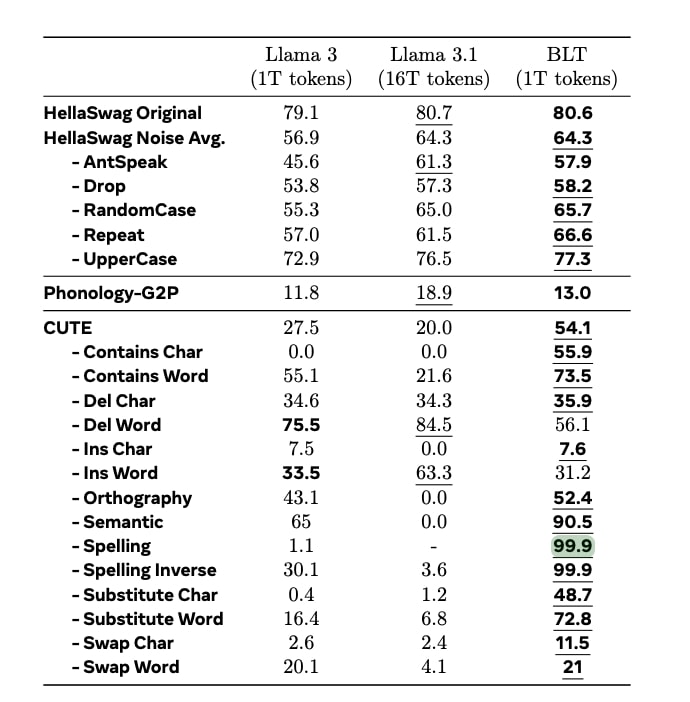
3つ目は、文字レベルでの理解力の大幅向上だ。AIモデルが個々の文字をどれだけ正確に理解し操作できるかを測定するテスト「CUTE」ベンチマークでは、BLTはトークンベースのLlama 3モデルを25ポイント以上上回る結果を示した。特にスペリング関連タスクでは99.9%という驚異的な正確性を達成。直接バイトレベルで処理を行うBLTの特性が、文字レベルの操作に効果的に機能していることが示された格好だ。
https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
現在のLLM分野は、エージェントシステム開発や推論モデル開発が特に注目を集めているが、トークンベースのアーキテクチャに挑む研究開発はまだ少ないのが現状だ。一方、メタのこの研究開発が呼び水となり、BLTを含む多様なアプローチが登場するシナリオも考えられるだろう。
文:細谷元(Livit)