
AIの新潮流、グラフ技術で”ウソ”をなくす ―― Diffbotのアプローチからみる展望
INDEX
LLMとナレッジグラフの融合、シリコンバレースタートアップの取り組み
AI言語モデル(LLM)の普及における最大の課題の1つが、モデルが生成する情報の正確性だ。モデルの精度は大きく向上しているものの、不正確な情報を生成してしまう「ハルシネーション」問題が依然としてつきまとっている。
この課題に対し、シリコンバレーのスタートアップDiffbotが新たなアプローチを提案、ハルシネーション対策の切り札になるとして注目を集めている。同社は2024年12月末、1兆以上の相互接続されたファクトを含むナレッジグラフと呼ばれるデータベースをリアルタイムで活用する新しいAIモデルを発表したのだ。
このモデルは、MetaのLLama 3.3をベースに、「GraphRAG(グラフ検索拡張生成)」と呼ばれるシステムを実装した初のオープンソースモデルとなる。同社のCEOであるマイク・タン氏は、「最終的に汎用推論モデルは約10億のパラメータに蒸留される」との見解を示す。知識をモデル内に保持するのではなく、外部の知識を検索・活用することで、モデルのサイズを縮小しても精度を高められるという考えだ。
Diffbotのナレッジグラフは、2016年からウェブをクロールし続けており、4〜5日ごとに数百万の新しいファクトで更新されるという。画像認識と自然言語処理を組み合わせ、ウェブページから人物、企業、製品、記事などの情報を構造化データとして抽出。モデルはこのリソースをリアルタイムで検索し、情報を取得する仕組みとなっている。
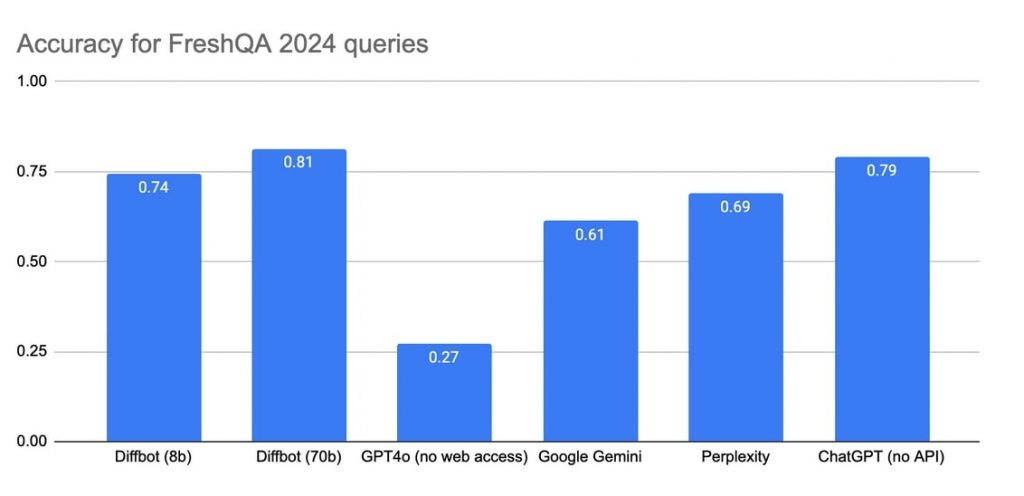
ベンチマークテストの結果も注目に値する。新しい情報に関する正確性を測るFreshQAテストで81%の精度を達成し、ChatGPT(79%)やPerplexity(69%)、またグーグルGemini(61%)を上回る成績を記録。また、学術知識を問うMMUL-Proでも72.89%のスコアを獲得し、ベースとなったLLama 3.3 70Bの65.92%を超えた。
実用面では、80億パラメータの小規模版は単一のNVIDIA A100 GPUで実行可能で、700億パラメータの完全版は2台のH100 GPUで動作する効率重視の設計となっている。モデルはGitHubで公開され、パブリックデモもdiffy.chatで利用可能だ。
従来のLLMが事前学習データに依存する形で発展してきたのに対し、Diffbotの取り組みは、外部知識の活用に重点を置く新たなアプローチの可能性を示すもの。グラフデータベースとの融合により、言語モデルがどのような進化を遂げるのか、Diffbotの開発動向が注目される。
グーグルも挑むハルシネーション対策、DataGemmaが示す可能性
グーグルもまた、ハルシネーション対策としてグラフデータベースを活用するアプローチに挑んでいる。同社のAIモデル「Gemma」をベースとしつつ、ナレッジグラフ技術を活用した「Data Commons」プラットフォームを連携させ、ファクトベースの回答生成を可能にする「DataGemma」を開発した。
Data Commonsは、2,400億以上のデータポイントを、現実世界のファクトとその関係性を組織化し、ナレッジグラフとして管理するデータベース。このデータベースを活用することで、経済、科学、健康など、様々な分野の信頼できる統計情報に基づいて回答を生成する仕組みを構築した。
DataGemmaの特徴は、2つの異なるアプローチを組み合わせている点にある。
1つは「Retrieval Interleaved Generation(RIG)」で、モデルが生成した回答とData Commonsに格納された関連統計を比較することで事実の正確性を向上させるアプローチ。
もう1つは「Retrieval Augmented Generation(RAG)」で、モデルが回答を生成する前にData Commonsから関連情報を取得し、回答を生成するアプローチ。
初期テストでは興味深い結果が得られている。RIGアプローチを用いたDataGemmaは、ベースモデル(Gemini1.5 Pro)で5〜17%だった事実の正確性を約58%まで向上させた。一方、RAGアプローチでは24〜29%の質問に対して統計的な回答を提供し、その99%で数値の正確性を担保した。
DataGemmaは現在、Hugging Faceで公開されており、学術研究目的での利用が可能だ。この公開により、RIGとRAGの両アプローチに関するさらなる研究が進み、より強力で信頼性の高いモデルの構築につながることが期待される。
このアプローチは、前述のDiffbotと同様に、グラフ構造を活用して外部知識を効率的に検索・活用する方向性を示している。大手テック企業からスタートアップまで、グラフ技術を活用したハルシネーション対策の取り組みが本格化しつつある。
グラフデータベースとはーーその仕組みと優位性
ハルシネーション対策の新たな切り札として注目を集めるグラフデータベースだが、どのような特徴を持つのか?
従来広く使用されてきたリレーショナルデータベース(RDBMS)との違いを理解することで、グラフデータベースの優位性が見えてくる。
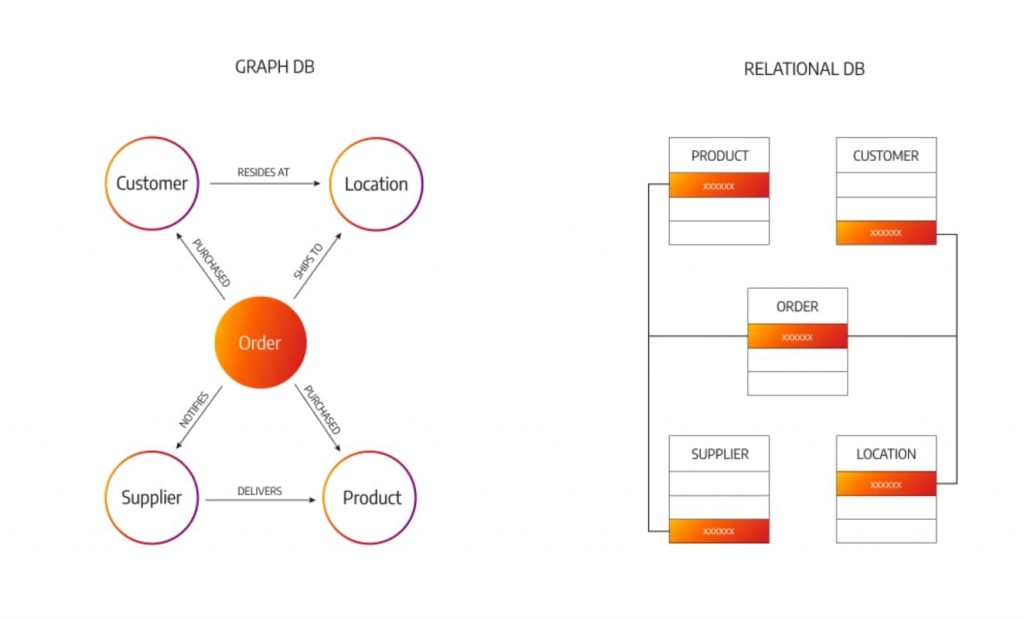
RDBMSは、データを行と列で構成されたテーブルに格納する。各行はレコードを、各列はそのレコードの属性を表現。身近な例で言えば、エクセルシートのような構造だ。「氏名」「年齢」「住所」などの列(カラム)と、1人の顧客情報などが入る行(レコード)で構成される。複数のデータテーブルは、プライマリーキーと外部キーを使用して関連付けられ、構造化クエリ言語(SQL)でデータを操作する。
一方、グラフデータベースは、データをノード(点)とそれらを結ぶリレーションシップ(エッジまたはリンク)の形で格納。ラベル付きプロパティグラフデータモデルに基づくグラフデータベースは、ノード、リレーションシップ、ラベル、プロパティの4つの要素で構成される。ラベルは類似したノードをグループ化する属性で、プロパティはノードやリレーションシップ内に格納されるキー/値ペアとなる。
memgraph.com代表的なグラフデータベースソフトを開発するNeo4jが実施したベクトルデータRAGとグラフデータRAGの比較は、その違いを理解する上で大いに役立つだろう。実験では、アップルのMac事業にどのような外部要因が影響を与えているかを、アップル四半期報告書から読み取る作業を行った。
従来の検索方式(ベクトル検索)では、「為替の変動」「供給の制約」「経済環境」といった基本的な要因しか見つけられなかった。一方、Neo4jのグラフ検索では、「新型コロナウイルス」「為替」「世界経済」「半導体不足」「物流の混乱」など、25個もの具体的な影響要因を特定することができた。
グラフ検索の優位性は、情報を「深く」「広く」分析できる点にある。
「深く」とは、たとえばアップルのティム・クック氏が示した売上数字が、どのような要因によって影響を受けているのか、その因果関係を詳しく追跡できる。「広く」とは、iPhoneの売上を起点に、世界各地域での販売状況や様々な経営指標まで、関連する情報を幅広く把握できることを意味する。
グラフ検索は情報同士の「つながり」を活用することで、より詳細で包括的な分析を可能にしているのだ。
このような優位性から、グラフデータベースの活用は今後さらに拡大すると予測されている。ガートナーは、2025年までにデータ分析ワークロードの80%でグラフ技術が活用されると予測。2021年の10%から大幅な増加が見込まれている。
文:細谷元(Livit)