
テキストだけでなく画像や音声なども処理するマルチモーダルRAG、AIの検索回答精度の大幅改善に期待
INDEX
マルチモーダルRAGとは、通常のRAGと何が違うのか?
企業データの90%が非構造化データであり、その80%以上が画像、動画、音声、テキスト文書で構成されているという現状がある。
このような多様なデータを効果的に活用するためのアプローチとして、マルチモーダルRAG(Retrieval Augmented Generation)が注目を集めている。マーケッツ・アンド・マーケッツの調査によれば、マルチモーダルAI市場は年平均成長率35%で拡大し、2028年までに45億ドル規模に達する見込みだ。
従来のRAGがテキストデータのみを処理対象としていたのに対し、マルチモーダルRAGは、テキスト、画像、音声、動画など、複数の形式のデータを同時に処理する能力を持つ。たとえば、顧客サービスの現場では、製品の不具合を示す写真、音声による問題の説明、アプリのエラーメッセージのスクリーンショットなど、異なる形式の情報が寄せられる。マルチモーダルRAGは、これらの情報を総合的に理解し、文脈に即した回答を生成できる。
マルチモーダルRAGの革新性は、人間が自然に行っているように、見る、聞く、読むという複数の情報を総合的に理解し、そこから適切な回答を導き出せる点にある。これにより、より人間らしい正確な情報処理と対話が可能となる。
マルチモーダルRAGシステムの中核を担うのが、マルチモーダルエンコーダーだ。これは画像、テキスト、音声といった異なる形式のデータを統一的なベクトル表現に変換し、効率的な比較や検索を可能にする仕組み。テキストと画像領域の関連付けや、音声トランスクリプトと視覚コンテンツの対応付けなど、異なるデータ形式間の関係性の理解も可能となる。
検索システムは、ベクトルデータベース内から入力クエリに最も関連性の高い情報を抽出。セマンティック検索とキーワード検索を組み合わせたハイブリッドアプローチにより、文脈に即した結果を提供する。最後に、大規模言語モデル(LLM)が、取得した複数形式の情報を統合し、人間が理解しやすい形で出力する仕組みとなっている。
このように、マルチモーダルRAGは、企業が保有する多様なデータを統合的に活用するための基盤技術として期待を集めている。次のセクションでは、この分野で注目を集めるCohereの取り組みを詳しく見ていきたい。
マルチモーダルRAG分野の取り組み、Cohereの事例
マルチモーダルRAG分野で存在感を示しているのが、企業向けの生成AI開発で定評を得るCohereだ。
Cohereが2024年10月に発表したエンベディングモデル「Embed 3」は、テキストに加え画像の処理を可能とするもので、企業のマルチモーダルRAGアプリケーション開発をさらに前進させる存在として関心を集めている。
Embed 3の最大の特徴は、テキストと画像のエンベディングを同一のベクトル空間に配置する点にある。これにより、企業は既存のテキストデータを再ベクトル化する手間やコストを回避できる。また、他のモデルがテキストと画像データを異なるクラスターに分離する傾向があるのに対し、Embed 3は両者の意味的な関係性を保持しながら、バランスの取れた処理を実現。検索結果がテキストや画像に偏ることなく、最も関連性の高い情報を提供できる。
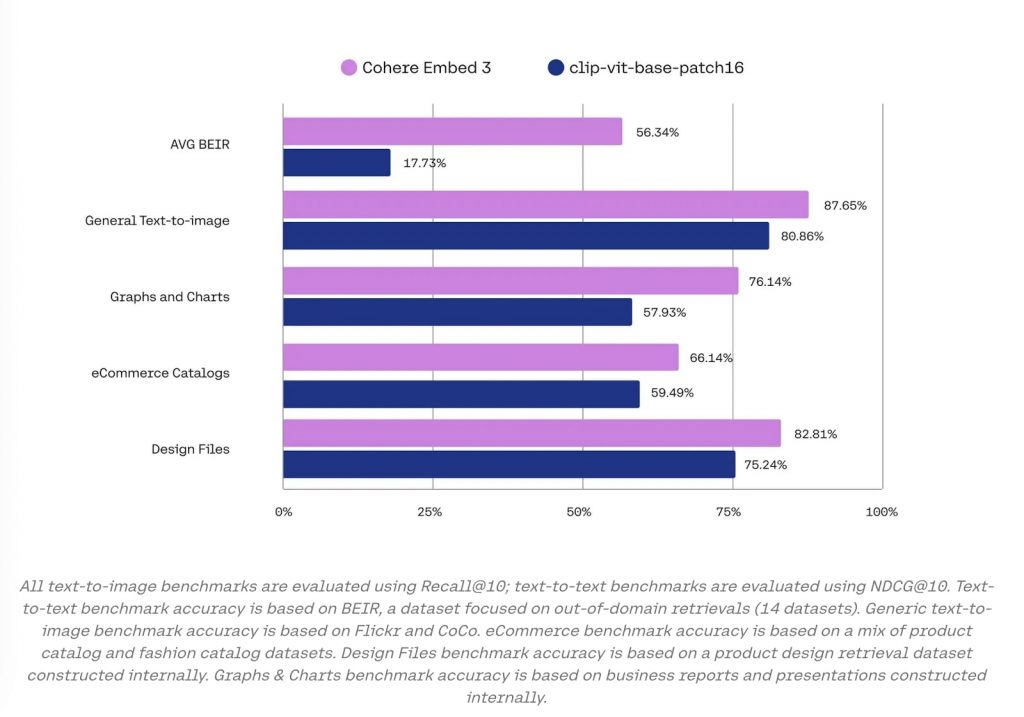
この優位性は、具体的な数値でも実証されている。Embed 3は、画像とテキストの関連付けにおいて、業界標準とされるCLIPモデルと比較して、すべての分野で高いパフォーマンスを示した。たとえば、ビジネスレポートやプレゼンテーションで頻繁に使用されるグラフやチャートの理解では、Embed 3が76%の精度を達成し、CLIPの58%を大きく上回る。これは実務上、「売上推移グラフを見せながら『先月の売上が急増した理由を説明して』と質問した際に、より正確な回答が得られる」ことを意味する。
また、Eコマースでの商品検索においても、Embed 3は66%の精度を実現。「この商品と似たデザインで、もう少し安いものを探して」といった、画像と文章を組み合わせた複雑な検索要求に、より正確に対応できる。さらに、一般的な画像認識タスクでは88%という高精度を記録しており、「この写真のような雰囲気の部屋の内装例を探して」といった、感覚的な検索にも強みを発揮する。
https://cohere.com/blog/multimodal-embed-3?ref=cohere-ai.ghost.io
具体的な活用例として、小売業界でのユースケースが挙げられる。Embed 3を活用することで、商品の視覚データ、テキスト情報、価格データを統合し、より的確なパーソナライズドレコメンドを実現できる。顧客の閲覧パターンから特定のデザインや価格帯の選好を検知し、類似商品を提案することが可能だ。また、コンサルティング企業では、テキスト、画像、グラフを組み合わせたプレゼンテーション資料から必要な洞察を抽出し、カスタマイズされた提案書の作成に活用するなどのユースケースも想定される。
医療分野における活用も期待される。Embed 3を用いることで、医療機関は診療記録や検査結果、MRIスキャンなどの画像データを統合的に分析できるようになる。また、異なるデータタイプ間のパターンを発見する上でも有用となるため、疾病の症状や治療法についてより深い洞察を得られる可能性も高まる。
一方、マルチモーダルRAGシステムの開発においては、通常のRAGに比べ、データ準備に一層の注意を払う必要がある。テキストだけでなく、画像データも含まれるためだ。
たとえば、Embed 3を使う場合、画像のサイズ調整による一貫性の保持が必須となる。低解像度の画像は重要な詳細が失われる可能性があり、一方で高解像度画像は処理時間とメモリに負荷をかける。企業はニーズに応じて適切なバランスを見出す必要がある。また、検索結果の関連性と文脈を改善するため、画像に詳細なメタデータを付与することも重要だ。医療分野など特殊な用途では、追加のトレーニングが必要となる場合もある。放射線スキャンや顕微鏡写真といった専門的な画像は、その微細な違いを理解するための特別なエンベディングシステムを要する。
Cohereは、主要小売業者との協業で、4日間で7億点以上のアイテムのインデックス化に成功。顧客の検索機能を大幅に向上させた実績を持つ。ただし、処理時間はインフラ能力など、さまざまな要因に左右される点に注意が必要だ。パフォーマンス評価には、従来のキーワードベース検索との比較や、2つのバージョンを展開してA/Bテストを実施するなど、人間による評価と自動評価の組み合わせが有効とされる。
マルチモーダルRAG分野の取り組み、Uniphoreの事例
会話型AIとオートメーションソリューションを開発するUniphoreも注目株の1つ。
同社はこのほど、マルチモーダルデータセットを活用し、ドメイン特化型AIアプリケーションを従来の8倍のスピードで構築できるプラットフォーム「X-Stream」をリリースした。
同社のウメシュ・サチデブCEOがVentureBeatに語ったところによると、企業のデータ責任者らは、音声、動画、テキストにまたがるデータセットから、より効率的に知識変換を実現する方法を求めているという。従来のRAGアプリケーション開発では、構造化された表から非構造化のテキスト会話、文書、動画まで、さまざまな形式の情報を統合する必要があった。そのため、データウェアハウスやERP、HCM、内部アプリなどへの接続に複数のデータコネクタやETLツールが必要となり、プロジェクトの完了までに数カ月を要していたという背景がある。
X-Streamは、200以上のソースからマルチモーダルデータを取り込み、インテリジェントなマージと変換ジョブを実行してAI対応のデータに変換する。パース処理とチャンキング、エンベディングへの変換、ベクトルデータベースへの格納までを一貫して行う。さらに、文脈と推論が必要な場合はナレッジグラフを生成し、特定のユースケースや業界向けにモデルを微調整するための合成データを作成することも可能だ。
同社の強みは、16年にわたる音声、動画、テキストなど、非構造化データの取り扱い経験にある。現在、DHL、アクセンチュア、ゼネラルインシュアランスなど、1,500社以上の企業と取引を展開。導入企業は稼働開始から数週間で4〜6倍の投資収益率を達成しているという。
現在、生成AI領域では「AIエージェント」がホットトピックとなっているが、「マルチモーダルRAG」も2025年の重要キーワードになっていくことが予想される。
文:細谷元(Livit)