
高速推論チップ開発のGroqが強力なビジュアル言語モデルLLaVA1.5 7Bの提供開始 その影響とユースケースとは?
INDEX
GroqがLLaVA1.5のAPIを公開、ビジュアル言語モデルの可能性
高速推論チップを開発するGroqが、ビジュアル言語モデルLLaVA1.5 7BのAPIをリリースした。このモデルは、LLaVA(Large Language and Vision Assistant)と呼ばれ、OpenAIのCLIPとメタのLlama 2 7Bモデルをベースに開発された最先端のマルチモーダルAIだ。
Groqは、このLLaVA 1.5 7B(llava-v1.5-7b-4096-preview)をGroqCloud Developer Consoleで提供開始したことを発表。これにより、GroqCloudはテキスト(Gemma2やLlama3.1など)、音声(Whisperモデル)に加え、画像にも対応できるプラットフォームに進化を遂げたことになる。
LLaVAの特徴は、視覚的指示に従う能力と視覚的推論能力を備えていることだ。画像内容に基づく質問応答(VQA)、画像の説明文生成、画像内のテキスト認識(OCR)、画像とテキストを組み合わせた対話などの機能を持つ。2023年9月時点で、LLaVA 1.5は5つの学術VQAベンチマークを含む計7つのベンチマークで最高水準の性能を達成しており、視覚入力に基づくテキスト理解・生成において卓越した能力を示している。
このモデルの実用的なアプリケーションは多岐にわたる。たとえば、小売業では店舗の棚画像から在庫レベルを追跡し、在庫切れ間近の商品を特定することが可能となる。ソーシャルメディアプラットフォームでは、画像の説明文を自動生成し、その情報を音声モデルで再生することで視覚障害を持つユーザーの画像内容理解を促進することもできる。カスタマーサービスチャットボットでは、テキストと画像の両方を含む対話を行い、顧客が製品について質問し回答を得ることが可能になるかもしれない。
産業別の具体的な活用例も挙げられる。製造ラインでは、製品の検査や欠陥の特定を行い、品質管理エンジニアの品質管理プロセスを自動化できる。また金融分野では、請求書や領収書などの財務文書を監査し、会計や簿記タスクの自動化を支援する。小売業では、製品パッケージやラベルなどの製品画像を分析し、在庫管理や製品推奨タスクの自動化が可能になる。さらに教育分野では、図表やイラストなどの教育用画像を検証し、学生がより効果的かつ効率的に学習できるよう支援する仕組みも構築できる可能性がある。
そもそもLLaVAとは?分かりやすく解説
冒頭でも述べたがLLaVA(Large Language and Vision Assistant)は、OpenAIのCLIPとメタのLlama 2 7Bモデルを基に開発された先進的なマルチモーダルAIだ。
CLIPとは、Contrastive Language-Image Pre-trainingの略で、OpenAIが開発した画像と言語を結びつけるマルチモーダルモデル。CLIPは大量の画像とそれに関連するテキストのペアを学習することで、画像と言語の間の関連性を理解し、幅広い視覚タスクに適用できる汎用的な能力を獲得している。
一方、Llama 2は、メタが開発した大規模言語モデル(LLM)。Llama 2は様々なサイズで提供されており、その中でも7Bモデル(70億のパラメータを持つモデル)は、比較的小規模ながら高い性能を示すことで知られている。Llama 2は幅広いテキスト生成タスクに対応可能で、特に指示に従う能力に優れている。
CLIPの視覚理解能力とLlama 2の言語処理能力を統合することで、LLaVAは画像理解と言語生成を高度に組み合わせたタスクを遂行することが可能となっている。
LLaVAの主要機能は以下の4つ。
1つ目は画像内容に基づく質問応答(VQA)だ。たとえば、画像中の特定の物体の色や数を問う質問に答えることができる。2つ目は画像の説明文生成で、提示された画像の内容を自然言語で詳細に記述する。3つ目は画像内のテキスト認識(OCR)能力で、画像中に含まれる文字や数字を読み取ることができる。そして4つ目は、画像とテキストを組み合わせた対話能力だ。ユーザーが画像に関連した質問をすると、LLaVAはその画像を参照しながら適切な回答を生成する。
LLaVAの柔軟性は、様々な形式の指示に対応できる点にも表れている。同モデルのテクニカルレポートでは、LLaVA1.5に対し「質問に事実誤認がある場合は指摘し、そうでなければ質問に答えてください」という複雑な指示を与えた場合でも、しっかりと内容を理解し、適切な回答を生成できたことが報告されている。たとえば、ハワイのコーストラインの画像を示しつつ、「この砂漠で何が起こっているのか説明してください」というトリッキーな質問をしても、LLaVA1.5は「この画像には砂漠は映っていない」と回答できることが確認されている。

https://arxiv.org/pdf/2310.03744
また、「この画像内のテキストを読み、以下のJSON形式で情報を返してください」といった構造化されたアウトプットの要求にも応じることができる。これらの機能により、LLaVAは単なる画像認識や質問応答を超えた、より高度で柔軟な視覚言語タスクを遂行することが可能となっている。

https://arxiv.org/pdf/2310.03744
LLaVAの開発においては、視覚的指示チューニングという手法が用いられている。これは、モデルに多様な視覚タスクを遂行させるための指示を与え、その結果を基にモデルを調整するプロセスだ。この手法により、LLaVAは単なる画像認識や自然言語処理を超えた、より柔軟で高度な視覚理解能力を獲得したという。
ただし、LLaVAにも課題がある。特に、主に短い回答を要求する学術的なベンチマークでは、他のモデルに劣る傾向がある。画像に映っているオブジェクトの名称のみを回答するのが難しいのだ。たとえば、丘の上に人が座り、遠くに橋が見える画像を与え、「オブジェクトを検出してください」と指示しても、「橋、人」などと短い回答を生成できない。この場合、ファインチューニングが必要となる。
また、はい/いいえ形式の質問に対しては、訓練データの分布の影響で「はい」と答える傾向が強いという課題も指摘されている。
これらの特徴と課題を踏まえつつ、LLaVAは視覚と言語を統合した高度なAIアシスタントとして、様々な分野での応用が期待されている。
強みから考察するユースケース
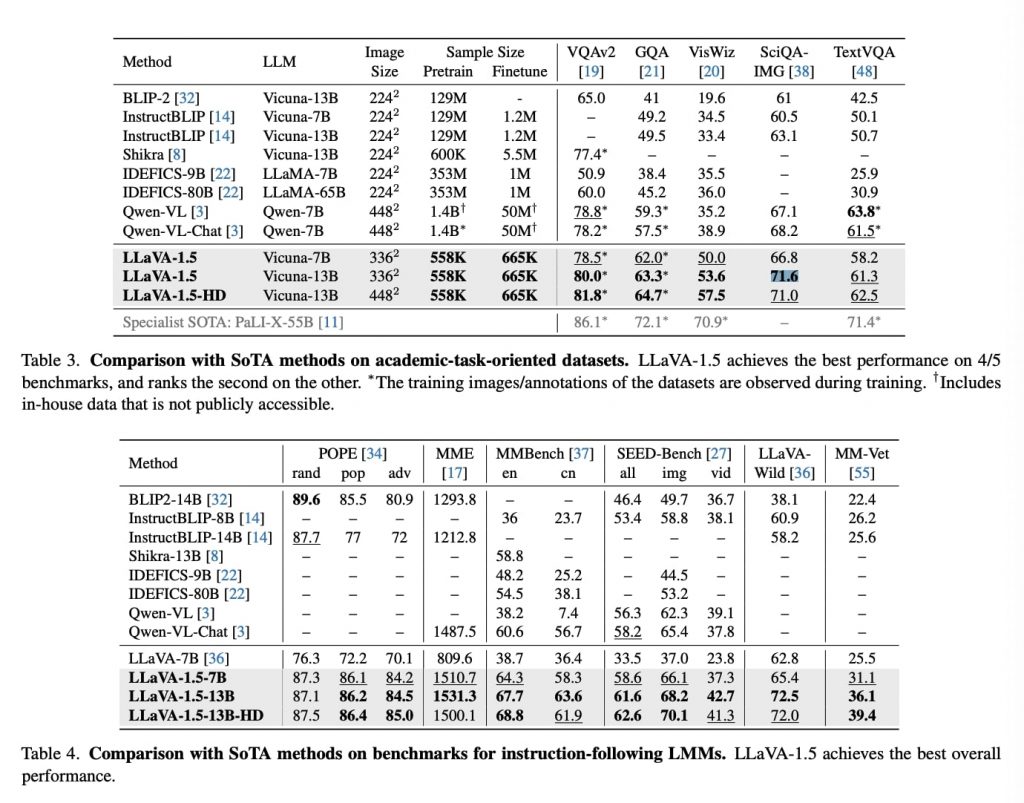
LLaVA1.5の強みは、その多様な機能と高い性能にある。特に金融、製造、小売業界におけるユースケースを、ベンチマーク数値を交えて詳細に考察してみたい。
まず金融業界では、LLaVA1.5の高度なOCR(光学文字認識)能力と言語理解能力が大きな価値を持つ。TextVQAベンチマークにおいて、LLaVA-1.5(13B)は61.3%のスコアを達成。これは多くの競合モデルを上回る性能だ。この高い性能は、請求書や領収書、金融文書の自動監査に直接応用できる。たとえば、複雑な金融文書から重要な情報を抽出し、不正や異常を検出するシステムの構築が可能となる。さらに、SciQA-IMGベンチマークでの71.6%という高スコアは、LLaVAが複雑な金融データの分析や解釈にも適していることを示唆している。これにより、投資分析や市場予測などの高度な金融タスクにおいても、LLaVAの活用が期待できる。
製造業界では、LLaVA1.5の視覚認識能力と推論能力が品質管理プロセスを革新する可能性がある。VQAv2ベンチマークでの80.0%という高スコアは、LLaVA1.5が製品の詳細な視覚的特徴を正確に認識できることを示している。これは製造ラインでの製品検査に応用可能で、製品の欠陥を高精度で検出し、その原因を分析するシステムを構築することができるかもしれない。また、GQAベンチマークでの63.3%というスコアは、LLaVA1.5が複雑な視覚的関係性を理解できることを示しており、これは製造プロセス全体の最適化に活用できる。製造工程の各段階を視覚的に分析し、効率化の提案を行うシステムの開発が考えられる。
小売業界においては、LLaVA1.5の多様な機能が革新的なソリューションを提供する可能性がある。VisWizベンチマークでの53.6%というスコアは、LLaVA1.5が実世界の複雑な視覚的質問に対応できることを示している。店舗内の商品配置の最適化や、顧客の購買行動分析に応用できる可能性を示唆する数値といえるだろう。また、MMEベンチマークでの1531.3点という高スコアは、LLaVAが複雑な視覚的タスクを高精度で遂行できることを示している。たとえば、棚画像から商品の在庫状況を正確に把握し、自動的に発注を行うシステムの開発などが考えられる。
さらに、これら3つの業界を横断する形で、LLaVA1.5の高度な対話能力も注目に値する。LLaVA-Benchでの72.5%というスコアは、LLaVA1.5が自然な対話を通じて複雑なタスクを遂行できることを示している。これは、金融アドバイザー、製造プロセスコンサルタント、小売店の仮想アシスタントなど、様々な形で活用できる可能性を示唆するもの。顧客の質問に画像と言葉で応答する高度な顧客サービスシステムの構築などが可能となるかもしれない。
https://arxiv.org/pdf/2310.03744
Groq CloudでLLaVA1.5を実際に使ってみる
Groq CloudでLLaVA1.5を実際に試すことができる。
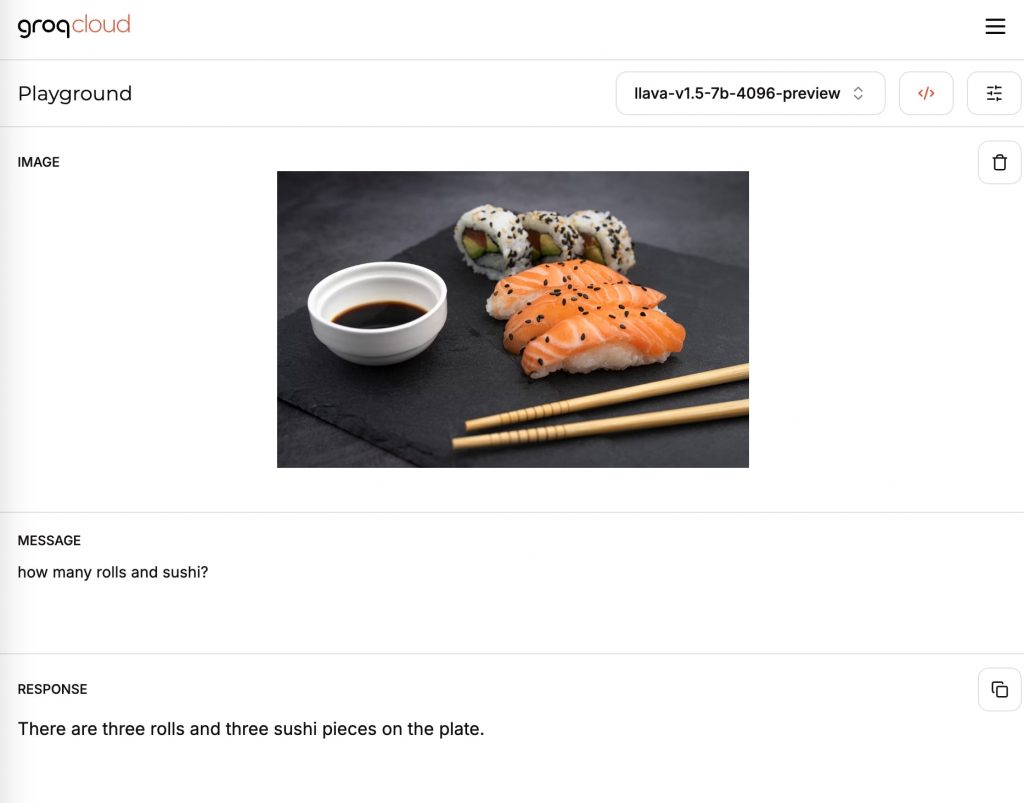
たとえば、以下の寿司の写真を与え「how many rolls and sushi?」という質問を与えてみる。
回答は「巻き寿司が3つ、寿司(にぎり)が3貫」と、巻きずしとにぎり寿司を分類し、正確に寿司の数を答えることができた。
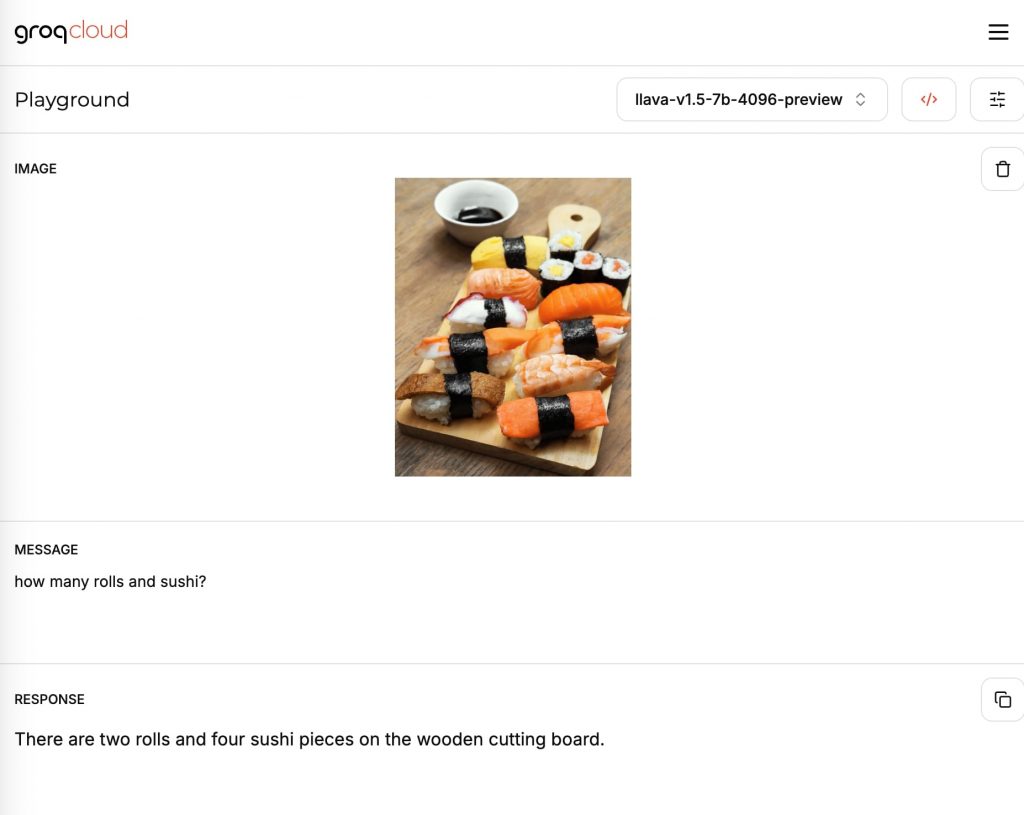
次にもう少し複雑な画像を与えてみた。プロンプトは上記と同じ「how many rolls and sushi?」。
回答は「巻き寿司が2つ、にぎり寿司が4貫」と不正確なものとなった。
ただし、仮に寿司に特化したシステムを構築する場合、寿司の画像でファインチューニングするのが定石。ファインチューニングすれば、精度は大幅に上昇するはずだ。
ビジュアル言語モデル領域では、Mistralの最新モデルPixtralのほか、マイクロソフトのFlorence2、グーグルのPaliGemmaなども有力モデルとして人気を集めている。ビジュアル言語モデルをめぐる開発競争、またGroqのようにクラウドで提供する動きはますます活発化することが見込まれる。
文:細谷元(Livit)