
開発者のコーディングタスクに応じて最適なLLMを選定 イェール大学らが新ベンチマークを開発
INDEX
既存のコーディングベンチマークの課題
大規模言語モデル(LLM)のコーディング能力が急速に向上する中、従来のベンチマークでは、その真の実力を正確に測定することが難しくなっている。
イェール大学と清華大学の研究チームが発表した論文によると、HumanEvalやMBPP(Mostly Basic Python Problems)といった人気のベンチマークテストは、ソフトウェア開発者が実際に直面する課題のごく一部しか評価できていないという。これらのベンチマークは、単純なタスクに対してコードを書くという基礎的な能力のみを測定するもの。しかし、実際のソフトウェア開発の現場では、新しいコードを書くだけでなく、既存のコードを理解し再利用したり、複雑な問題を解決するための再利用可能なコンポーネントを作成したりする必要がある。
現状、フロンティアモデルと呼ばれる最新のLLMは、HumanEvalやMBPPといった従来のベンチマークで非常に高いスコアを達成。たとえば、OpenAIのo1-miniはHumanEvalで96.2%というほぼ完璧なスコアを有する。その他のモデルも、単純なコーディングタスクにおいては軒並み90%を超える高い性能を示している。
一方で、より複雑なベンチマークも存在する。たとえばSWE-Benchは、外部ライブラリやファイルの使用、DevOpsツールの管理など、エンド・ツー・エンドのソフトウェアエンジニアリングタスクを評価するもの。このベンチマークは非常に難しく、最新モデルでも、そのスコアは限定的なものとなる。
このように、既存のベンチマークは「簡単すぎる」か「難しすぎる」かのいずれかであり、実際のソフトウェア開発現場で必要とされる能力を適切に評価できていないのが現状だ。人間のプログラマーが主導し、AIがコパイロットとして特定のコーディングタスクを支援するという実際の開発現場により近い評価基準が必要とされている。
イェール大学と清華大学が開発した新しいベンチマーク
こうした課題に対応するため、イェール大学と清華大学の研究チームは「自己呼び出しコード生成(self-invoking code generation)」という新しい評価タスクを考案した。このタスクでは、モデルはまず基本的な問題を解決し、その解決策を利用してより複雑な問題に取り組む必要がある。これにより、コードの理解力と再利用能力を総合的に評価することができるようになる。
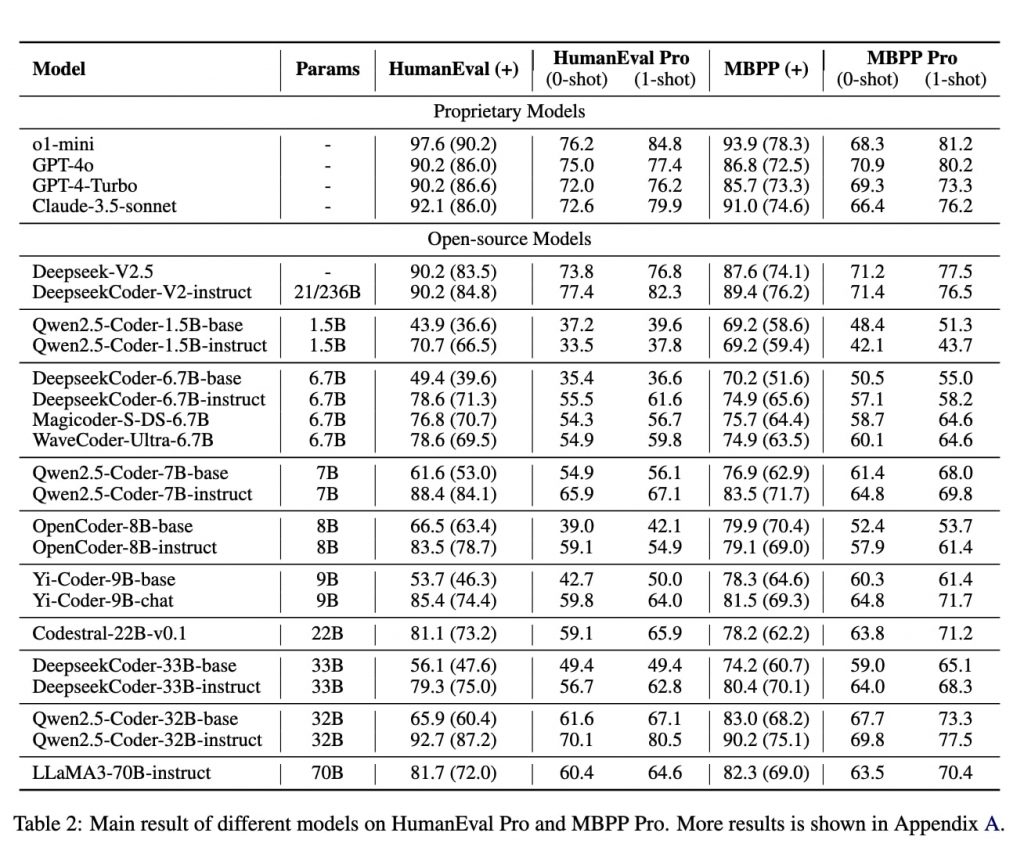
研究チームは既存のHumanEvalとMBPPを拡張し、HumanEval ProとMBPP Proという2つの新ベンチマークを開発。これらは、従来の単純なコーディング課題に加えて、生成したコードを再利用して複雑な問題を解くという要素を追加したものだ。たとえば、「文字列内の特定の文字を置換する関数」という基本問題に対して、その解答を利用して「複数の文字を一度に置換する関数」を作成するといった具合である。
ベンチマーク作成にあたっては、品質と正確性を確保するため、3段階のプロセスを採用。まず第1段階では、AI言語モデルのDeepSeek-V2.5を使用して、基本問題と、それを活用したより複雑な問題のペアを自動生成。同時に、それぞれの問題に対する解決策の候補とテストケースも生成する。第2段階では、生成された解決策をテストケースで実際に実行し、正しい出力が得られるかを検証。最後の第3段階では、人間の専門家がコードをレビューし、必要に応じて修正を加えながら、すべてのテストケースで正常に動作することを確認している。このように、AIによる自動生成と人間による精査を組み合わせることで、実用的で信頼性の高いベンチマークを実現した。
20以上のオープンソースおよびプロプライエタリモデルを対象に評価を実施したところ、興味深い結果が得られた。ほとんどのLLMで、従来のコーディングベンチマークと自己呼び出しコード生成タスクの間で10%から15%の性能低下が確認されたのだ。たとえば、o1-miniはHumanEvalで96.2%のスコアを達成する一方、HumanEval Proでは76.2%に留まった。
また、オープンソースLLMがプロプライエタリLLM(OpenAIのモデルなど)と同等の性能を発揮したことも確認された。その1つDeepseekCoder-V2-instructは、HumanEval Proで77.4%を記録し、すべてのプロプライエタリLLMのスコアを上回った。
https://arxiv.org/pdf/2412.21199
新ベンチマークの活用可能性、コーディングタスクに応じたモデル選定
新しいベンチマークによる評価結果をまとめると、最新のAIモデルは、「配列の要素を並び替える」「文字列を検索する」といった個別の基本的なコード生成では高い精度を示すものの、自身が生成したコードを活用してより複雑な問題を解くとなると途端に性能が低下する。
また、ChatGPTのように人間との対話を通じて性能を向上させる「インストラクションチューニング」と呼ばれる従来の学習手法も、このような複雑なコード生成タスクに対しては、期待したほどの効果が得られないことが判明した。たとえば、インストラクションチューニングされたQwen2.5Coder-32B-instructは、チューニングされていないベースモデルに対し、HumanEvalで26.8%の改善を示したが、HumanEval Proでは8.5%の改善にとどまっている。
これは、実際のソフトウェア開発現場で必要とされる「コードの再利用」や「モジュール化」といった高度なプログラミングスキルを、現在のAIモデルがまだ十分に習得できていないことを示唆している。
これらの知見は、開発者がプロジェクトの特性に応じて最適なLLMを選択する際の重要な指針となる。単純なコード生成タスクが中心のプロジェクトであれば、従来のベンチマークで高いスコアを示すモデルを選択。一方、既存コードの理解と再利用が重要となるプロジェクトでは、自己呼び出しコード生成ベンチマークでの性能を重視するといった具合だ。
さらに、このベンチマークは、コード品質の向上という観点からも重要な意味を持つ。CISQの調査によると、コード品質の低さによる年間損失は、米国だけで2兆8,400億ドルに上るという。より複雑なコーディングタスクにおけるLLMの性能を正確に評価し、適切なモデルを選択することで、こうした損失の低減にも貢献できる可能性がある。
開発チームは、このベンチマーク構築アプローチを他のコード生成ベンチマークにも拡張できるとしている。
文:細谷元(Livit)