

AI21の最新ハイブリッドモデル、Jamba 1.5
GPTなど人気のある主要大規模言語モデル(LLM)の多くは、「トランスフォーマー」というアーキテクチャを基礎としている。トランスフォーマーベースのLLMはこの1年ほどで飛躍的な進化を遂げ、さまざまなタスクで高いパフォーマンスを発揮できるようになった。しかし、長文になると精度が大きく下がる、また計算コストが急増する特性があり、この課題の解決に向けた取り組みが活発化している。
イスラエルのAI21は、この分野の取り組みで注目されるスタートアップの1つ。同社が2024年8月末にリリースしたAIモデル「Jamba 1.5」が今後のLLMの方向性を決定付けるものになる可能性を秘めるためだ。
Jamba 1.5の特徴は、トランスフォーマーと「Mamba」と呼ばれる構造化状態空間(SSM)モデルを組み合わせたハイブリッドアーキテクチャを採用している点にある。Jambaは「Joint Attention and Mamba」の頭文字を取ったもの。
AI21は、Jamba 1.5シリーズとして2つのモデルをリリースした。「Jamba 1.5 mini」は総パラメータ数520億、アクティブパラメータ数120億、「Jamba 1.5 large」は総パラメータ数3,980億、アクティブパラメータ数940億のモデル。両モデルともMixture-of-Experts(MoE)アーキテクチャを採用、25万6,000トークンという大きなコンテキストウィンドウを持つ。
Jamba 1.5の特筆すべき点は、最近関心が高まるエージェント型AI開発に適した機能を多数搭載していることだ。たとえば、JSON対応、引用機能、ドキュメントAPI、関数呼び出し機能などが挙げられる。AIコミュニティでは、特に引用機能に注目が集まっている。この機能は従来のRetrieval Augmented Generation(RAG)とは異なり、モデル自体に統合されたアプローチで、RAGを代替する可能性があるためだ。
より具体的に言うと、Jambaは、入力されたドキュメントに基づいて回答を生成する際に、その情報の出所を明示することが可能となる。たとえば、長い報告書に基づいて質問に答える場合、Jambaは「第3章のデータによると…」や「結論セクションで述べられているように…」といった形で、情報の出所を明示しながら回答を生成できるのだ。
RAGとの大きな違いは、外部データベースを検索する必要がない点にある。RAGでは、AIモデルが質問に答える際に外部の知識ベースを検索し、関連情報を取得する。Jambaの引用機能は、与えられたコンテキスト内で情報を追跡し、引用を行う。これにより、処理速度が向上し、より一貫性のある回答が可能になる。以下では、なぜそれが可能となるのか、技術的な背景を探る。
Jamba 1.5が採用した「トランスフォーマー×Mamba」のハイブリッドアプローチとは?
Jamba 1.5の基礎の1つとなっているMambaは、カーネギーメロン大学とプリンストン大学の研究者らが2023年12月に提案したトランスフォーマーを代替する新しいアーキテクチャだ。Mambaは構造化状態空間モデル(SSM)の一種で、従来のトランスフォーマーモデルが抱える長文処理の課題を解決するために開発された。
Mambaの特徴は「選択メカニズム」にある。これは、人間が文章を読むときに重要な部分に注目するのと似たような働きをする。長い小説を読むとき、私たちは物語の展開に重要な部分に注目し、それほど重要でない細かい描写は軽く読み流すことがある。Mambaの選択メカニズムも、これと似たようなことを行っている。
この仕組みにより、Mambaは長い文章を効率的に処理することが可能となった。従来のAIモデルでは、文章が長くなるほど必要な計算量やメモリが急激に増えてしまう問題があったが、Mambaにはこの問題が発生しない。さらに、Mambaには「線形でスケーリングする」という特性がある。これは、処理する文章が長くなっても、必要な計算時間がゆるやかにしか増えないことを意味する。一方、従来のトランスフォーマーモデルは「二次関数的にスケーリング」する特性を持っており、文章が長くなるほど計算時間が急激に増加するのだ。
この構造の違いにより、Mambaは長いコンテキストを扱う際に優れたパフォーマンスを発揮できる。たとえば、100万トークン(日本語で約100万語)を超えるデータでも性能がほとんど落ちないことが報告されている。
しかし、Mambaにも課題は存在する。AI21の説明によると、Mambaは長文処理には優れているものの、全体のコンテキストを考慮する注意機構がないため、特に想起関連のタスクで既存の最高性能モデルと同等の出力品質を達成するのが難しいという。ここでいう「想起」とは、過去に学習した情報を適切に思い出し、利用する能力を指す。Mambaは、文章全体のコンテキストを十分に考慮できないため、こうしたタスクで既存の最高性能モデルと同等の性能を発揮するのが難しかったのだ。
この課題を克服するために、AI21はMambaとトランスフォーマーのハイブリッドアーキテクチャを開発した。これがJambaの核心部分となる。Jambaは、トランスフォーマー、Mamba、そしてMixture-of-Experts(MoE)層で構成されており、メモリ、スループット、パフォーマンスを同時に最適化することを目指したモデルだ。
この新しいアーキテクチャにより、Jamba 1.5は長文処理の効率性と高い出力品質を両立させることに成功。AI21によれば、Jamba 1.5は長いコンテキストで同サイズの他モデルの3倍のスループット(スピード)を達成し、単一のGPUで14万トークンのコンテキストを処理できるという。
長文理解で圧倒的な強み
Mambaの強みを踏襲したJamba 1.5は、長文理解で他モデルを寄せ付けない圧倒的な精度を実現した。この能力を評価するために、AI21はJamba 1.5を複数の長文理解ベンチマークで検証している。
特に注目すべきは、RULERベンチマークにおける結果だ。RULERは、長文理解能力を評価するために設計された13の合成タスクで構成されている。これには、「長い文章の中から特定の情報を見つけ出す」タスクや、「長い文脈の中で変数の値を追跡する」タスク、「長文の中から最も頻出する単語を集計する」タスクなどが含まれる。
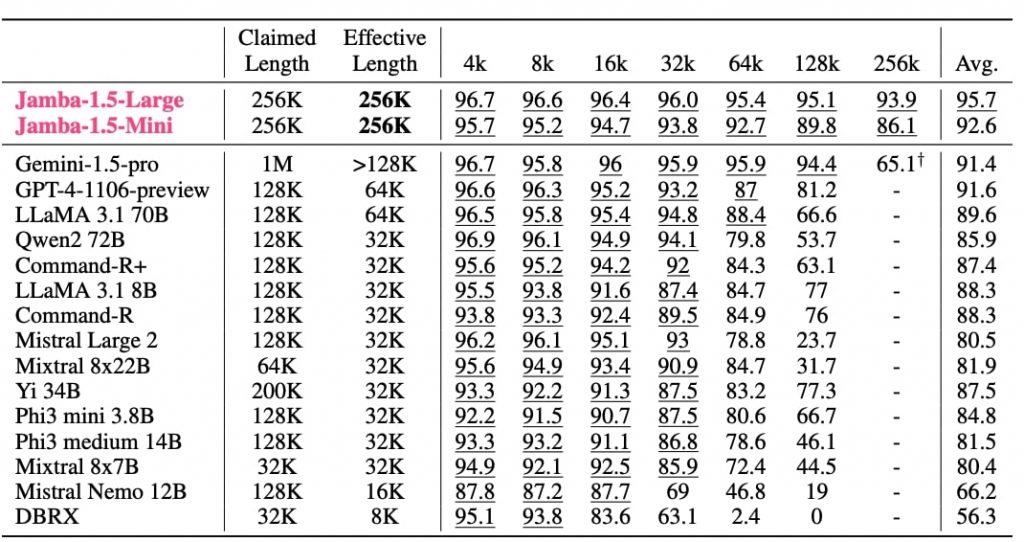
このRULERベンチマークにおいて、Jamba 1.5 Largeは25万6,000トークンに上る長文を高い精度で処理できることが確認された。25万6,000トークンは、日本語に換算すると約25万文字に相当し、500ページ以上の長編小説、または100本以上のウェブ記事に匹敵する情報量となる。

https://arxiv.org/pdf/2408.12570
具体的な数値を見ると、Jamba 1.5 Largeは4,000トークンの文章で96.7%、8,000トークンで96.6%、1万6,000トークンで96.4%、3万2,000トークンで96.0%、6万4,000トークンで95.4%、12万8,000トークンで95.1%、そして25万6,000トークンでも93.9%という高い精度を維持することに成功。これらの数値を平均すると95.7%となり、他のどのモデルよりも高いスコアとなった。
この数値がどれほど驚異的なのか、他モデルとの比較で明確になる。
たとえば、最も健闘したグーグルのGemini 1.5 Proは、12万8,000トークンまでは94.4%の精度を保っているが、25万6,000トークンでは65.1%まで低下してしまったのだ。これは、日本語で25万語を処理させたら、出力精度が3分の2ほどまで落ちてしまうことを示唆している。
OpenAIのGPT-4‐1106-previewも、最大コンテキストウィンドウは12万8,000トークンとなっているが、実際にその量の情報を処理させると、精度は81%まで下がってしまうことが確認された。高い精度で回答を生成できるのは、6万4,000トークンまでとなる。
他にも最大コンテキストウィンドウ12万8,000トークンを売りにするAIモデルは多数存在するが、その最大値で情報処理させると、精度は50〜60%ほどまで下がってしまう。Mistral Large2に至っては、12万8,000トークンを処理させると、精度は23%まで下がった。
Jamba 1.5の長文理解能力は、∞BENCH(Infinite-BENCH)というベンチマークでも実証された。これは、平均10万トークンの長い小説の理解力を測定するベンチマークテスト。英語の質問応答(EN.QA)タスクでは、Jamba 1.5 Largeは34.9%のスコアを獲得し、LLaMA 3.1 70Bの36.7%に迫る結果となった。また、英語の多肢選択問題(EN.MC)タスクでは、Jamba 1.5 Largeは80.4%を記録し、LLaMA 3.1 70Bの78.2%を上回った。Mistral Large 2 123Bは36.9%にとどまっている。


https://arxiv.org/pdf/2408.12570
これらの結果は、Jamba 1.5が長文理解において卓越した能力を持つことを示している。特に、25万6,000トークンという非常に長いコンテキストにおいても高い精度を維持できる点は、他のモデルにはない強みだ。この能力は、長い文書の要約、複雑な文脈を必要とする質問応答、大量のテキストデータの分析など、様々な実用的なアプリケーションで威力を発揮すると期待される。
これまでRAGシステムに依拠していたタスクにおいても、単にドキュメントをアップロードするだけで対応できるようになる可能性を示すJamba 1.5。今後、Mambaやハイブリッドアプローチを採用するモデルはさらに増えることが見込まれる。
文:細谷元(Livit)