

GPT-4の進化と競合モデルの台頭
OpenAIのフラッグシップ大規模言語モデル(LLM)であるGPT-4は、この1年で目覚ましい進化を遂げてきた。その進化の過程は、ベンチマークテスト「LiveBench」のスコアに如実に表れている。
LiveBenchは、Abacus.AI、NVIDIA、ニューヨーク大学、メリーランド大学、南カリフォルニア大学の研究チームが開発した新しいベンチマークだ。LiveBenchの特徴は、データ汚染問題を最小限に抑えつつ、LLMの性能をより正確に評価できる点にある。
2024年8月19日時点のLiveBenchリーダーボードにおける、GPT-4の最新バージョン「gpt-4o-2024-08-06」の総合スコアは56.71。GPT-4は、特に「推論」と「コーディング」分野での進歩が目覚ましい。
推論平均スコアは、2023年6月13日版(gpt-4-0613)の34.67から、最新版では54.67へと20ポイント上昇。コーディング平均スコアも37.31から51.44へと、14ポイント以上増加した。数学分野でも着実な改善が見られる。数学平均スコアは36.22から52.29へと16ポイント上昇。データ分析分野でも44.03から52.89へと、約9ポイントの向上を達成した。このほか言語理解では、49.57から54.37へと約5ポイント上昇。指示遂行(IF)平均スコアも71.79から74.58へと、小幅ながら着実な向上を示している。
これらのスコアの推移は、GPT-4が全方位的に能力を向上させてきたことを示すもの。特に推論とコーディング能力の飛躍的な向上は、GPT-4の実用性を大きく高めるものだと言えるだろう。
しかし、競合モデルの台頭も際立っており、GPT-4の相対的な優位性は失われつつある。LiveBenchにおいて首位の座を占めているのは、AnthropicのClaude 3.5 Sonnetだ。総合スコア59.87を記録し、GPT-4を3ポイント以上引き離す。
特筆すべきは、Claude 3.5 Sonnetのコーディング能力の高さだ。コーディング平均スコアで60.85を記録し、GPT-4の51.44を大きく上回っている。Anthropicのウェブサイトによると、Claude 3.5 Sonnetは独自のコーディング評価テストで、テスト問題の64%を解決。これは、以前のフラッグシップモデルClaude3 Opusの38%を大きく上回る結果であるという。
メタのLlama 3.1 405Bも、LiveBenchの総合スコア54.25で5位に食い込み、オープンソースの可能性を見せつけている。特に指示遂行(IF)平均スコアは78.47を記録、この項目では、Llama 3.1 70B、Gemini1.5に次ぐ3位という成績だ。そのグーグルのGemini 1.5 Pro Expも総合スコア51.56で総合7位と健闘。別のベンチマーク/リーダーボードであるLMSYSのChatbot Arenaでは、一時GPT-4oを超え、1位の座を獲得した実力を備えている。
このようにGPT-4は着実に進化を遂げているものの、競合モデルも急速に力をつけているのが生成AI市場の現状となる。
医療分野でGPT-4を超えるモデルが登場
GPT-4、Claude 3.5、Gemini 1.5などは「汎用モデル」と呼ばれる大規模言語モデル(LLM)だが、特定領域に特化した専門モデルの開発も活発化しており、専門知識でGPT-4を超えるモデルも増えつつある。サンフランシスコを拠点とするAI企業Writerが2024年7月31日にリリースした「Palmyra-Med-70b」は、その代表例といえるだろう。
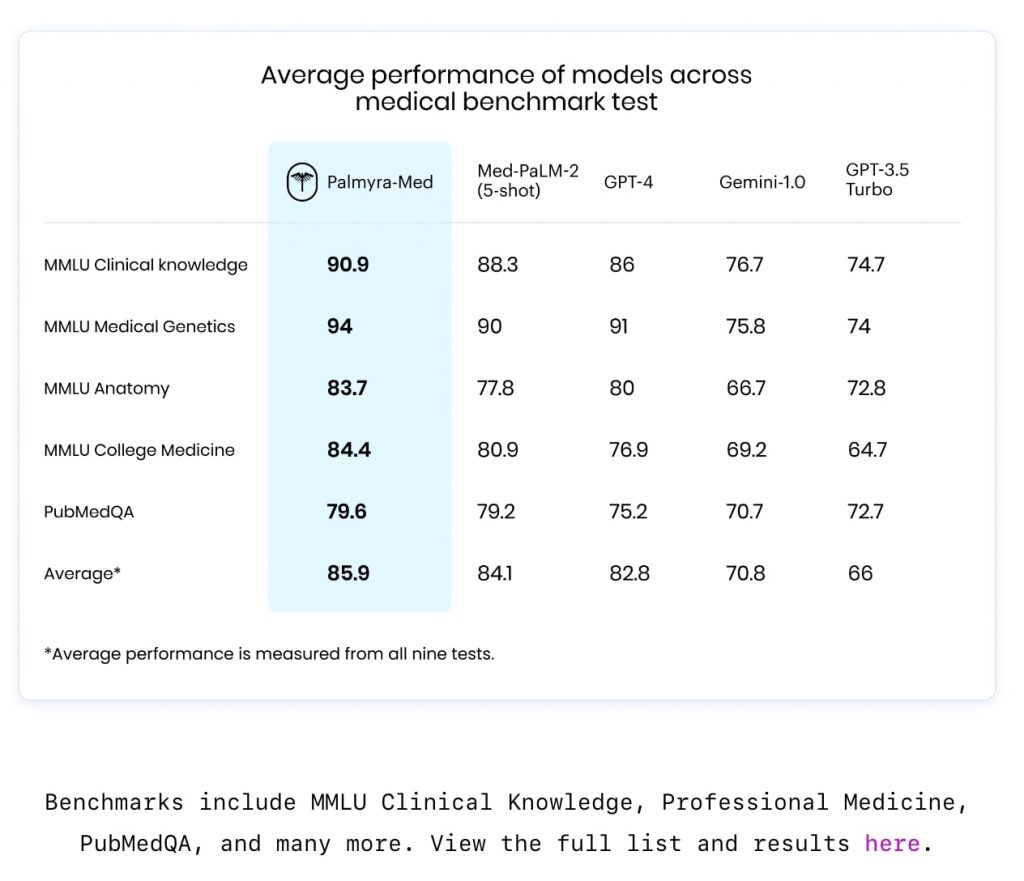
Palmyra-Med-70bは、ヘルスケア業界に特化した専門モデル。Writerによると、このモデルは医療ベンチマークで85.9%に達し、GPT-4の82.8%、グーグルMed-PaLM-2の84%を上回った。特筆すべきは、Med-PaLM-2が5回の試行後にようやく82.8%に到達したのに対し、Palmyra-Med-70bがゼロショット(事前の例示なし)でそれを超える85.9%を記録した点だろう。
Writerによると、Palmyra-Med-70bは臨床知識と解剖学でそれぞれ90.9%と83.7%のスコアを達成、診断や治療計画の支援に有用であることが示唆された。また、医療遺伝学で94.0%、大学医学で84.4%のスコアを記録し、遺伝カウンセリングや医学教育への応用可能性も高いことが示された。さらに、PubMedQAで80%を獲得、生物医学文献からの情報抽出/分析能力が高いことも示した格好となる。

https://writer.com/blog/palmyra-med-fin-models/
Palmyra-Med-70bの登場は、ヘルスケア産業におけるAI活用の流れを大きく変える可能性がある。同モデルがオープンソースモデルとして公開されているためだ。ヘルスケア分野で高い精度を誇ってきた従来のモデルはクローズドソースであり、重要な部分がブラックボックスとなっていた。Palmyra-Med-70bは、透明性が重要視される医療関連組織において魅力的な選択肢になることが想定される。Palmyra-Med-70bは、NvidiaやBaseten、Hugging Faceなどの主要AIプラットフォームで利用可能となっている。
金融領域でも専門モデルが高いパフォーマンス
Writerは医療分野を専門とする「Palmyra-Med-70b」と同時に、金融領域に特化した「Palmyra-Fin-70b」もオープンソースとしてリリースした。
Palmyra-Fin-70bに関して特筆すべきは、金融分野の試験「CFA」における3次試験(多肢選択式テスト)の合格スコアを取得した点だろう。この試験は、過去11年間にわたる平均合格スコアが60%、合格率は50%以下といわれる難関試験。1年ほど前にGPT-4がCFAの試験を受けたところ、33%しか取得できなかったと報じられている。この試験において、Palmyra-Fin-70bは、73%を獲得したという。
Writerは、Palmyra-Fin-70bの性能を評価するために、「long-fin-eval」という内部ベンチマークを開発。これは実際の金融ユースケースを模したもので、長文の文書と高品質の質問回答セットのサンプルで構成されている。モデルは提供された文書と質問に基づいて回答を生成し、その出力はGPT-4 Turboによって評価される。
この評価でPalmyra-Fin-70bは、9.04のスコアを獲得し、Claude 3.5 Sonnet(9.02)、Qwen-2 70B instruct(8.9)、GPT-4o(8.72)などの主力モデルを超えるパフォーマンスを示した。
Palmyra-Fin-70bは、金融用語を理解しつつ、財務報告書、市場データ、経済指標を分析・要約し、重要な情報を抽出して簡潔で構造化された要約を生成することが可能だ。この能力を活用することで、幅広いユースケースが想定される。たとえば、投資分析、リスク管理、金融研究などのアプリケーションが考えられる。
一方、Palmyra-Fin-70bの使用には注意も必要だ。Hugging Faceの情報によると、高品質なデータを活用しているものの、不正確さ、バイアス、誤った情報を含む可能性があり、また実際の金融環境で厳密に評価されていない。そのため、人間の監視なしに直接的な金融意思決定や専門的な金融アドバイスに使用することは推奨されていない。
生成AI市場は、モデルの大規模化への限界が見え始めており、小型モデルや専門モデルの開発、またエージェントシステムの開発にリソースがシフトしつつある。専門モデル分野では、Palmyra-Med-70bなどに続きどのようなモデルが登場するのか、今後の動向を注視したい。
文:細谷元(Livit)