

リクイッド・ファウンデーション・モデル(LFM)とは、その概要
マサチューセッツ工科大学(MIT)のコンピュータ科学・人工知能研究所(CSAIL)の元研究者によって設立されたLiquid AIが、新たなマルチモーダルAIモデル「リクイッド・ファウンデーション・モデル(LFM)」を発表した。LFMの最大の特徴は、2017年の論文「Attention Is All You Need」で提唱されたトランスフォーマーアーキテクチャに依存しない点にある。
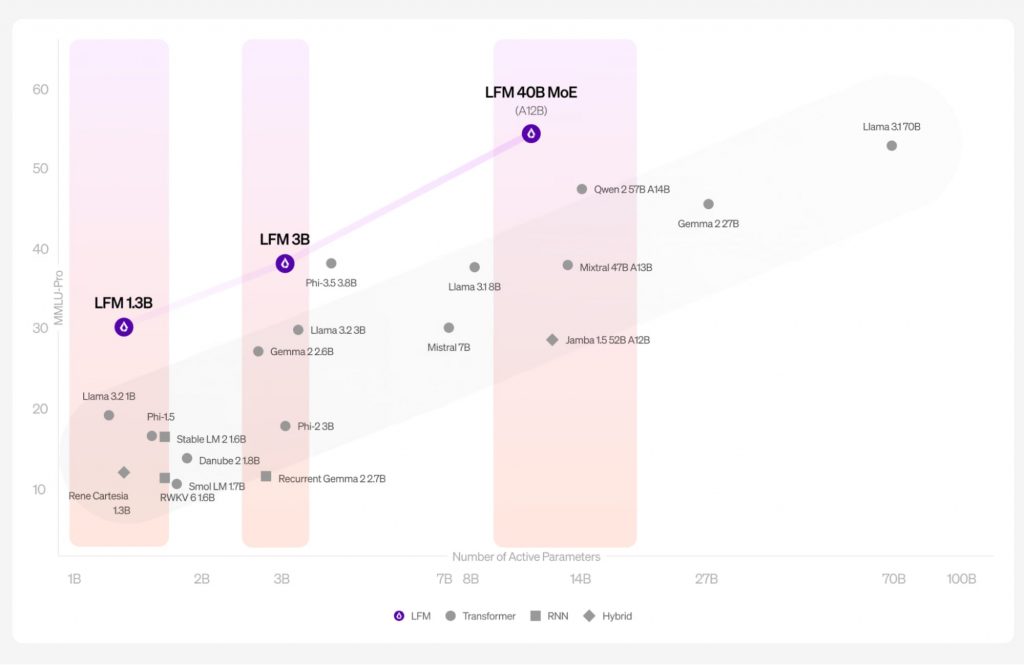
Liquid AIは、「エンジニアが自動車や飛行機を設計したのと同じように、基本原理から設計する」という理念を掲げており、実際にそれを実現した格好となる。現在、LFMは3つのサイズとバリエーションで展開されている。最小の「LFM 1.3B」、中規模の「LFM 3B」、そしてMistralのMixtralに似た「Mixture-of-Experts」モデルである「LFM 40B MoE」の3種類。
モデル名の「B」は10億(billion)を表し、モデルの情報処理、分析、出力生成を制御するパラメータ数を示している。一般的に、パラメータ数が多いモデルほど、より広範なタスクをこなすことが可能となる。
Liquid AIによると、LFM 1.3Bは、科学、技術、工学、数学(STEM)分野にわたる57の問題で構成される人気ベンチマーク「Massive Multitask Language Understanding(MMLU)」において、メタの新しいLlama 3.2-1.2BやマイクロソフトのPhi-1.5を上回るパフォーマンスを示した。10億パラメータ規模のモデルとして、非GPTアーキテクチャがトランスフォーマーベースのモデルを大きく上回った初の事例となる。

https://www.liquid.ai/liquid-foundation-models
3つのモデルは、いずれもメモリ効率を最適化するように設計されている。Liquid AIのポストトレーニング責任者であるマキシム・ラボン氏は、自身のXアカウントで、LFMの主な利点として、大幅に少ないメモリ使用量でトランスフォーマーベースのモデルを上回るパフォーマンスを発揮する点を強調している。
これらのモデルは、ベンチマークテストだけでなく、実際の運用面でも競争力を持つように設計されており、金融サービス、バイオテクノロジー、家電製品など、エンタープライズレベルのアプリケーションからエッジデバイスへの展開まで、幅広いユースケースに対応できる。ただし、これらのモデルはオープンソースではなく、ユーザーはLiquidのインファレンスプレイグラウンド、Lambda Chat、またはPerplexity AIを通じてアクセスする必要がある点に留意が必要だ。
LFMとトランスフォーマーモデルとの違い
従来のトランスフォーマーモデルを超えるLFMは、どのような特徴を持つのか。
Liquid AIによると、LFMは動的システム理論、信号処理、数値線形代数に深く根ざした計算ユニットを組み合わせて構築されているという。また、LFMは汎用目的のAIモデルとして設計されており、ビデオ、音声、テキスト、時系列データ、信号など、あらゆる種類のデータをモデル化することが可能。この柔軟性は、従来のトランスフォーマーベースのモデルにはない特徴となっている。
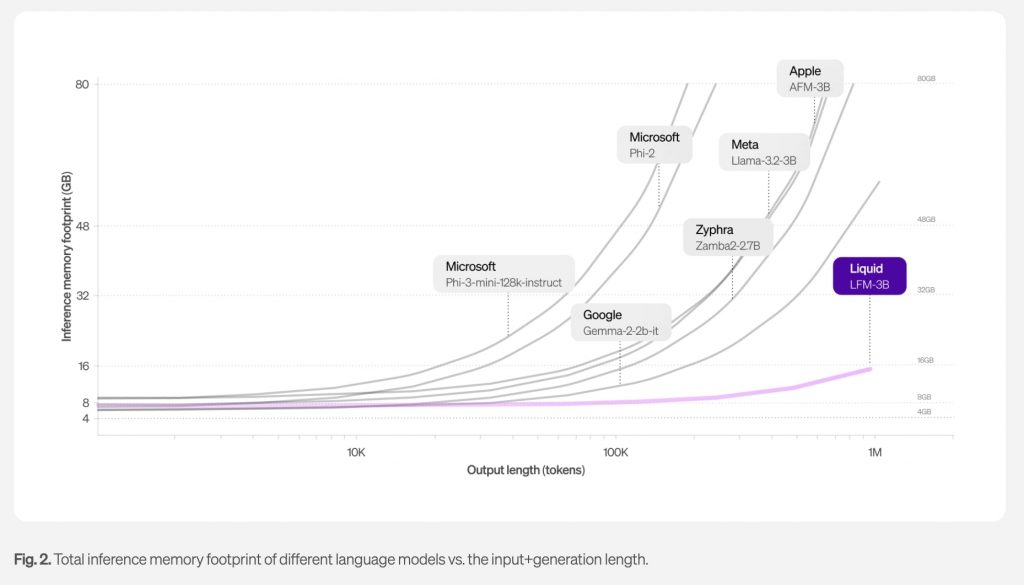
冒頭でも触れたが、LFMの最大の特徴はメモリ効率の高さにある。従来のトランスフォーマーモデルと比較して、必要なメモリ容量が大幅に削減されているのだ。これは特に長文を処理する際に顕著な違いとなって現れる。従来型のAIモデルでは、入力するテキストが長くなればなるほど、それに比例してメモリ使用量が増加していく。
一方、LFMは入力データを効率的に圧縮する技術を採用しており、同じハードウェアでもより長い文章を処理できるようになる。たとえば、30億パラメータサイズのモデルで比較すると、メタのLlama 3.2が48GB以上のメモリを必要とするのに対し、LFM-3Bはわずか16GBのメモリで動作する。この効率性は、一般的なラップトップPCでも高度なAI処理が可能になることを意味する。

https://www.liquid.ai/liquid-foundation-models
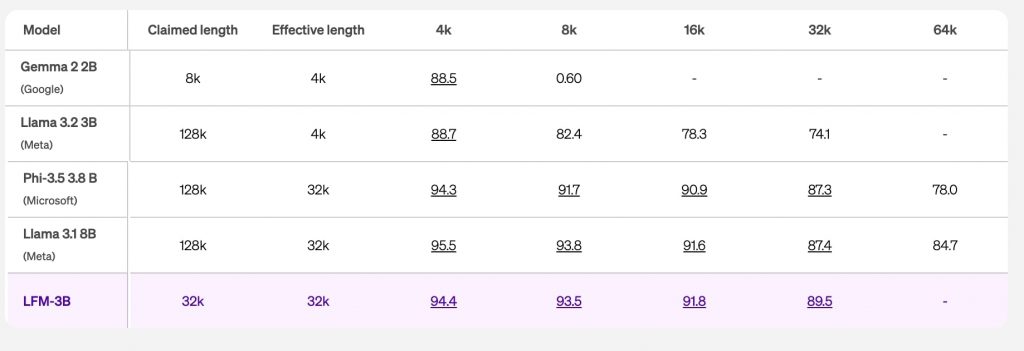
プレビューリリースでは、LFMの最大コンテキストウィンドウと有効コンテキストウィンドウはともに3万2,000トークンと、トランスフォーマーモデルとは一線を画すパフォーマンスを示す。コンテキストウィンドウとは、AIモデルが一度に処理できる情報量を指す。ChatGPTでいえば、プロンプト欄に入力するテキストなどがそれに該当する。トランスフォーマーモデルでは、一般的に、最大コンテキストウィンドウに対し、有効コンテキストウィンドウは大幅に下がる傾向にある。たとえば、グーグルのGemma2 2Bモデルは8,000トークンが最大コンテキストウィンドウとなっているが、仮に8,000トークン分の情報量を処理させた場合、そのパフォーマンスは大幅に下がることが確認されている。実際に利用できる有効コンテキストウィンドウは4,000トークンとされる。このほか、メタのLlama3.2 2Bモデルも最大コンテキストウィンドウは12万8,000トークンとなっているが、有効コンテキストウィンドウは4,000トークンと、かなり低い値だ。

https://www.liquid.ai/liquid-foundation-models
この高効率なコンテキストウィンドウにより、エッジデバイスでの長文脈タスクが可能になると期待される。開発者にとっては、文書分析や要約、コンテキストを認識するチャットボットとの対話、検索拡張生成(RAG)のパフォーマンス向上など、新しいアプリケーションの可能性が広がる。
Liquid AIは現在、モデルサイズ、トレーニング/テスト時の計算能力、コンテキストウィンドウ面でLFMをさらにスケールアップすることを目指している。言語LFMに加えて、今後数カ月間で、さまざまなデータモダリティ、ドメイン、アプリケーション向けのモデルをリリースする計画という。
LFM各モデルのパフォーマンス
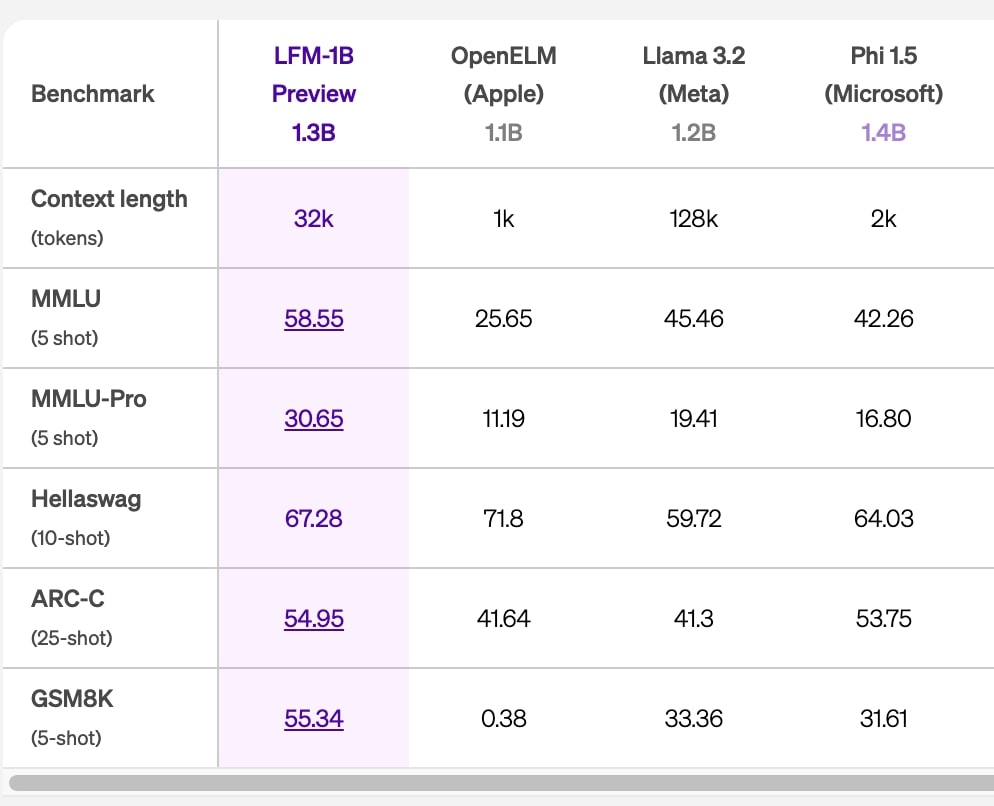
Liquid AIは、様々なベンチマークを通じてLFMの性能評価を実施した。特に、最小モデルであるLFM-1Bの結果が際立つ。1B(10億パラメータ)カテゴリーで最高スコアを達成し、この規模での新たな最高水準を確立した。
たとえば、MMMLUベンチマークにおいて、LFM-1Bは58.55%のスコアを記録。これはOpenELM(アップル)の25.65%、Llama3.2(メタ)の45.46%、Phi-1.5(マイクロソフト)の42.26%を大きく上回る数値だ。さらに、数学的推論能力を測るGSM8Kでは55.34%を記録し、30〜40%代にとどまる競合モデルを大きく引き離している。

https://www.liquid.ai/liquid-foundation-models
中規模モデルのLFM-3Bも、サイズに対して驚異的なパフォーマンスを示す。3Bパラメータのトランスフォーマー、ハイブリッド、RNNモデルの中で首位に立っただけでなく、前世代の7Bおよび13Bモデルをも上回った。さらに、18.4%小さいにもかかわらず、複数のベンチマークでPhi-3.5-miniと同等の性能を示している。

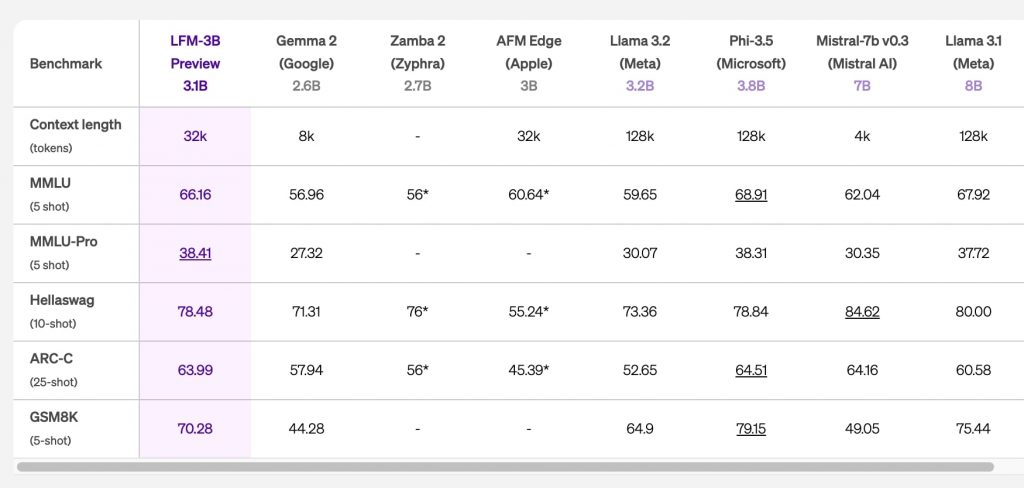
https://www.liquid.ai/liquid-foundation-models
最大モデルのLFM-40Bは、モデルサイズと出力品質の新たなバランスを提供。使用時には12Bのパラメータが活性化され、そのパフォーマンスはより大きなモデルに匹敵する。

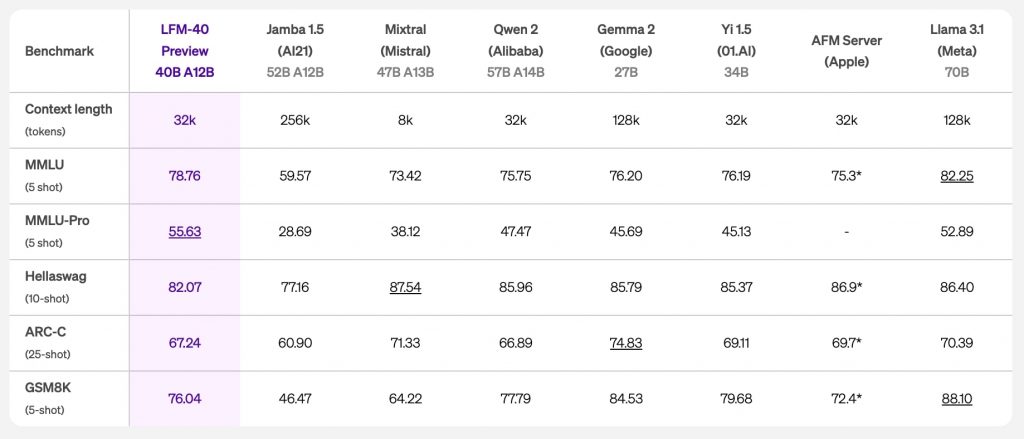
https://www.liquid.ai/liquid-foundation-models
これらの結果は自社評価であるため、より客観的なサードパーティによる分析も必要となるが、Liquid AIはオープンサイエンスのアプローチを取ることを表明している。科学技術レポートを通じて発見や手法を公開し、研究成果から生み出されたデータやモデルをAIコミュニティに提供していく計画だ。ただし、これらのアーキテクチャの開発には多大な時間とリソースを投入してきたため、現時点ではモデルのオープンソース化は行わないとしている。これにより、競争の激しいAI業界において優位性を維持しつつ、進歩を継続できるとの判断のようだ。
文:細谷元(Livit)