

基盤モデルの開発には巨額投資が必須、メタとxAIが示す現実
人工知能(AI)の基盤モデル開発において、巨額の設備投資は避けられないのが現実となっている。AP通信によると、メタは2024年末、同社最大のAIデータセンターをルイジアナ州に建設する計画を明らかにした。投資額は100億ドル(約1兆5,000億円)規模で、データセンターの面積は37万平方メートルに及ぶという。
一方、テスラとxAIを率いるイーロン・マスク氏も、2024年だけでAIトレーニング用ハードウェアに約100億ドルを投じている。メンフィスのスーパークラスターには10万基のH100 GPU(NVIDIAの最新AI向けプロセッサ)を導入。GPUの調達コストだけで約20億ドルに上る。さらに新たに5万基のH100 GPUと5万基のH200 GPUを追加導入し、計20万基のGPUを稼働させる計画だ。
こうした大規模投資の背景には、AIトレーニング需要の急増がある。米商務省のまとめによると、AIによるデータセンター需要は2030年まで年率9%で増加する見込み。米国内のデータセンター供給がAI関連の需要に追いつかない状況がしばらく続くとみられている。
これらのデータセンター運用にかかる電力や水関連インフラ費用も無視できない。
メンフィスのスーパークラスターは、H100 GPUクラスターのみで70メガワット、システム全体では150メガワットもの電力を消費する。2024年7月時点の情報によると、マスク氏は、この電力を14基のディーゼル発電機でまかなっているとされる。
一方メタは、データセンターに関わる道路と水関連のインフラ整備に2億ドルを投資する計画。また電力に関しては、米電力大手エンタジーと提携し、15年間にわたり2,262メガワットの発電能力を確保する見込みだ。同社の総発電能力の約1割を占める規模の天然ガス発電所3基の建設を計画している。
こうした巨額投資と電力消費の実態は、大規模言語モデル(LLM)開発の現状を如実に物語る。マスク氏が「このレベルの投資を効率的に行えない企業は、競争に参加できない」と指摘するなど、参入障壁の高さが際立つ。
DisTrOで実現する分散型トレーニング、通信帯域を最大1万分の1に削減
一方、従来とは異なるアプローチの研究開発も進んでおり、上記のような巨額投資なしでも、基盤モデル開発ができるようになる可能性も高まっている。
その1つが、Nous Researchが開発している「Distributed Training Over-the-Internet(DisTrO)」と呼ばれる技術(2024年8月発表)だ。簡単に言うと、インターネットを通じて、計算処理を分散し、高価なGPUクラスターなしでも、AIモデルのトレーニングを可能にするテクノロジー。その中核を成すのが、分散化する際のボトルネックとなるGPU間の通信帯域幅を大幅に削減するアルゴリズムで、一般的なインターネット回線でもモデルのトレーニングを可能にする。
たとえば、従来の手法では74.4ギガバイトのデータ送受信が必要だったのに対し、DisTrOでは86.8メガバイトまで削減、約878倍もの効率化を実現した。さらに、ポストトレーニングやファインチューニングの段階では、性能を損なうことなく最大1万倍の効率化も可能とされる。


https://github.com/NousResearch/DisTrO/blob/main/A_Preliminary_Report_on_DisTrO.pdf
研究チームによると、DisTrOは、このような効率化を実現しながらも、モデルの性能を大きく損なうことはないという。テストでは、12億パラメータのLLMを従来手法とDisTrOでそれぞれトレーニングし、性能を比較。その結果、DisTrOを使用しても従来手法と同等の収束率を達成することが確認された。
Nous Researchの研究は、DisTrOがLLM以外の大規模モデルでも使用できる可能性を示している。特に画像生成AIとして知られるStable DiffusionのようなLarge Diffusion Model(LDM)のトレーニングにも応用できるとしており、今後の展開が注目されている。
150億パラメータのLLMを世界中で分散トレーニング、Nous Researchが実証実験
2024年8月のレポートで、理論上の可能性が示されたDisTrOだが、Nous Researchは実際に世界中に配置された機器を使用し、150億パラメータ規模のLLMの分散トレーニングに着手している。
同社は、専用ウェブサイト(distro.nousresearch.com)で、リアルタイムのトレーニング進捗状況を公開。このトレーニングは2024年12月初旬に完了した模様だ。

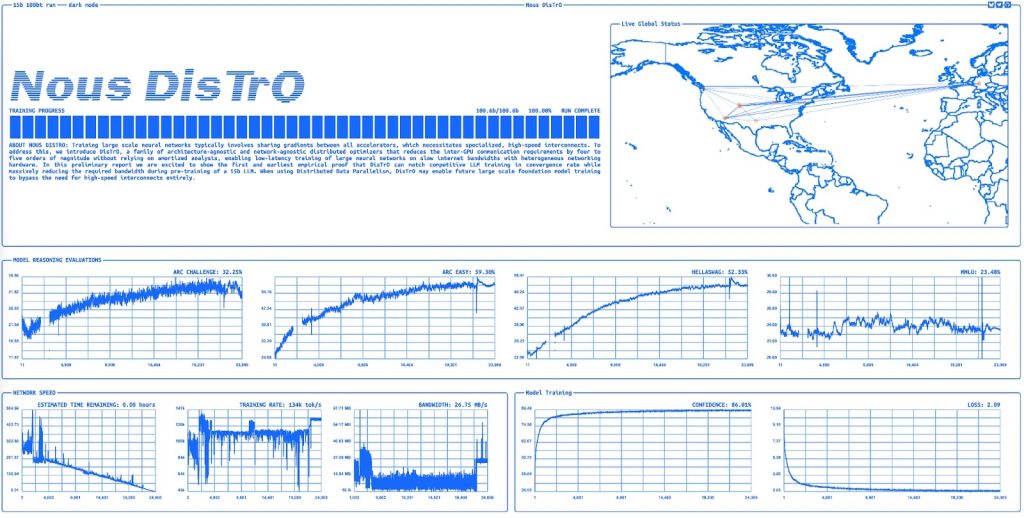
https://distro.nousresearch.com/
トレーニングに使用されるハードウェアの所在地を示す地図も公開しており、米国および欧州の複数拠点で処理が行われていたことが確認できる。プレトレーニングにかかった時間は約230時間と推定される。
この取り組みには、オラクル、Lambda Labs、Northern Data Group、Crusoe Cloudといった企業が参画。実世界での分散環境でDisTrOの性能を検証するために必要な異機種混合ハードウェアを提供した。また、Adam最適化アルゴリズムの共同発明者であるディーデリック・P・キングマ氏が、DisTrOの開発にコラボレーターとして参加していることも同プロジェクトが注目される理由の1つとなっている。
現状、このデモンストレーションではエヌビディアのH100など最新のGPUが使用されているが、Nous Researchはより一般的なハードウェアへの展開も視野に入れ、開発を進めているという。今後の展開として、連合学習(フェデレーテッドラーニング)や画像生成用のディフュージョンモデルのトレーニングなど、幅広い応用が期待される。
文:細谷元(Livit)