
メタが最新LLM「Llama 3.2」を投入 ビジョンタスクでGPT-4oなどの主要モデルに迫る実力
INDEX
Llama 3.2モデルの特徴
メタは2024年9月25日、最新AIモデル「Llama 3.2」をリリースした。Llama 3.2は、小型〜中型の視覚言語モデル(11Bと90B)と、エッジデバイスや携帯端末で動作可能な軽量テキストモデル(1Bと3B)を含む、幅広いニーズに対応するモデル群だ。
Llama 3.2の最大の特徴は、11Bと90Bモデルが画像理解タスクに対応した点にある。これにより、文書の理解、画像のキャプション生成、視覚的な物体特定などが可能になった。グラフや地図を用いた複雑な質問への回答や、画像内容の詳細な説明といったタスクをこなせる。
一方、1Bと3Bの軽量モデルは、多言語テキスト生成やツール呼び出し機能を備え、オンデバイスでのエージェントアプリケーション開発を可能にする。これらのモデルは、クアルコムやメディアテック、ARMのハードウェアに対応しており、プライバシーを保ちつつ高速処理ができるようになる。また、Llama 3.2の1Bと3Bモデルは、12万8,000トークンというコンテキストウィンドウをサポートしている。
Llama 3.2モデルはllama.comとHugging Faceでダウンロードできるほか、25社以上のエコシステムパートナープラットフォームでも利用できるという。パートナーには、AMD、AWS、Databricks、Dell、グーグルクラウド、Groq、IBM、インテル、マイクロソフトAzure、NVIDIA、オラクルクラウド、Snowflakeなどが含まれる。また、オンデバイスパートナーとしてARM、メディアテック、クアルコムと協力しつつ、幅広いサービスを提供する計画だ。
Llama 3.2、ベンチマーク比較
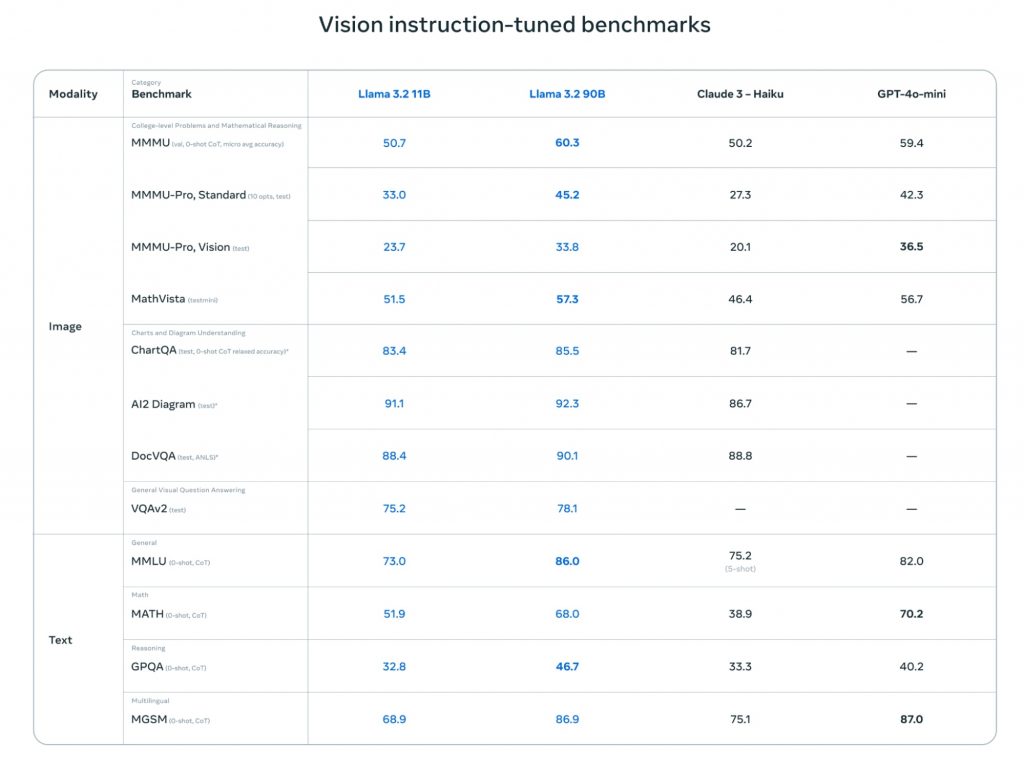
Llama 3.2の性能を評価するため、メタは様々なベンチマークテストを実施した。その結果、Llama 3.2は多くの分野で競合モデルと互角以上のパフォーマンスを示したという。特に画像理解タスクにおいて顕著な成果を挙げたとされる。
画像関連タスクでは、Llama 3.2の90Bモデルが特に優れた成績を収めた。たとえば、大学レベルの問題や数学的推論を評価するMMMUベンチマークで、Llama 3.2 90Bは60.3%のスコアを記録。これはClaude 3 Haikuの50.2%を大きく上回り、GPT-4o-miniの59.4%をも凌駕する数字となる。
さらに、グラフや図表の理解力を測るChartQAテストでは、Llama 3.2 90Bは85.5%という高スコアを達成。Claude 3 Haikuの81.7%を上回る結果となった。Llama 3.2が複雑な視覚情報を正確に解釈し、それに基づいて推論を行う能力が高いことを示唆するスコアとなる。
テキスト処理能力においても、Llama 3.2は強さを見せた。一般的な知識や推論能力を測るMMLUテストでは、86.0%のスコアを記録。これはClaude 3 Haikuの75.2%を大きく上回るだけでなく、GPT-4o-miniの82.0%も上回る数字。数学能力を測るMATHベンチマークでも、Llama 3.2 90Bは68.0%のスコアを達成し、Claude 3 Haikuの38.9%を大きく引き離した。
https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
一方、軽量モデルのLlama 3.2 1Bと3Bも、同クラスのモデルと比較して優れた性能を示している。一般的な知識を問うMMLUテストでは、Llama 3.2 3Bが63.4%のスコアを記録。これはGemma 2 2B ITの57.8%を上回るスコア。また、指示追従能力を測るIFEvalテストでは、Llama 3.2 3Bが77.4%という高スコアを達成、Gemma 2 2B ITの61.9%やPhi-3.5-mini ITの59.2%を大きく引き離す結果となった。
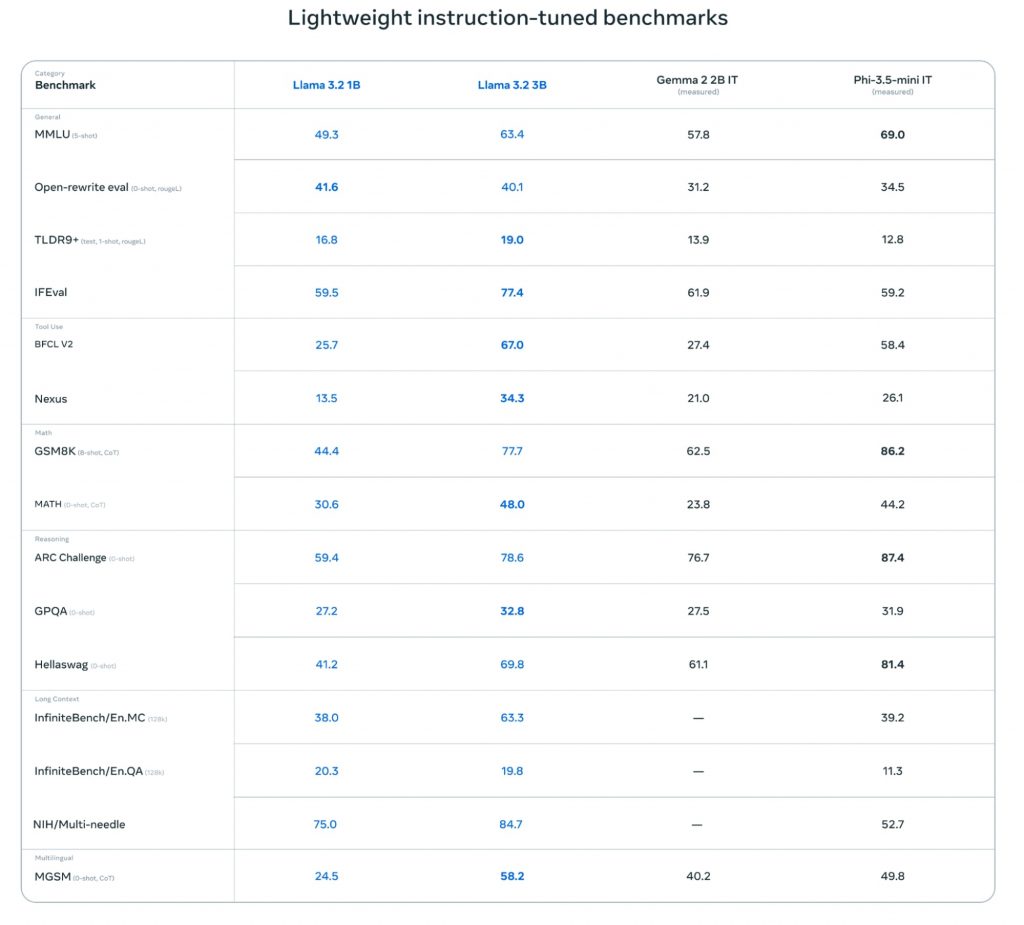
特筆すべきは、Llama 3.2の軽量モデルが長文脈理解においても優れた性能を示している点だ。12万8,000トークンの長さのテキストを扱うInfiniteBench/En.MCテストでは、Llama 3.2 3Bが63.3%のスコアを記録、Phi-3.5-mini ITの39.2%を大きく上回った。
これらのベンチマーク結果は、Llama 3.2が画像理解、テキスト処理、数学的推論、長文脈理解など、幅広い分野で高い能力を持つことを示唆するもの。特に90Bモデルは、多くの分野でGPT-4o-miniやClaude 3 Haikuといった競合モデルを凌駕しており、マルチモーダル分野でのメタの存在感を強める要素になっている。
Llama 3.2 90BとGPT-4o、Claude3.5 Sonnetとの比較
上記のベンチマークは、メタが自社で実施したもの。実際のLlama 3.2の実力を知るには、サードパーティによる評価も考慮する必要がある。
現状、やはり画像認識を含むマルチモーダル分野でトップを走るのは、OpenAIのGPT-4o、AnthropicのClaude3.5 Sonnet、グーグルのGemini1.5 Proだ。この3つのトップモデルに対して、Llama 3.2 90Bがどのようなパフォーマンスを示すのかが注目ポイントとなる。
最も参照されているリーダーボードの1つChatbot ArenaのVision版(2024年10月15日)を見てみると、GPT-4o(2024-09-03版)が1250ポイントで首位、これにGemini1.5 Proが1,232ポイント、Gemini1.5 Flashが1,210ポイント、GPT-4o(2024-05-13版)が1,208ポイント、Claude3.5 Sonnetが1,189ポイントで続く。
一方、Llama 3.2 90Bは、1,074ポイントで11位という状況にある。
このスコアと順位に対してさまざまな解釈ができるが、900億パラメータという比較的小さなモデルとしては健闘していると言えるだろう。公開されていないが、GPT-4oやClaude3.5などのトップモデルは、少なくともLlama 3.2 90Bの数倍の規模であると推察される。
実際にトップモデルとLlama 3.2 90Bのベンチマークスコアを比較してみたい。
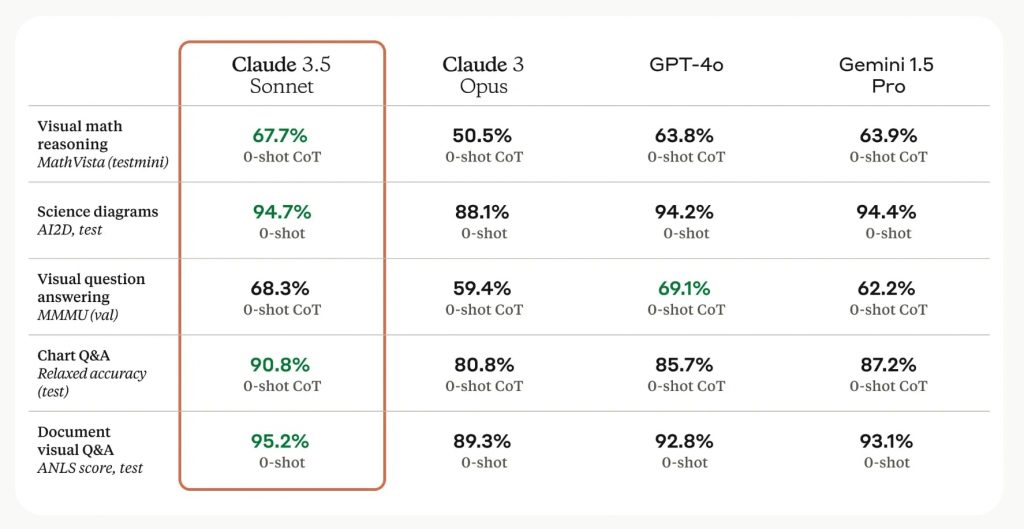
まずMMMUでは、Claude3.5 Sonnetの68.3%、GPT-4oの69.1%、Gemini1.5 Proの62.2%に対してLlama 3.2 90Bは60.9%と若干差を開けられる結果となった。また、数学のグラフ問題解決能力を測るMathVistaでも、Claude3.5 Sonnetの67.7%、GPT-4oの63.8%に対し、Llama 3.2 90Bは57.3%と後塵を拝する状況だ。
https://www.anthropic.com/news/claude-3-5-sonnet
一方、科学図表認識テストAI2Dでは、Claude3.5 Sonnetの94.7%、GPT-4oの94.2%に対し、Llama 3.2 90Bは92.3%と肉薄するスコアを記録。また文書の視覚的質問応答(DocVQA)テストでは、Llama 3.2 90Bが90.1%のスコアを記録し、GPT-4oの88.4%を上回った。また、グラフや図表の理解力を測るChartQAテストでは、Llama 3.2 90Bが85.5%、GPT-4oが85.7%とほぼ互角の精度を示した。
AIMLAPIのテスト結果:浮き彫りになる両モデルの特性
広範なベンチマークテストに加え、個別のテスト結果も、Llama 3.2 90Bの特徴を知る上で役立つはずだ。
AIMLAPIによる、Llama 3.2 90BとGPT-4oの比較テストで、ビジョンタスクにおける両モデルの強み・弱みの一端が示されている。
このテストにおいて、GPT-4oは、テキスト認識や複雑な推論を要するタスクで優位性を示した。「The Hobbit」の章の一部内容を正確に識別し全文を再現できたほか、三角形の角度を求める数学問題でも正確な解答と詳細な解説を提供した。
一方、Llama 3.2 90B Visionは特定の視覚タスクで強みを発揮。5頭のシマウマを写した画像のオブジェクトカウントタスクでは、GPT-4oが誤って6頭とカウントしたのに対し、Llama 3.2 90Bは正確に5頭とカウントした。また、ウェブサイトのスケッチからHTMLコードを生成するタスクでも高い性能を示し、5点満点中4点を獲得した。
このテスト結果は、AI2Dの高スコアが示すようにLlama 3.2 90Bが高い画像認識能力を持つことを裏付けるものといえる。一方、数学のグラフ問題に関する結果は、MathVistaのスコア差にも示されるように、現状ではLlama 3.2 90Bの弱点であることを示唆している。この問題に加え、テキスト認識能力などが、今後の課題になると思われる。
マルチモーダル分野では、OpenAI、Anthropic、グーグルがリードを保ってきたが、メタのLlama 3.2 90Bに加え、Mistralが同社初のマルチモーダルモデル「Pixtral」をリリースするなど、開発競争は激化の様相だ。OpenAIは最新のo1モデルのマルチモーダル化、またAnthropicはClaude3.5 Opusが次の一手になると思われる。マルチモーダルモデルの精度がどこまで高まるのかが注目される。
文:細谷元(Livit)