

AI開発におけるデータ品質問題
生成AIの急速な普及に伴い、その基盤となるデータの品質問題が浮き彫りになっている。大規模言語モデル(LLM)やその他の生成AIアプリケーションの性能は、学習に使用されるデータセットの質に大きく依存する。しかし、AIモデルの学習に低品質なデータが混入しているケースが多く、様々な問題を引き起こしているのが現状なのだ。
データ品質の問題は、単なる技術的な課題にとどまらず、AIの公平性や信頼性にも直結する重要な問題。たとえば、これまでも性別バイアスを持つ人事AIモデルや、人種バイアスを持つヘイトスピーチ検出器など、データバイアスが原因で実世界に大きな影響を与えた事例は少なくない。
データ品質の問題は多岐にわたる。選択バイアス、自動化バイアス、時間的バイアス、暗黙的バイアス、社会的バイアスなど、様々な形でデータの偏りが生じる可能性がある。また、データの重複も大きな問題だ。2022年の研究では、データの0.1%を100回繰り返すだけで、モデルの精度が半減することが明らかになった。これは、重複したデータがモデルの記憶容量を不釣り合いに占有し、データ間の関係性を一般化する能力を低下させるためだと考えられている。
さらに、AIが生成したコンテンツが学習データに混入する「モデル自己消化障害(Model Autophagy Disorder: MAD)」と呼ばれる現象も懸念されている。ケンブリッジ大学の研究チームは、AIが生成したコンテンツの割合が増加すると、モデルが保持する知識が変化し、有用性が低下する可能性があると指摘している。
こうした状況下、注目されるのが多くの高品質データを持つメディア企業の動きだ。直近ではEsquire、Cosmopolitan、Elleなどのメディアを傘下に持つHearst社とOpenAIが提携を発表したばかり。メディア企業にとっては、OpenAIのChatGPTが生成する回答に各メディアのコンテンツが参照されることで、ユーザーへの露出を高められるという利点がある。一方、OpenAIなどのAI企業にとっては、メディア企業が有する高品質データにアクセスすることで、AIモデルの精度を高められるという利点がある。
これまではニュース記事をメインとするテキストデータをめぐる動きが多かったが、今後は以下で詳述するように高品質画像や動画データをめぐる動きが活発化する見込みだ。
Getty ImagesがHugging Faceで公開したデータセットの概要、そのインパクト
ストックフォト大手のGetty Imagesが、AI開発プラットフォームHugging Faceで高品質な画像データセットを公開し、業界に大きな反響を呼んでいる。この動きは、信頼できるデータパートナーとしての地位を確立し、AIモデルトレーニング用の公式ライセンスコンテンツ利用の促進を目的とするもの。
Getty Imagesのデータ科学・AI/ML部門責任者であるアンドレア・ガリアーノ氏がVentureBeatの取材で語ったとろこでは、このデータセットは、多様性と高品質性に加え、レスポンシブルなデータである点が特徴という。
公開されたサンプルデータセットには、15カテゴリーにわたる3750枚の画像が含まれている。抽象的な背景から、建造環境、ビジネス、概念、教育、ヘルスケア、アイコン、産業、自然、イラスト、旅行まで幅広いジャンルをカバー。これらの画像はGetty Imagesが完全に所有するクリエイティブライブラリから提供されており、商業的に安全で、開発者が予期せぬ法的問題に巻き込まれる心配がないとされる。
またデータセットがランダムに選ばれたものではなく、AIのトレーニング向けに選別され、メタデータが付与されている点も特筆に値する。通常、画像モデルのトレーニング/ファインチューニングでは、データセットのクリーニングに加え、画像のバリエーションを増やすなどの強化作業が発生し、多大な時間とコストを要する。豊富なメタデータにより、これらのプロセスを省くことが可能だ。NSFW(性的)コンテンツなどの不要な要素も排除されている。
ガリアーノ氏は、このデータセットをAIモデルのトレーニングに利用できる最高品質のデータセットであると評価、「最もクリーンで高品質」という表現を用いて、その優位性を強調している。
ただし、このデータセットの利用にあたり、いくつかの制限事項がある点には留意が必要だ。データセットの再配布、データセットに含まれるコンテンツのデジタル複製を作成・再現・生成するモデル/ソフトウェアの開発、Getty Imagesと直接競合する製品/サービスの作成、データセットから派生したバイオメトリック識別子の作成または使用、適用法や規制に違反する方法での使用などが制限される。
Getty Imagesは、この取り組みを通じ、コンテンツの原作者/クリエイターに対する年間報酬支払いの制度も計画しているとのこと。なお同社は、NVIDIAと提携して開発したAI画像生成ツールでも同様のアプローチを採用しているという。
Getty Imagesのデータセットの詳細を解説
Getty Imagesが公開したデータセットは、AIプラットフォームのHugging Faceからダウンロードして利用することが可能だ。実際、データセットの中身を確認しつつ、「最もクリーン」な高品質データと呼ばれる理由を探ってみたい。
まず注目すべきは、画像そのものの品質が非常に高いという点だ。プロカメラマンによって撮影された水準の画像であり、露出、フォーカス、色彩などもしっかりと調整されたものとなっている。画像フォーマットはJPGで、画像1つあたり10MB前後のファイルサイズ。一般的な画像データセットには品質のばらつきが見られるが、このデータセットは一貫した画像品質を維持している。
AIモデルの精度に大きな影響を及ぼす画像メタデータの質と量も特筆に値する。
データセットから1つ例をとってみたい。


https://huggingface.co/datasets/GettyImages/Getty-Images-Sample-Dataset/viewer?row=2
この画像には、画像の内容、概念、感情、場所など、非常に詳細で構造化されたメタデータが付与されている。たとえば、「交通事故現場での救助活動」という一枚の画像に対し、「交通」「事故」「救助」「安全」「危険」といった概念的なタグから、「オレンジ色」「水平方向の構図」といった視覚的要素、さらには「フラストレーション」「悲しみ」といった感情的要素まで、多岐にわたる情報が含まれているのだ。これは一般的なデータセットでは見られない細かさと言えるだろう。

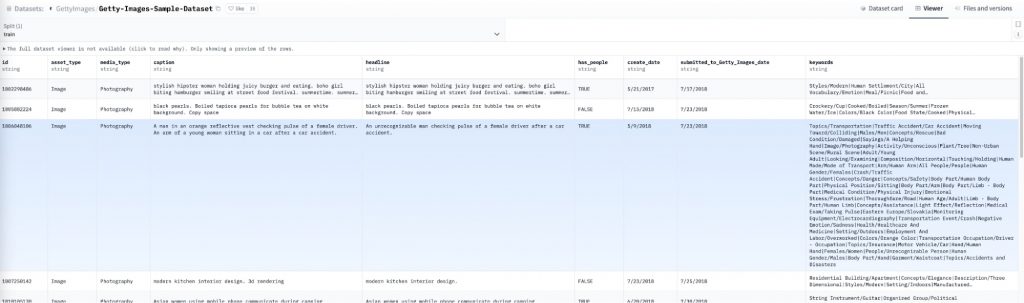
商業利用の安全性も無視できない特徴だろう。Getty Imagesは著作権管理に定評があり、このデータセットは商業利用を前提に構築されている。一般的なデータセットでは著作権の問題が生じる可能性があるが、このデータセットではその心配はほとんどない。これは、AIを用いた商用サービスの開発において大きな利点となるはずだ。
Getty Imagesを筆頭に、データ品質の向上を目指す動きは今後さらに活発化することが予想される。データ品質の向上にともない、AIの精度がどこまで高まるのかが注目される。
文:細谷元(Livit)