

INDEX
AIインフラ投資はやはり必須か、Grok3が物語る現実
中国DeepSeekが「600万ドル」という低コストでR1モデルを開発したとされる報道は、AI業界に大きな衝撃を与えた。これまで必須とされてきた大規模なAI開発インフラが本当に必要なのかという疑念を増大させたためだ。
しかし、イーロン・マスク氏率いるxAIがこのほど発表した最新の「Grok3」モデルが物語るのは、現時点ではやはり大規模なAIインフラは、優位性を確立するために必要であるということだ。
Grok3は、非推論モデルでありながら、推論モデルであるDeepSeek R1に迫る性能を発揮、さらにGrok3をベースとする推論モデルGrok3(Think)は、OpenAIのo3をも上回るパフォーマンスを示す。
まず、このGrok3がどのような環境で開発されたのかを詳しく見ていきたい。
同モデルが開発されたのは、xAIが米メンフィスに建設したスーパーコンピュータクラスタだ。このクラスタは、スーパーマイクロ(Supermicro)およびNVIDIAの協力により建設されたもので、10万基以上のNVIDIA HGX H100 GPUと、エクサバイト規模のストレージ、高速ネットワークを備える世界最大規模の液冷GPUクラスタとなる。
GPUとは画像処理に特化した半導体で、近年ではAI開発にも不可欠な存在となっている。xAIは、このGPUを4つの巨大な計算センターに分散配置。各センターには約2万5,000基のGPUが設置されている。
同クラスタの特徴の1つとして、最新の液冷技術が全面採用された点が挙げられる。従来のAIコンピューターは空気で冷やす方式が一般的だったが、xAIは液体で直接冷却する方式を採用。これにより、高性能なGPUを大量に設置しても、安定した冷却が可能となった。万が一、冷却装置の一部が故障しても、数分で交換できる設計を採用することで、システムの安定性も確保している。
通信面でも最新技術を採用。一般的な家庭用インターネットの400倍という超高速通信により、大量のデータを瞬時にやり取りすることができる。これにより、複数のGPUを連携させた効率的なAI開発が可能となった。
この巨大施設の建設スピードも特筆に値する。電力設備すら整っていない更地の状態から、わずか122日でAIスーパーコンピューターとして稼働を開始した。この急速な立ち上げを可能にしたのが、サーバー機器メーカーのスーパーマイクロ社が開発した独自の設計思想だ。液冷システムを前提とした設計が、大規模システムの迅速導入を実現したという。
Grok3の特徴、非推論モデルとして推論モデルに並ぶ性能
xAIが開発したGrok3は、前世代モデルと比較して10倍の計算能力を投入して開発された言語モデルだ。推論、数学、コーディング、一般知識、指示追従タスクなど、幅広い分野で大幅な性能向上を達成した。
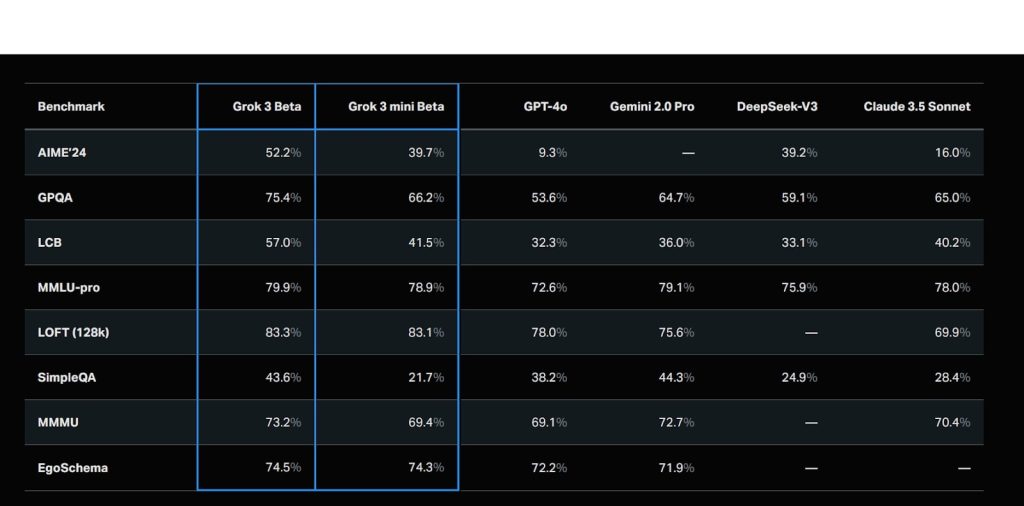
大きな特徴の1つは、100万トークンというコンテキストウィンドウだ。これは前世代の8倍のサイズで、大規模な文書処理や複雑なプロンプトへの対応を可能にした。実際、長文コンテキストのRAGユースケースを対象としたLOFT(128k)ベンチマークでは、12の多様なタスクで最高精度を記録。これまでの言語モデルは、大きなコンテキストウィンドウを持っていても、実際に「使える範囲」は限定的であった。Grok3は、このジレンマを打ち破るモデルの1つであることは間違いないだろう。
非推論モデルとしての基本性能を見ると、米数学オリンピック予選を兼ねたAIME’24では52.2%という高スコアを記録。これはGPT-4o(9.3%)、DeepSeek-V3(39.2%)、Claude 3.5 Sonnet(16.0%)を大きく上回る数値だ。大学院レベルの科学推論能力を測るGPQAでも75.4%というスコアを達成し、GPT-4o(53.6%)やDeepSeek-V3(59.1%)を優に超えた。
コーディング分野では、LiveCodeBench(LCB)で57.0%を記録。ここでもGPT-4o(32.3%)やDeepSeek-V3(33.1%)を大きく引き離す。一般知識を問うMMLU-proでも79.9%を達成し、GPT-4o(72.6%)とDeepSeek-V3(75.9%)を上回る数値を記録している。
https://x.ai/blog/grok-3
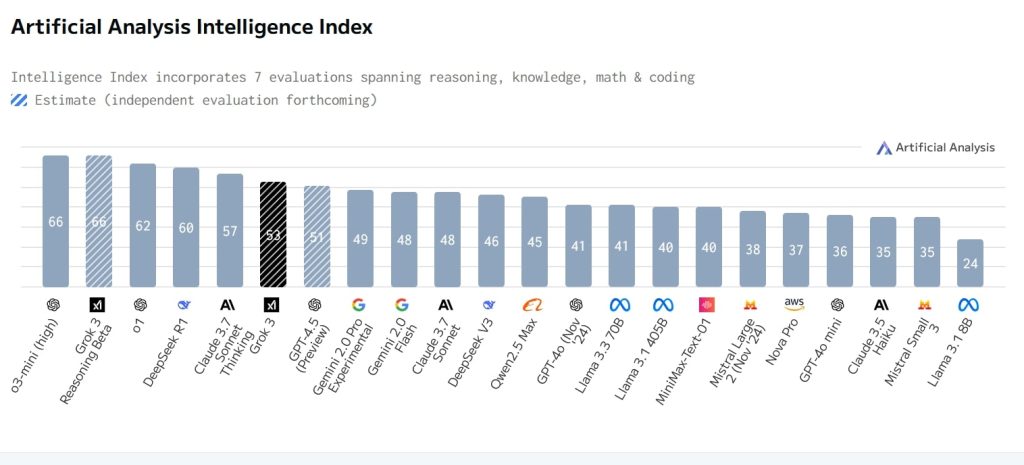
サードパーティのベンチマークでも優位なスコアを示す。Artificial Analysisの総合指数では、53ポイントと非推論モデルとしては最高値を記録、OpenAIの最新非推論モデルGPT-4.5の51ポイントを超えた。この53ポイントは、Anthropicの最新ハイブリッドモデルClaude Sonnet 3.7 Thinkingの57ポイントやDeepSeekの推論モデルR1の60ポイントに並ぶ数値。DeepSeekの非推論モデルであるV3(46ポイント)やGPT-4o(45ポイント)に大きな差をつけている。
https://artificialanalysis.ai/models/grok-3
ただし、完璧なモデルというわけではない。元OpenAI研究者のアンドレイ・カーパシー氏によると、引用文の捏造や、特定のタイプのユーモア、倫理的推論タスクなどで課題が残るという。
Grok3は、X(旧Twitter)のプレミアム+サブスクリプション(月額40ドル)と、単独サービス「SuperGrok」(月額30ドル)を通じて提供される。エンタープライズ向けのAPIアクセスも数週間以内に提供開始予定だ。次のセクションでは、このモデルをベースに開発された推論モデルの性能について見ていきたい。
Grok3ベースの推論モデルの性能も最高水準に
Grok3をベースとした2つの推論モデル「Grok 3(Think)」と「Grok 3 mini(Think)」のパフォーマンスも目を見張るものがある。
これらは、ベースモデルに強化学習(RL)を適用し、思考の連鎖プロセスを洗練させることで、データ効率の高い高度な推論能力を実現したモデル。
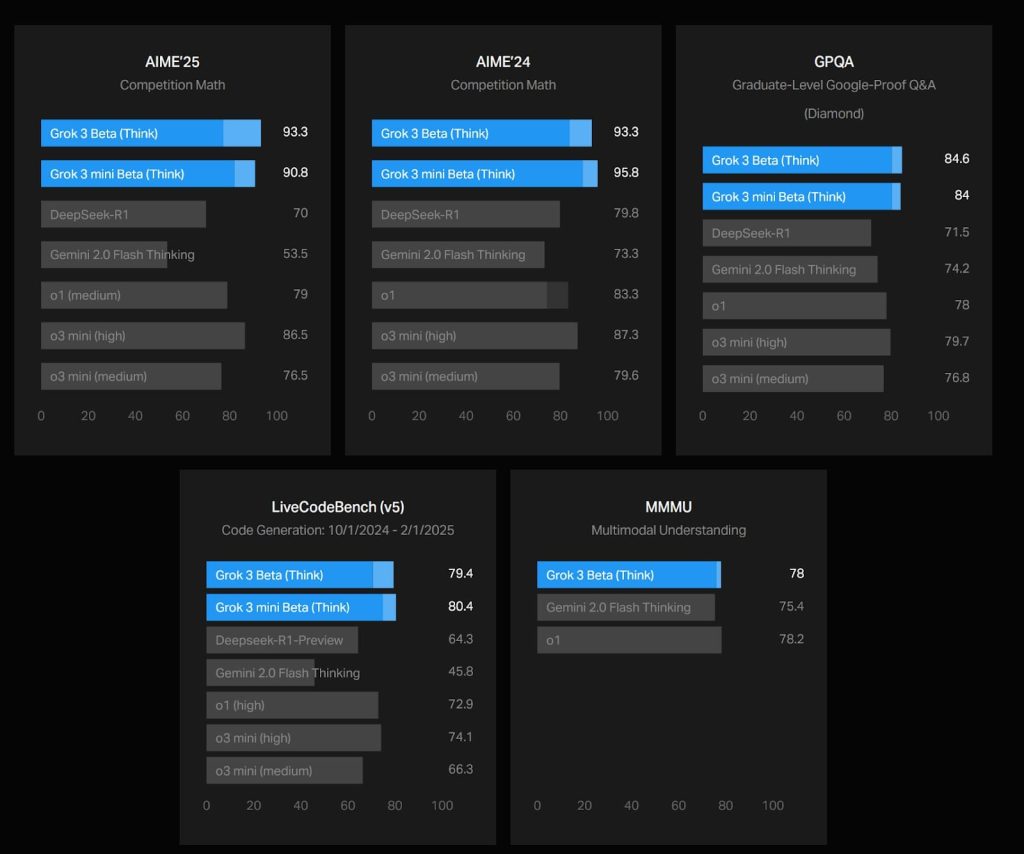
両モデルの実力を端的に示すのが、2025年2月12日に実施されたばかりの米数学オリンピック予選「AIME’25」の結果だ。Grok 3(Think)は、93.3%という驚異的な正答率を達成。Grok 3 mini (Think)も90.8%と、DeepSeek-R1(70%)やGemini 2.0 Flash Thinking(53.5%)を大きく引き離すパフォーマンスを見せつける。また、o1(79%)やo3 mini(high:86.5%)といったOpenAIの最新モデルをも上回る性能を示し、さらには前年のAIME’24でも93.3%という安定した成績を残している。
https://x.ai/blog/grok-3
大学院レベルの推論能力を図るGPQAでも、Grok 3(Think)は84.6%という高スコアを達成。DeepSeek-R1(71.5%)やGemini 2.0 Flash Thinking(74.2%)を上回り、o1(78%)やo3 mini(high:79.7%)と比較しても優位性を示す。
コード生成と問題解決を評価するLiveCodeBench(v5)においても、Grok 3(Think)は79.4%を記録。DeepSeek-R1(64.3%)やGemini 2.0 Flash Thinking(45.8%)を大幅に上回る結果となった。コスト効率を重視したGrok 3 mini (Think)が80.4%というさらに高いスコアを達成しており、API利用が可能になれば、他の競合モデルにとって脅威になる可能性は十分にあると言えるだろう。
xAIは今後も頻繁なアップデートを予定しており、エンタープライズAPIでのツール利用、コード実行、高度なエージェント機能など、さらなる機能拡張を進めていく方針だ。
文:細谷元(Livit)





