
ChatGPTでも不合格? 会話型AIの「本当の実力」を測る新ベンチマークが登場
INDEX
ChatGPT、Claude、Gemini、Mistralなど、会話型AIが次々と登場している。ほんの1年前まではChatGPTほぼ一択であったが、いまは多すぎてどれを選べばいいかわからない人も多いはずだ。
そんな中、AIスタートアップのSierraが、会話型AIの精度を“客観的に”測るベンチマーク「?-bench(タウベンチ)」を発表した。
会話型AIエージェントの精度を測る「?-bench」
SierraはOpenAIの取締役会のメンバーであるブレット・テイラー氏と、GoogleでAR/VR事業に従事していたクレイ・ベイバー氏が創業したAIスタートアップだ。
同社は2024年6月、会話型AIエージェント(以下、AIエージェント)のパフォーマンスを評価する新しいベンチマーク「?-bench(タウベンチ)」を発表。?-benchはLLMベースのユーザーシミュレーターを使って、AIエージェントが複雑な会話やタスクを遂行できているかをテストし、その性能を客観的に評価するという。
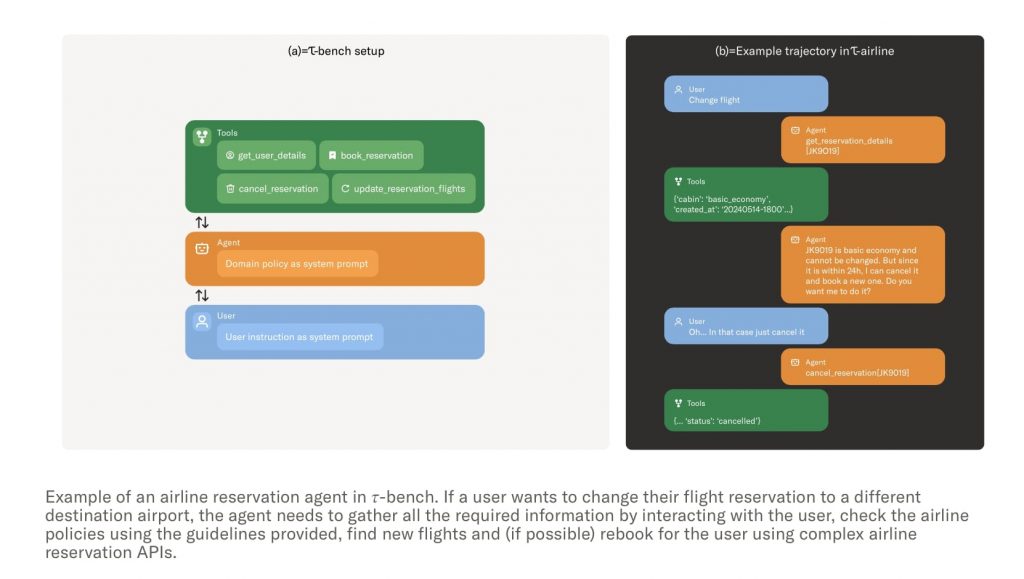
AIエージェント評価における課題
これまでもWebArena、SWE-bench、Agentbenchなど、既存の評価ベンチマークはいくつか存在した。だがSierraの研究責任者カルティク・ナラシムハン氏は、「従来のベンチマークはいくつかの重要な分野における測定が不足していた」と主張する。
ユーザーがAIエージェントとする会話は「一問一答」ではなく、より複雑で連続したものであるはずだ。だが既存のベンチマークは、たとえば「今日の天気はどうですか?」「最高気温は24度、最低気温は16度で晴れています」というような、「1ラウンド」ですべての情報を交換する会話のみを評価対象としている。
ナラシムハン氏は「これだけでうまく動いているかを評価するのは現実的でない」と言う。また、連続した会話であっても、会話全体の「平均的なパフォーマンス」評価にとどまり、信頼性や適応性といった尺度には対応していない。
?-benchの仕組みと特徴
?-benchはこれらの課題に対処するため、ベンチマークに「3つの要件」を定義した。
1つ目は、AIエージェントが情報収集をして複雑な問題解決をするには、長期間にわたって人間やAPIとシームレスに会話をする必要があること。2つ目は、AIエージェントはドメイン固有のポリシーやルールを遵守すること。そして3つ目は、企業や組織が安心して利用するために、膨大なインタラクションの一貫性と信頼性を担保しなければならないことである。
?-benchには、「現実的な対話」「オープンエンドで多様なタスク」「客観的な評価」そして「モジュール式フレームワーク」といった4つの特徴がある。
言語の生成モデリングが進化したため、?-benchでは複雑なデータベースと現実的な対話シミュレーションができるようになった。そして「会話自体の評価」ではなく、エージェントの能力そのものを迅速かつ客観的に評価する。また、モジュール式に構築されているため、新しいドメインやデータベースエントリ、ルール、API、タスクなどを簡単に追加できる。
さらにτ-benchは、ドメイン固有のポリシーに従いながらユーザーやAPIと対話する能力も測定できる。LLMベースのユーザーシミュレーターを活用して複雑な会話を生成し、エージェントを評価するのである。
GPT-4oでも評価は50%未満
Sierraではτ-benchを使って、代表的な12のAIエージェント(OpenAI、Anthropic、Google、Mistralが開発したAIモデル)に対するベンチテストを行った。小売(τ-retail)と航空(τ-airline)の2つのドメインを構築し、一般的なユースケースを対象とした。
結果としては、ChatGPTの最新版「GPT-4o」が最もパフォーマンスが高いことが明らかになった。しかし驚くべきは、それでも平均成功率が50%に満たなかったことだ。
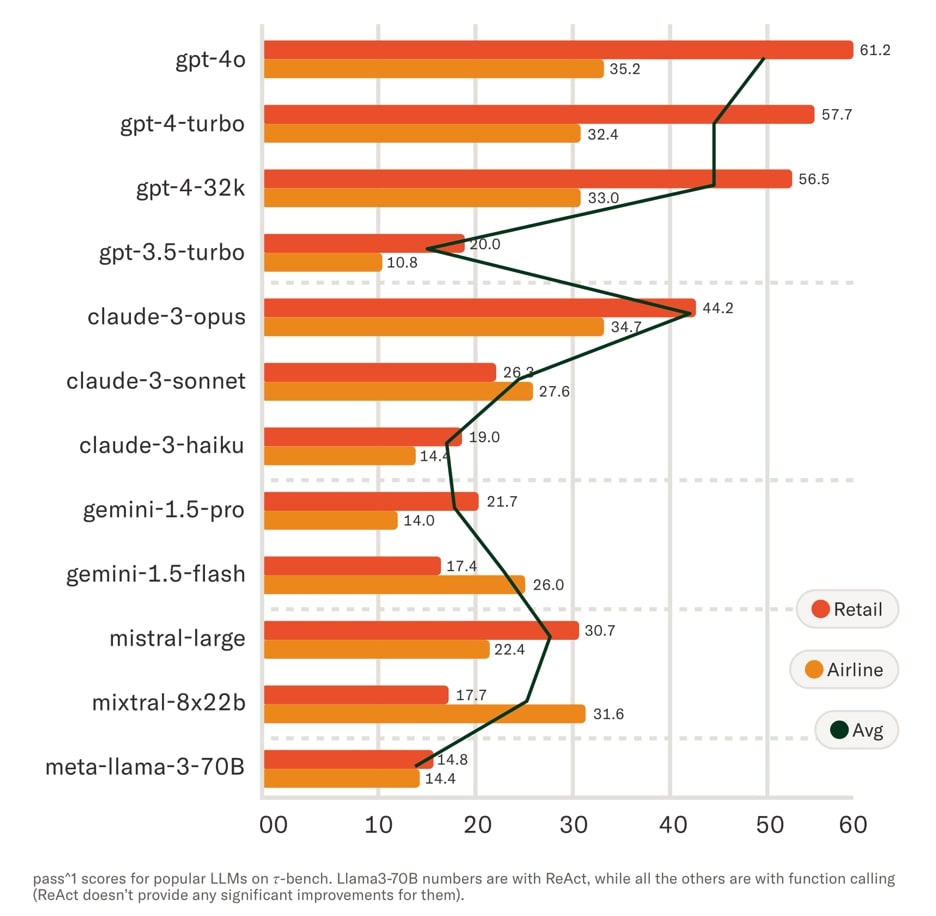
さらに、テストしたすべてのAIエージェントは信頼性においてパフォーマンスが非常に悪く、エピソードが再実行された際、まったく同じタスクを解決することができなかった。
たとえば、GPT-4oを搭載したτ-retailは、8回目のスコアは約25%であり、1回目と比較すると60%も落ちている。これは、8名(8社)の顧客が同じ問題を抱えていたとき、問題を解決できる可能性はたった25%であるということを示している。
?-benchはどんな影響を及ぼすか?
?-benchはAIエージェントの開発や実用化、そしてユーザーに対してどのような影響をもたらすのか。
まず、ユーザーにおいては、生成AIの性能や出力結果を鵜呑みにすることへのブレーキになるだろう。わかりやすいハレーションを起こしていた初期に比べ、いまの生成AIはスピードも「言語力」も格段に進化した。だが、それゆえに何の疑いも持たずに“それらしい答え”を受け入れてしまう人も多いだろう。
だがτ-benchのような客観的なベンチマークが普及することで、現実的な実用性や信頼性が明らかになり、どのエージェントを選択するか、または導入自体を進めるかどうかの判断材料となるはずだ。
開発側にとっても、この手強いベンチマークの存在は無視できないものになるはずだ。実際的なユーステストによって、自社の製品がどのドメインに弱いか、どの分野を強化すべきかなどが詳細にわかり、効率的な改善につながるだろう。
Sierraの研究チームは、新しい仕様のフレームワークと認知アーキテクチャに取り組んでいる。また、より複雑なシナリオを作成するとともに、推論と計画を改善するさらに高度なLLMを通じて、ユーザーシミュレーションの精度を上げていきたいという。
AIが社会のインフラになりつつあるいま、AIエージェントに対する信頼性の高い評価軸ができるのは非常に喜ばしいことである。Sierraに限らず、この分野のさらなる発展を期待したい。
文:矢羽野晶子
編集:岡徳之(Livit)