

INDEX
オンラインタスクの自動化、マイクロソフト最新の取り組み
情報検索・抽出などのオンラインタスク、さらにはエクセルへのデータ入力などパソコン操作タスクを自動化できる未来が生成AIの進化によって現実となりつつある。
直近の動きとしてまず注目されるのは、マイクロソフトのAIアシスタント「Copilot」への新機能「Vision」の追加だろう。この機能は、エッジブラウザ上でウェブページの内容を読み取り、ユーザーの目的に応じて情報を分析・提供することを可能とするもので、学術論文の調査やショッピングなど、日常的なウェブタスクの効率化を実現する。
Copilot Visionは、ブラウザの下部に配置される小さなバーから呼び出すことができる。ユーザーは、ウェブページを閲覧中に支援が必要になった際、このバーをタップしてVisionを有効化。すると、AIが第二の目としてウェブページの内容を分析し、ユーザーと対話しながらタスクの遂行をサポートする仕組みとなっている。
具体的な活用例として、マイクロソフトは美術館訪問の計画作りを挙げる。ユーザーが美術館のウェブサイトを閲覧する際、Copilot Visionは展示内容や開館時間、チケット料金など、訪問に必要な情報を自動的に抽出し整理。また、ホリデーシーズンのショッピングでは、ユーザーの好みや要望に合わせて商品を分析し、選択をサポートすることも可能だ。プライバシーへの配慮も重視されており、機能はオプトイン形式で提供されるという。
つまり、ユーザーが明示的に機能を有効化しない限り、AIはブラウザの内容を読み取らない仕組みだ。また、セッション終了時にはユーザーとの対話内容や共有されたコンテキストは、すべて削除される。マイクロソフトは、Visionがウェブサイトのデータを取得・保存したり、モデルのトレーニングに使用したりすることはないとも強調している。
現在の提供範囲は、米国の一部Proサブスクライバーに限定されており、対象となるウェブサイトも限られている。マイクロソフトは、第三者のパブリッシャーと協力しながら機能の改善を進めており、今後は初期ユーザーからのフィードバックを基に、対象ユーザーと対応ウェブサイトを段階的に拡大していく方針だ。
オンラインタスクを含むパソコン操作の自動化も、OpenAIの新機能
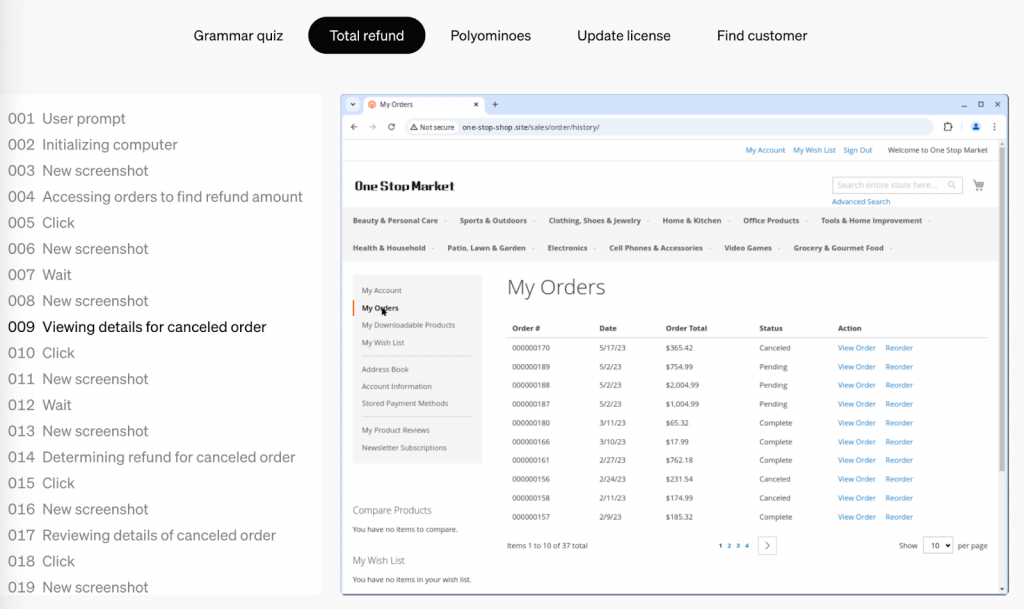
オンラインタスクとパソコン操作分野は、OpenAIの新機能が登場したことで、開発競争のさらなる激化が見込まれる。
OpenAIは2025年1月23日、汎用的なコンピュータ操作機能を持つ「Computer-Using Agent(CUA)」を発表した。CUAは、GPT-4oの視覚認識能力と強化学習による高度な推論能力を組み合わせたAIエージェントシステムで、グラフィカルユーザーインターフェース(GUI)を人間のように操作することが可能だ。
たとえば、画面上のボタンやメニュー、テキストフィールドなどを理解し、操作することができる。人間が実際にパソコンを操作するのと同じように画面を見て判断し、マウスとキーボードで操作を行う仕組みとなっており、理論上、オンラインだけでなく、オフラインにおけるエクセス操作や動画編集などさまざまなタスクを遂行することが可能だ。
CUAの動作プロセスは3段階で構成される。
まず「認識」フェーズでは、コンピュータのスクリーンショットをモデルのコンテキストに追加し、現在の状態を視覚的に把握。
次の「推論」フェーズでは、現在および過去のスクリーンショットとアクションを考慮しながら、内部で次のステップを検討する。この「内部対話」により、モデルは観察結果を評価し、中間ステップを追跡しながら動的に適応することが可能となる。
最後の「アクション」フェーズでは、タスクが完了するまで、クリックやスクロール、タイピングなどの操作を実行する。
https://openai.com/index/computer-using-agent/
オンラインタスクとパソコン操作分野は、「Claude」で知られるAnthropicが2024年10月に火蓋を切った領域となるが、CUAはAnthropicが提示したベンチマークスコアを大きく上回っており、今後の期待値を大きく高めた格好となる。
たとえば、コンピュータ操作タスク全般を評価する「OSWorld」では38.1%とAnthropicの22%を16ポイント以上上回る精度を達成。また、ウェブベースのタスクを評価する「WebArena」では58.1%とこちらも、Anthropicの36.2%を大きく超えた。さらに「WebVoyager」では87%の成功率を記録。特にWebVoyagerでは、AmazonやGitHub、Googleマップなどの実際のウェブサイトを使用した評価が行われており、実用性の高さを示す結果となった。
まず段階的に米国のProユーザーを対象にプレビュー版を提供、実際のフィードバックを収集しながら、安全対策の改善を進めていく方針だ。APIを通じた提供も計画しているとのこと。
注目度高まるAIのオンラインタスクとパソコン操作の精度測定
この1年ほど、AI開発分野では大学院レベルの知識・推論能力を測る「GPQA」、また高度な数学能力を測る「MATH」など難度の高い評価テストにおけるスコアの伸び率が注目されてきた。
かつてGPT-4でもGPQAで35%、MATHで50%ほどのスコアにとどまっていたが、最近では、GPQAで60%以上、MATHでは80%前後というのがスタンダードになりつつある。このため新たな高難度テストの開発が急務となっているのが現状だ。
そんな中、OpenAIのCUAなどが登場したことで、OSWorld、WebArena、WebVoyagerなどのベンチマークテストのスコア推移にも関心がシフトする可能性が高まっている。
ここでは、OSWorldとWebArenaとはどのようなベンチマークテストなのか、その詳細を解説したい。
まずOSWorldについて。
これは、Ubuntu、Windows、macOSなど、複数のオペレーティングシステムをまたいでAIの操作能力を評価する初のベンチマークテスト。369の実用的なコンピュータタスクを用意し、ウェブアプリとデスクトップアプリの操作、OSのファイル入出力、複数アプリケーションにまたがるワークフローなど、実際の利用シーンを想定した評価を行う。各タスクは、詳細な初期状態の設定と、カスタマイズされた実行ベースの評価スクリプトを備えており、信頼性の高い再現可能な評価を実現している。
たとえば「直近数日分の購入レシートファイルを開き・確認し、エクセルの財務表を開いて、データを更新する」といったテストが実施される。

https://os-world.github.io/
一方WebArenaは、ウェブ環境に特化したベンチマークテストだ。
Eコマース、コンテンツ管理システム(CMS)、ソーシャルフォーラムプラットフォームなど、4つのカテゴリーで評価が実施される。実際のウェブサイトの機能とデータを模倣し、人間の問題解決プロセスを再現する環境を構築、複雑な検索や情報収集、データの更新など、日常的なウェブタスクをAIが適切に処理できるかを検証する。
https://webarena.dev/
OpenAIのCUAがオンラインタスクとパソコン操作分野でのAIの可能性を示す一方で、これらのベンチマークテストが示すのは、依然として存在する人間とAIの間の大きな差だ。
OSWorldでは、人間が72.36%のタスクを完了できるのに対し、トップモデルのOpenAI CUAは38.1%、2位のByteDance SeedとTsinghua Universityによる「UI-TARS-72B-DPO」に至っては24.6%にとどまる。3位の同モデル異バージョンが22.7%、4位のAnthropicの「Claude 3.5 Sonnet」が22%と続く。AIは特に、GUIの認識と操作に関する知識において依然大きな課題を抱えているのが現状だ。
WebArenaにおいても、ウェブをスクロールしてフォームに名前を入力するといった簡単なタスクではかなり高い成功率になってきてはいるものの、複雑なタスクの処理には依然として課題が残る。たとえば、美術館の情報をWikipediaで検索し、その位置を地図上で確認し、最適な訪問ルートを計画してGitHubのリポジトリに記録するといった、複数のステップを要する作業では、長期的な計画立案と推論能力が必要となり、失敗する確率も高くなる。
それでも、Anthropicの2024年10月時の発表に比べ、OpenAIのCUAが示すように、オンラインタスクとパソコン操作の精度は着実に上がっており、OSWorldとWebArenaなどのスコアがどこまで高まっていくのかが注目されるところだ。
文:細谷元(Livit)





