

ハルシネーションの課題、RAGでも解決しない現状
大規模言語モデル(LLM)が抱える課題の1つ「ハルシネーション(事実と異なる情報を生成する傾向)」は、AIの普及において依然として大きな障壁となっている。この問題に対し、検索補強生成(RAG)という手法が注目を集めているが、スタンフォード大学の最新の調査によると、RAGを採用した法律系AIツールでさえ、ハルシネーションを完全に防ぐことはできていないことが明らかになった。
スタンフォード大学の研究チームは、LexisNexis社の「Lexis+ AI」、トムソン・ロイター社の「Ask Practical Law AI」、ウェストロー社の「AI-Assisted Research」という3つの主要な法律系AIツールを評価した。これらのツールはいずれもRAG手法を採用しており、ベンダーらは「ハルシネーションを排除」「ハルシネーションを回避」といった主張を展開していた。
しかし、調査結果は衝撃的なものだった。Lexis+ AIとAsk Practical Law AIは、調査対象となった質問の約17%でハルシネーションを示し、ウェストローに至っては33%もの質問でハルシネーションが観察された。つまり、5〜6回に1回は誤った情報を提供していたことになるのだ。
この結果は、RAGアプローチがハルシネーションのリスクを低減させる効果はあるものの、問題を完全に解決するには至っていないことを示している。GPT-4と比較すると、確かにハルシネーションの発生率は低下しているが、法律のような高度な正確性が求められる分野では、依然として大きな課題として残されている。
グーグルがハルシネーション対策の新しいアプローチを発表、DataGemmaの概要
グーグルが最近発表した「DataGemma」は、LLMが抱えるハルシネーションの課題に対する新たなアプローチとして注目を集めている。DataGemmaは、Gemmaファミリーの軽量なオープンモデルをベースに、グーグルが作成した「Data Commons」プラットフォームの2,400億以上のデータポイントを活用し、経済、科学、健康など様々な分野の信頼できる統計情報に基づいて回答を生成する。
DataGemmaの特徴は、2つの異なるアプローチを採用している点にある。1つ目は「Retrieval Interleaved Generation(RIG)」で、モデルが生成した回答とData Commonsに格納された関連統計を比較することで事実の正確性を向上させる。2つ目は「Retrieval Augmented Generation(RAG)」で、モデルが回答を生成する前にData Commonsから関連情報を取得し、より包括的な回答を可能にする。
初期のテスト結果は非常に興味深いものとなった。RIGアプローチを用いたDataGemmaは、ベースモデル(Gemini1.5 Pro)の5〜17%だった事実性を約58%まで向上させた。一方、RAGアプローチでは24〜29%の質問に対して統計的な回答を提供し、その99%で数値の正確性を保っていた。
RIGとRAGの両アプローチは、ともにAIモデルの事実性と信頼性を大幅に向上させることに成功しており、その成果は特筆に値する。
しかし、その改善の仕方には特徴的な違いが見られる。RIGアプローチは、事実性をベースラインの5〜17%から約58%まで大幅に改善し、評価クエリのほぼ全てに対して何らかの回答を提供できる。一方で、正確な統計値を提供する割合は58%程度にとどまる。
これに対しRAGアプローチは、評価クエリの24〜29%にのみ統計的な回答を提供するという限定的な適用範囲ながら、提供された統計的主張の98.6〜98.9%が正確という極めて高い正確性を示す。さらに、ベースモデル(Gemini1.5 Pro)の28件に対し190-210件の統計的主張を生成するなど、情報量の大幅な増加も実現している。
適用範囲ではRIGの方が幅広いクエリに対応できるのに対し、RAGは限定的だが高い正確性を誇る。また、RAGは単一の回答でより多くの統計的主張を提供する傾向がある。ユーザー体験の観点では、RIGはベースモデル(Gemini1.5 Pro)よりも62〜76%のユーザーに好まれ、RAGはData Commonsの統計を含む回答が得られた場合、92〜100%のユーザーに好まれるという結果が出ている。
総合的に見ると、RIGは幅広いクエリに対して一定レベルの改善を提供する一方、RAGは限られたケースにおいてより高い正確性と豊富な情報量を提供する。両アプローチともベースモデル(Gemini1.5 Pro)を大きく上回る性能を示しており、用途や要求される正確性のレベルに応じて使い分けることが有効だと考えられる。このように、DataGemmaプロジェクトは異なるアプローチを組み合わせることで、AIの事実性と信頼性の向上に多面的にアプローチしている。
DataGemmaは現在、Hugging Faceで公開されており、学術研究目的での利用が可能となっている。この公開によってRIGとRAGの両アプローチに関するさらなる研究が進み、より強力で信頼性の高いモデルの構築につながることが期待される。
DataGemmaで採用されたRIGとは、その詳細を解説
DataGemmaで採用された2つのアプローチのうち、特に注目を集めているのが「Retrieval Interleaved Generation(RIG)」だ。RIGは、LLMの回答生成プロセスに事実確認のステップを組み込むことで、ハルシネーションのリスクを大幅に低減させる手法である。
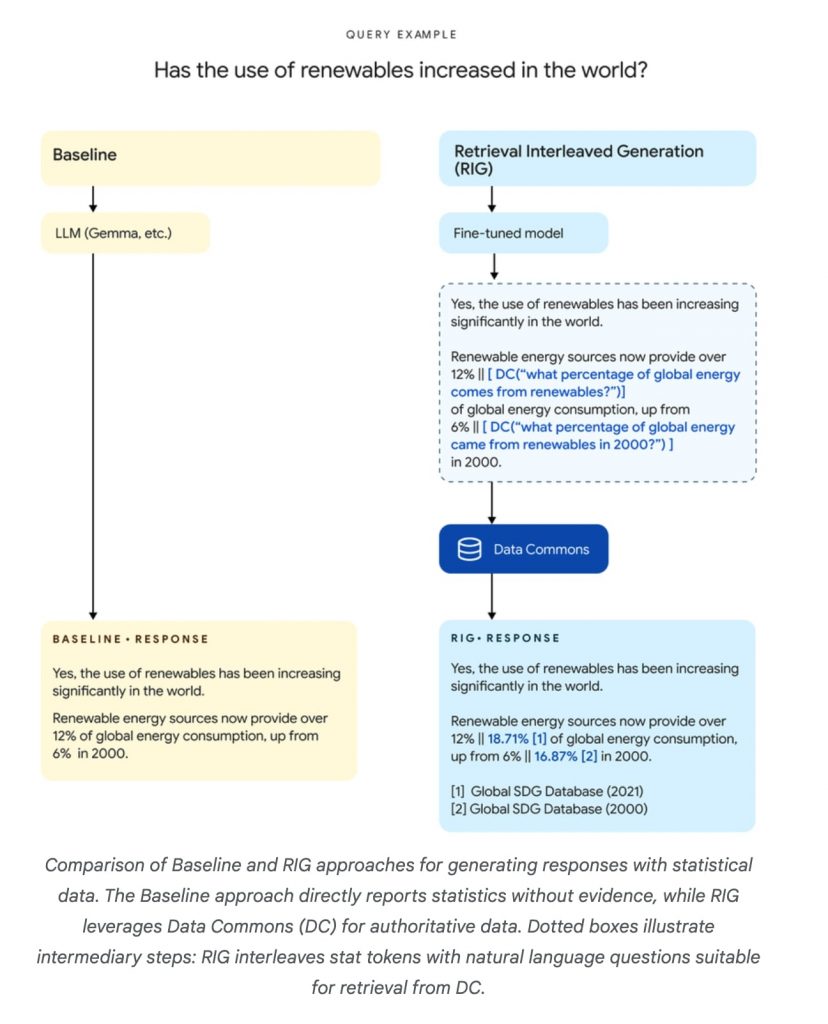
RIGの具体的な仕組みは以下のようになっている。まず、ユーザーからの質問に対し、DataGemmaモデル(Gemma 2モデルをベースに微調整されたもの)が初期の回答を生成する。この際、モデルは統計データを含む部分を特定し、Data Commonsに対する自然言語クエリを生成する。たとえば、「カリフォルニア州の人口は3900万人です」という回答を生成する代わりに、「カリフォルニア州の人口は[DC(カリフォルニア州の人口は?) → “3900万人”]です」というような形式で出力する。

https://research.google/blog/grounding-ai-in-reality-with-a-little-help-from-data-commons/
次に、このクエリを使ってData Commonsから実際のデータを取得し、初期回答の数値と比較・修正を行う。最終的に、修正された回答とともに、Data Commonsのソース情報とリンクが提供される。これにより、ユーザーは回答の根拠となるデータを直接確認することができ、透明性と信頼性が向上する。
RIGアプローチの大きな利点は、ユーザーの元の質問を変更することなく、あらゆる文脈で効果的に機能する点だ。しかし、LLMがData Commonsから更新されたデータを学習・保持しないため、二次的な推論や関連質問に対しては新しい情報を活用できないという制限もある。
グーグルの研究チームによると、RIGアプローチは、LLMに自身の回答を信頼できるソースと照合させることを意味し、AIの信頼性向上に向けた重要なステップになるという。
グーグルは、RIGアプローチをさらに改良し、より多くのユースケースに適用できるよう研究を続けている。将来的には、GemmaモデルだけでなくGeminiモデルにも統合される可能性があるとのこと。
DataGemmaを支えるData Commonsの基盤技術、グラフデータベース/ナレッジグラフ
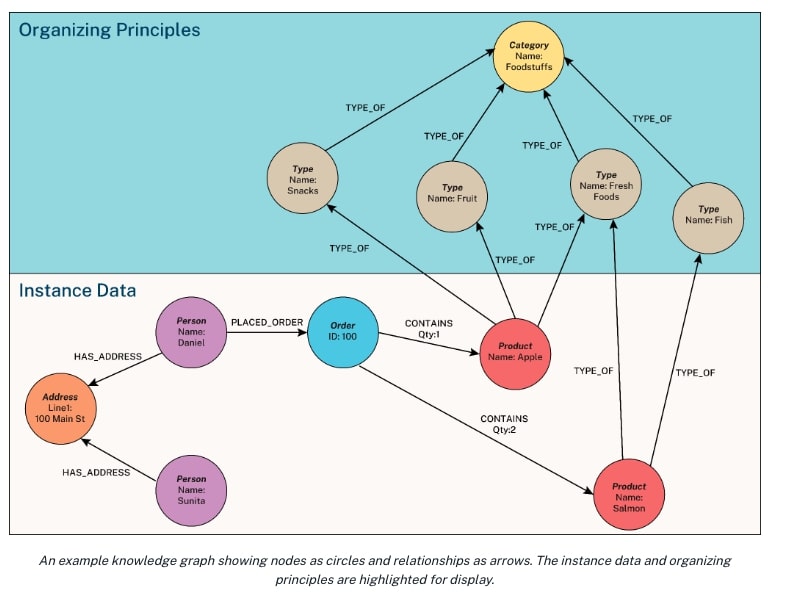
DataGemmaの核心となるData Commonsプラットフォームは、グラフデータベースとナレッジグラフ技術を基盤として構築されている。ナレッジグラフとは、現実世界の実体とその関係性を組織化して表現したものだ。Data Commonsでは、この技術を活用して2400億以上のデータポイントを効率的に管理し、検索可能な形で提供している。
グラフデータベースの特徴は、データ間の関係性を直接的に格納できる点にある。これにより、複雑な関係性を持つ大量のデータを効率的に管理し、高速に検索することが可能となるのだ。Data Commonsは、この技術を活用して経済、科学、健康など様々な分野の統計情報を統合し、一元的に提供している。

https://neo4j.com/blog/what-is-knowledge-graph/#:~:text=A%20knowledge%20graph%20is%20an,events%2C%20situations%2C%20or%20concepts.
DataGemmaは、このData Commonsプラットフォームを外部知識源として活用。RIGとRAGの両アプローチは、Data Commonsが提供する自然言語インターフェースを通じて必要な情報を取得し、LLMの回答に組み込んでいる。この過程で、グラフデータベースの高速な検索能力とナレッジグラフの豊富な関係性情報が間接的に活用されている。
たとえば、ユーザーが「カリフォルニア州の人口は?」と質問した場合、DataGemmaはData Commonsの自然言語インターフェースを介して、グラフ構造内の「カリフォルニア州」ノードから「人口」プロパティへの最短パスを瞬時に見つけ出し、正確な情報を取得できる。
さらに、「過去10年間で再生可能エネルギーの使用が最も増加した国は?」のような複雑な質問に対しても、Data Commonsのグラフ構造を利用して、国、エネルギー使用量、年度などの複数のノードを横断し、必要なデータを効率的に収集することが可能だ。
グラフデータベースとナレッジグラフは、グーグルだけでなく、他の大手企業も注目する技術。たとえば、デロイトは、エンタープライズグレードの生成AIを構築する上でナレッジグラフが果たす重要な役割を強調。ガートナーも、ナレッジグラフを生成AI分野において高い影響力を持つ技術として位置付けている。
DataGemmaは、このようなグラフデータベースとナレッジグラフの技術を巧みに活用することで、LLMの回答精度を向上させ、より信頼性の高いAIシステムの実現に一歩近づいたと言える。今後、この技術がさらに進化し、より幅広い分野でAIの信頼性向上に貢献することが期待される。
文:細谷元(Livit)