
アップルの「画像の意味を捉える」マルチモーダルAIモデル「4M」、画像編集の自動化などへの布石か
INDEX
アップルがAIモデル「4M」をリリース、その概要
アップルがスイス連邦工科大学ローザンヌ校(EPFL)と共同開発した小型AIモデル「4M」の公開デモをHugging Faceプラットフォームで公開した。このモデルは、テキストや画像、3D空間など複数のモダリティを統合的に処理できるマルチモーダルモデルだ。数カ月前に、GitHubでリリースされたオープンソースモデルだが、今回人気のAIプラットフォームであるHugging Faceで公開されたことで、認知度がさらに高まった格好となる。
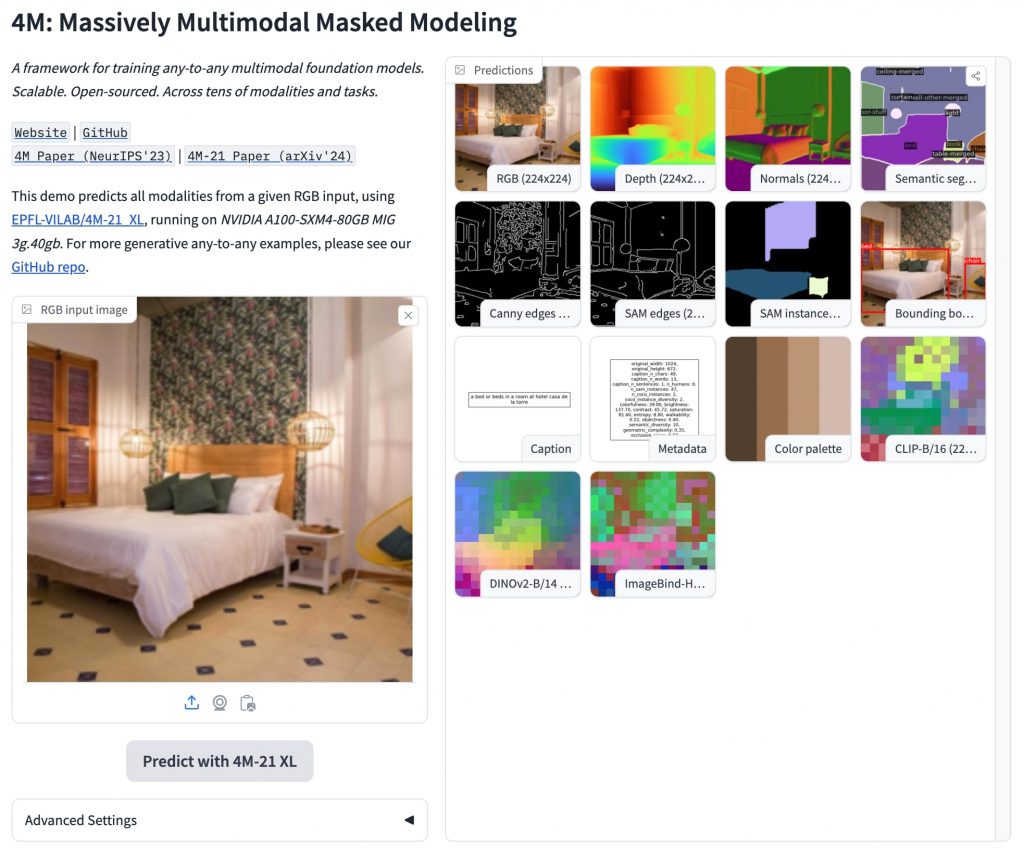
4Mは、Massively Multimodal Masked Modelingの略称で、多様なモダリティ/コンテンツの処理と生成が可能だ。ユーザーはテキスト記述から画像を生成したり、複雑な物体検出を実行したり、自然言語入力で画像空間を操作したりすることができる。
この4Mの公開は、アップルの従来の研究開発アプローチから大きな転換を示すもので、AIコミュニティで注目される動きとなっている。Hugging Faceは、業界スタンダードといっても過言ではない、AIモデルのリポジトリプラットフォーム。メタやマイクロソフトなどテック大手からスタートアップまでさまざまなプレイヤーが、自社で開発したAIモデルを披露・公開する場となっているのだ。同プラットフォームにおける4Mの公開から、アップルは自社のAI能力を示すだけでなく、開発者の関心を引き、自社技術を中心としたエコシステムを構築しようとしている様子がうかがえる。
これまで生成AIモデルの開発において、グーグルやマイクロソフトなどと異なり沈黙を保ってきたアップルだが、2024年に入りAI関連取り組みを加速、4Mを含めさまざまなAIモデルをリリースしている。投資家はこの動きを好意的にとらえており、同社の株価はこの数カ月で20%以上上昇、時価総額も6,000億ドル近く増加した。OpenAIとのパートナーシップもアップルがAIに本腰で取り組むことを市場にアピールする材料となっており、アップルが「AI銘柄」として認識され始めているともいわれている。
4Mに関して、特筆すべきは、やはり多様なモダリティに対応できる統一性といえるだろう。テキスト以外へのモダリティに対応できるため、アップルのエコシステムにおける応用が期待されるのだ。たとえば、4Mを統合することでSiriのバージョンアップが考えられる。後述するが4Mは画像の深度マップやセマンティック分類が可能であり、「この写真の背景を夜景に変更して」といった複雑な画像編集指示にも対応できるようになる可能性がある。またFinal Cut Proにおける動画編集の自動化ができるようになる可能性もゼロではない。
4Mモデルは2億パラメータから28億パラメータまで複数のサイズで開発されたが、いずれも小型であり、オンデバイス/ローカル環境でも十分に利用できる点も特筆に値する。
4Mモデルの特徴とは?
4Mはどのような特徴を持つのか。テクニカルレポートを参照し、同モデルの強みをみていきたい。4Mの強みを一言で言うと、人間の感覚に近い形で、テキスト、画像、空間情報など、さまざまな種類のデータを一度に処理できる能力だ。
最大の特徴は、これらの異なるタイプの情報を統一的に扱える点にある。たとえば、人間が「赤いリンゴ」と聞いて、その色、形、味までイメージできるように、4Mも文字、画像、立体的な情報を関連付けて理解することができる。
「秋の公園で犬の散歩をする人」という複雑な場面描写に対しても、4Mは多角的な理解と生成が可能となる。テキストから画像を生成する際、モデルは秋の色彩(黄色や赤の葉)、公園の要素(木々、ベンチ、歩道)、人物と犬の姿勢や関係性を適切に表現できるのだ。同時に、生成された画像の深度マップを作成し、手前の人物や犬、中距離の木々、遠景の風景などの空間的関係を把握することもできる。
また、逆のプロセスも可能だ。秋の公園で犬の散歩をしている人の画像が与えられた場合、4Mはその視覚情報を分析し、適切な説明文を生成することができる。さらに、画像から3Dモデルを推定したり、シーンのセマンティックセグメンテーション(木、空、人、犬などの領域分割)を行ったりすることも可能となる。

4Mは複数の情報を矛盾なく生成できる能力も備える。たとえば、ある画像を生成した後、その画像に合わせて説明文を作成するといったことが可能となる。これは、生成した情報を次の情報生成の参考にするという方法により可能となっている。
4Mが扱える情報の種類は多岐にわたる。通常の画像だけでなく、物体の奥行きを示す深度マップ、画像内の物体の種類を示すセグメンテーション情報、さらには画像のメタデータやカラーパレットなども扱えるのだ。
性能評価では、4Mは画像の奥行き推定、物体の識別、人体の3D姿勢推定など、様々なタスクで既存の専門AIと同等かそれ以上の性能を示した。特に、1つのモデルで多くのタスクをこなせる点が、他の汎用AIモデルと比べて優れていることが確認された。
このように、4Mは多様な情報を統合的に扱える柔軟なAIモデルであり、今後のAI応用の可能性を大きく広げる潜在力を秘めている。
オンデバイスで稼働するモデルをめぐる開発競争
4Mモデルは、オンデバイスで稼働する高性能な小型モデル開発というアップルのAI戦略を如実に示すものといえるだろう。この戦略は、iPhoneやiPadなどのモバイルデバイスに直接AIモデルを搭載し、クラウドに頼らずにAI機能を提供することを目指すものだ。
4Mモデルは、最大28億パラメータ。比較的小さなモデルであり、オフライン環境やオンデバイスでの利用が想定されている。この領域は、マイクロソフトも注力しており、開発競争は激化の様相を呈している。
マイクロソフトが2024年4月にリリースした「Phi-3」は、小型言語モデルの可能性を示すモデルとして注目を集める存在。大規模な競合モデルに匹敵する高度な推論能力を、大幅に低いコストで実現したことでAIコミュニティで話題になっているのだ。
Phi-3の最小モデルである38億パラメータモデルは、法学、数学、哲学、薬学などの幅広い分野の知識を問うベンチマークテスト「MMLU」で68.8%を獲得。これはOpenAIのGPT-3.5(71.3%)に迫るだけでなく、MistralのMixtral8×7B(68.4%)やメタのLlama3 8B(66%)を上回る数値となる。
さらに、Phi-3はA16 Bionicチップ搭載のiPhone14上で、ネイティブかつオフラインに動作することが確認された点も興味深い。メモリ使用量は約1.8GBに抑えられ、1秒あたり12トークン以上を生成できるパフォーマンスを示したとされる。これは、オンラインで利用するGPT-4 Turbo(1秒あたり18トークン)に迫る速度となる。
オンデバイス/オフラインで利用できる小型モデルは、プライバシー保護やネットワーク接続に依存しない即時性の向上、さらにはAIの普及拡大につながる可能性を秘めており、今後のAI技術の方向性を左右する重要な領域といえる。これまでこの分野を牽引してきたのはマイクロソフトやメタだが、アップルが加わったことで、競争のさらなる激化が予想される。
文:細谷元(Livit)