
AIエージェントの発展とRAGの新境地、「エージェンティックRAG」が注目される理由
INDEX
既存RAGの課題、ハルシネーションやコンテキスト理解不足など
企業における生成AI活用では、情報の正確性が特に重視される。そのため、生成AIを利用する場合、検索拡張生成(RAG)の導入が一般的となっている。RAGとは、生成AIに外部データベースを接続することで、より正確な回答を生成する手法。RAGは特に文書要約やシンプルなクエリへの回答で優れたパフォーマンスを発揮するといわれている。
しかし、既存のRAGシステムには、いくつかの課題が存在する。課題は大きく4つに分類される。
第1の課題は、RAGだけでは情報の正確性が担保できないことだ。たとえば、営業担当者が商談の売上を問い合わせた場合、チャットログやメール、CRMなど、複数のデータソースが参照対象に含まれる。この場合、CRMが最も信頼できる情報源となるはずだが、RAGシステムは、自律的にそのことを判断できないため、古いメールから誤った情報を引用してしまう可能性がある。
第2の課題は、ハルシネーションの問題。生成AIの特徴である自然な文章生成能力は、時として正確さを損ねる原因にもなる。生成AIは、データの要約時に、情報を歪曲したり、存在しない事実を追加したりする傾向があるためだ。RAG活用により、ハルシネーションの可能性は下がるとされるが、完全にハルシネーションリスクを排除することは難しいのが現状となっている。
第3の課題は、企業固有のコンテキストを理解できない点が指摘される。企業では、固有の用語や略語が頻繁に使用される。しかし、RAGシステムは企業固有のコンテキストを持たないため、これらの用語をキーワードとして扱うか、さらには誤ったスペルとして補正してしまう可能性がある。
第4の課題は、スケーラビリティの問題。企業の情報システムには、テラバイトからペタバイト規模のデータが存在する。数十億のファイルやドキュメントから構成される膨大なデータを、既存のRAGシステムで効率的に処理することは難しい。検索時に関連性の高い文書を適切に抽出できなければ、生成AIは情報を正しく要約することができず、誤ったアウトプットを出力してしまう可能性が高まる。
これらの課題は、基本的なRAGシステムでは解決が困難といわれる。そこで注目されているのが、AIエージェントの仕組みを組み込んだ「エージェンティックRAG」だ。
既存RAGの課題解決で注目されるエージェンティックRAGとは?
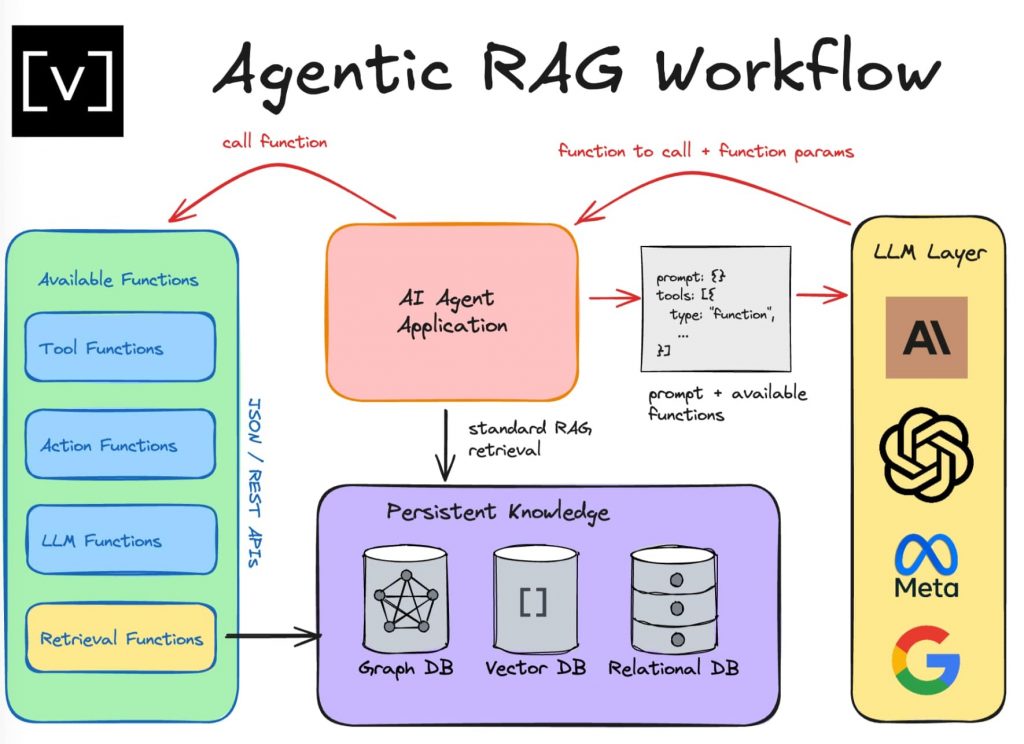
エージェンティックRAGは、AIエージェントをRAGパイプラインに組み込むことで、情報検索と生成の精度を向上させる手法である。このアプローチは2024年に入り、エージェントシステムの発展に伴い、大きな進展を見せており、投資・開発動向はさらに活発化する見込みだ。
エージェンティックRAGの最大の特徴は、AIエージェントの自律的な判断能力にあるといえるだろう。AIエージェントは、LLM(大規模言語モデル)をベースに、メモリ機能、プランニング機能、そして外部ツールへのアクセス機能を備えている。これにより、単純な情報検索と生成を超えた、より高度な情報処理が可能となる。
代表的なAIエージェントの1つがReActと呼ばれるフレームワークだ。ReActは「Reason(推論)+Act(行動)」の略で、AIエージェントがユーザーのクエリに対して以下の3つのステップで対応する。まず「Thought(思考)」でクエリの意図を理解し、次のアクションを決定。次に「Action(行動)」で、決定したアクションを実行。最後に「Observation(観察)」でアクションの結果を評価する。このプロセスを、タスク完了まで繰り返す。
エージェンティックRAGのアーキテクチャには、シングルエージェントとマルチエージェントの2つのパターンが存在する。シンプルな構成のシングルエージェントは、複数の情報ソースから最適なものを選択するルーターとして機能する。一方、マルチエージェントでは、情報検索を統括するマスターエージェントの下に、社内データ、メール、チャット、ウェブ検索など、それぞれの情報ソースに特化したエージェントを配置する。
このようなアーキテクチャにより、エージェンティックRAGは従来のRAGシステムにない柔軟性と機能性を実現。クエリの意図を理解し、適切な情報ソースを選択することが可能だ。また、必要に応じて複数のステップに分解し、各ステップで最適なツールを使用することで、より正確で信頼性の高い回答を生成できるようにもなる。
エージェンティックRAGをめぐる最新動向
エージェンティックRAGに特化したスタートアップも登場しており、実用化/普及の速度は今後さらに加速する公算だ。VentureBeatの報道(2024年10月8日)によると、スタートアップのVectorizeが360万ドルのシード資金を調達し、エージェンティックRAGプラットフォームの一般提供を開始する。同社のプラットフォームは、リアルタイムのデータ処理に対応したエージェンティックRAGの実装を可能にするという。
Vectorizeが焦点を当てるのは、データエンジニアリングの自動化。同社のクリス・ラティマー氏(CEO兼共同創業者)はVentureBeatの取材で、生成AIプロジェクトの多くが、ベクトルデータベースに格納される情報のコンテキスト不足により、ハルシネーションや誤った解釈に悩まされていると指摘している。Vectorizeは、非構造化データの取り込みから最適化まで、エンタープライズRAGのデータパイプラインを自動構築する機能を提供することで、この課題の解決を目指す。
https://vectorize.io/how-i-finally-got-agentic-rag-to-work-right/
すでに同社のエージェンティックRAG機能は、AI推論チップ開発のGroqによって実践投入されている。Groqは、Vectorizeのデータパイプラインを活用したAIサポートエージェントを開発。このエージェントは、過去に類似の質問があった場合、その情報を参照しつつ、人間を介さずに問題を解決できるという。一方で、エージェントが解決できない問題が発生した場合は、人間のオペレーターに引き継ぐ仕組みも備えている。
VectorizeのRAGプラットフォームでは、企業のデータ鮮度に合わせて、ベクトルデータベースの更新頻度を柔軟に設定することも可能だ。週1回の更新、リアルタイムの更新など、ニーズに応じた設定ができるという。ラティマーCEOは「古いデータは古い意思決定につながる」と指摘し、データ更新のタイミングが重要であることを強調する。
Vectorizeのプラットフォームは、ベクトルデータベースやベクトル埋め込み技術そのものを提供するものではない。代わりに、Pinecone、DataStax、Couchbase、Elasticなどの既存のベクトルデータベースと接続し、非構造化データの取り込みと最適化を担う。また、OpenAIのadaやVoyage AIなど、さまざまなベクトル埋め込みモデルを使用できる柔軟性も備えている。
AIモデル自体の進化速度は若干鈍化しているといわれるが、AIエージェントシステムの発展余地はまだ大きい。AIエージェントの進化に伴い、エージェンティックRAGがどのように発展していくのか、今後の注目ポイントとなる。
文:細谷元(Livit)