
AWSとマイクロソフトがクラウドサービスに導入 Mistralオープンソースモデルの強み
INDEX
AWSやマイクロソフトがクラウドサービスにMistralモデルを導入
クラウドAIサービスを巡る競争が激しさを増している。AWSとマイクロソフトが、フランスのAIスタートアップMistralの大規模言語モデルの導入を相次いで発表したのだ。
AWSは、Mistralのモデル「Mistral 7B」と「Mixtral 8x7B」をAmazon Bedrockに追加すると明らかにした。一方、ライバルのマイクロソフトも、MistralのモデルをAzure AI Studioに組み込む方針を示している。
なぜMistralのモデルに注目が集まっているのか、その理由を探りつつ、Mistralの2つのフラッグシップモデル「Mixtral 8x7B」と「Mistral Large」の特徴を解説したい。
AWSは2024年2月23日、同社がMistralの「Mistral 7B」と「Mixtral 8x7B」の2つのオープンソースモデルをAmazon Bedrockに導入すると発表した。Bedrockは、2023年にリリースされた生成AI(generative AI)向けの管理型サービスだ。
AWSのブログ投稿によると、Mistral 7Bは低メモリ消費で高速なデータ処理を実現し、効率性に優れたモデルだという。テキスト要約や分類、テキストコンプリーション、コード生成などさまざまな用途に対応する。一方、Mixtral 8x7Bはさらに強力で、「Mixture-of-Experts(混合エキスパート)」アーキテクチャを用いることで、英語やフランス語、ドイツ語、スペイン語、イタリア語など複数言語でのテキスト要約、質問応答、分類、コンプリーション、コード生成を可能としている。
AWSがMistralモデルを選択した理由として、(1)コストパフォーマンスに優れる、(2)高速な推論、(3)透明性とカスタマイズ性、(4)幅広いユーザー層にとってのアクセシビリティ、の4点を挙げている。
AWSは以前からAIスタートアップAnthropicへの巨額投資を行っているが、Mistralとの提携は、同社が幅広いモデルを顧客に提供したいという意向の表れと見られる。AWSのライバルであるマイクロソフトは、MetaのオープンソースLlamaモデルをAzure AI Studioに追加しており、AWSと同様の戦略を取っていることがうかがえる。
実際、Mistralは2024年2月にマイクロソフトと提携し、同社のフラッグシップ商用モデル「Mistral Large」をAzureクラウドプラットフォームで提供することを発表。これにより、MistralはOpenAIに次ぐ2番目のAzure上の商用大規模言語モデル提供企業となった。
マイクロソフトがMistralと提携したのは、同社の技術力の高さを認めたことによるという。マイクロソフトはこの1年でAI業界のリーダー的存在となったが、Mistralとの提携はAzureサービスの強化とOpenAIへの依存度低減を狙ったものとみられている。
主要モデルの中で最速、Mistralのフラッグシップモデル「Mixtral」
AWSとマイクロソフトの両社がMistralのモデルを自社クラウドサービスに導入した主な理由は、MistralのAIモデルにおける技術的優位性だろう。以下では、Mistral社が最近リリースした2つのフラッグシップモデル「Mixtral 8x7B」と「Mistral Large」について解説したい。
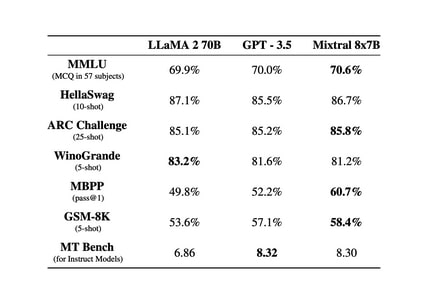
Mixtral 8x7Bは、2023年12月に発表されたオープンソースモデル。Llama2 70Bを上回る性能と6倍の推論速度を実現。Apache 2.0ライセンスの下で提供され、GPT-3.5に匹敵、あるいは上回るコストパフォーマンスを誇る。Apache 2.0ライセンスとは、オープンソースソフトウェアで広く使われているライセンスの1つで、商用・非商用を問わず、誰でも自由に使用、変更、配布することが可能だ。
Mixtral 8x7Bは3万2,000トークンのコンテキストに対応し、英語、フランス語、イタリア語、ドイツ語、スペイン語での応答に優れ、コード生成にも強みを持つ。多様なタスク能力を測るベンチマークテスト「MT-Bench(Multi-Task Benchmark)」では8.3のスコアを達成した。これはOpenAIのGPT‐3.5と同等の能力となる。
混合エキスパートアーキテクチャを採用しており、560億相当のパラメータを持ちながら、70億相当のコストと速度で動作する。これによりトレーニングと推論を大幅に高速化できる。
Artificial Analysisのまとめでは、1秒あたりに処理できるトークン数は、Mixtral 8x7Bが117トークンとなり、主要モデルの中で最速であることが判明した。OpenAIのGPT‐3.5 Turboが63トークンであることを鑑みると、Mixtral 8x7Bが如何に高速なのかがわかる。メタのフラッグシップモデルLlama 2との比較では、特にコードと数学分野で大きくリードし、効率性でも優位に立つ。多言語ベンチマークではLlama 2 70Bをしのぐスコアをたたき出している。
速度を重視するアプリケーション開発に最適なモデルといえるが、日本語に対応していないなどの弱点を持っており、今後の改善に期待が寄せられる。
GPT-4に迫るMistral Large
一方、Mistral Largeは2024年2月にリリースされたMistralの最新かつ最先端の商用言語モデルだ。La PlatefomeとAzureから利用可能となった。
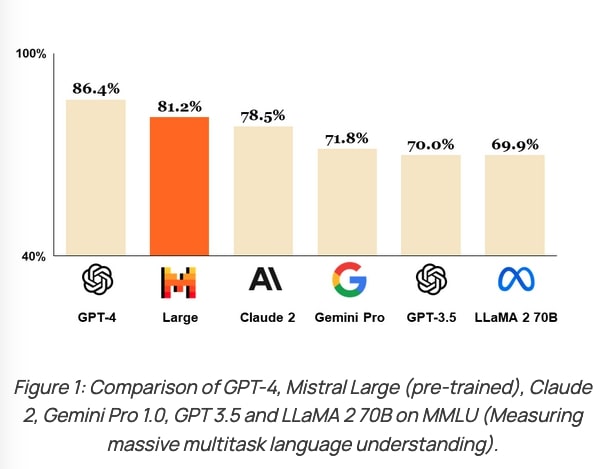
Mistral Largeは複雑な多言語の推論タスク、テキスト理解、変換、コード生成などでトップクラスの性能を発揮する。APIを通じて利用可能なモデルとしてはGPT-4に次ぐ性能を誇っている。
英語、フランス語、スペイン語、ドイツ語、イタリア語に精通し、文法と文化的文脈の深い理解を備える。3万2,000トークンのコンテキストウィンドウにより大規模なドキュメントから正確な情報を呼び出すことも可能だ。
MMRUやHellaSwag、Arc Challenge、TriviaQA、TruthfulQAなどの常識的推論や知識を問うベンチマークテストで高スコアを獲得。MMRUは数学、物理学、歴史などに関する問題を含むマルチタスク能力を測るベンチマーク。一方、HellaSwagは常識的推論能力、Arc Challengeは物語や文章における因果関係や動機づけを理解する能力、TriviaQAは知識の幅広さと深さ、TruthfulQAは言語モデルが真実の情報を提供できるかどうかを評価するベンチマーク。
Mixtral 8x7B同様に、多言語タスク(英語やフランス語など)でもLLaMA 2 70Bを大きく上回った。また、コーディングと数学のタスクでもトップクラスの成績を収めている。Artificial Analysisのまとめでは、Mistral Largeの1秒あたりの処理トークン数は36トークンとMixtral 8x7Bに比べると3分の1ほどとなり、処理速度は若干遅くなる。ただし、16トークンのGPT-4 Turboに比べると2倍以上の速度を有しており、高い精度を保ちつつ、スピードを重視するアプリケーションで重宝される可能性が高い。
両者に共通するのは、高い効率性と多言語対応力(英語と欧州言語)、そして高度な推論能力。Mixtralが研究やオープンソース活用、個人利用に適している一方、Mistral Largeは商用アプリケーションの開発に最適といえるだろう。
AWSとマイクロソフトの競争が激化するクラウド市場だが、両者とも生成AI関連の取り組みを緩める気配はない。
AWSは2024年3月、AnthropicのClaude3をAmazon Bedrockに追加したと発表。Claude3は多くのベンチマークでGPT-4を上回る性能を示したとされる驚異のモデル。これまでGPT-4が市場における最高峰モデルとして君臨してきたが、Claude3の登場を機に、GPT-4を凌駕するモデルが続々登場する可能性が高まっている。OpenAI自体もGPT-4にとどまらず、後継モデル「GPT-5」の投入に向け動いているとの観測もある。
Mistralやメタを含め、各社の新モデル開発競争はさらに加速しそうだ。
文:細谷元(Livit)