
最新ベンチマークで判明、Claude3.5 Sonnetがトップも、オープンソースモデルが怒涛の追い上げ 大きく変化するAIモデルのランドスケープ
INDEX
最新ベンチマーク、「Hallucination Index」
1年ほど前まで、大規模言語モデル(LLM)は、いわゆるクローズドソースモデル、特にGPT-4が圧倒的な性能を誇っており、さまざまなベンチマーク/リーダーボードにおいて、トップを独占する状態が続いていた。
しかし現在、その状況は大きく変わりつつある。競合クローズドソースモデルの追い上げに加え、オープンソースモデルの躍進により、多極化が進んでいるのだ。開発者やユーザーにとってGPT-4以外の選択肢が大幅に増えたことを意味しており、AIアプリケーションの最適化や低コスト化が一層進む可能性が高まっている。
この状況を如実に示すベンチマークの1つがAIスタートアップGalileoの「Hallucination Index」の最新版だ。Galileoは22の主要な大規模言語モデルを対象に、不正確な情報を生成する傾向(ハルシネーション)を評価する包括的なベンチマークを発表した。その結果、わずか8カ月でオープンソースモデルとクローズドソースモデルの性能差が大幅に縮まっていることが明らかになったのだ。
Galileoによると、2023年10月の前回評価では、上位はすべてクローズドソースモデル、主にOpenAIのGPT-4モデルが独占していた。しかし今回の評価では、競合モデルやオープンソースモデルがその差を急速に縮めていることが示された。
今回の調査では、AnthropicのClaude 3.5 Sonnetが全タスクで最高のパフォーマンスを示し、昨年のランキングを独占していたGPT-4を上回った。Claude 3.5 Sonnetは、短文(5,000トークン以下)、中文(5000〜2万5,000トークン)、長文(4万〜10万トークン)のコンテキストウィンドウで優れたパフォーマンスを発揮。それぞれのタスクで0.97、1、1という平均スコアを記録した。
これが意味するところは、プロンプトに入力される文の長さに関わらず、Claude 3.5 Sonnetはハルシネーションを起こさずほぼ完璧にタスクをこなしたということ。1.0は完璧なスコアを意味する。同モデルは20万トークンのコンテキストウィンドウをサポートしており、テスト時よりも大規模なプロンプトにも対応できる可能性を秘めている。
一方オープンソースモデルの中では、アリババのQwen2-72B-Instructが短文と中文で高いスコアを記録。短文での平均スコアは、0.95とほぼ完璧に近く、クローズドソースモデルの上位であるClaude 3.5 Sonnetの0.97、GPT-4oの0.96に肉薄するパフォーマンスを示した。
LiveBenchやChatbot Arenaでも大きな変動
Hallucination Indexのほか、LiveBenchやChatBot Arenaにおいても、多極化やオープンソースモデルの追い上げが顕著となっている。
LiveBenchとは、Abacus.AI、NVIDIA、ニューヨーク大学、メリーランド大学、南カリフォルニア大学の研究チームが開発した新しいベンチマークだ。このベンチマークの特徴は、データ汚染問題を最小限に抑えつつ、LLMの性能を幅広い側面から評価できる点にある。
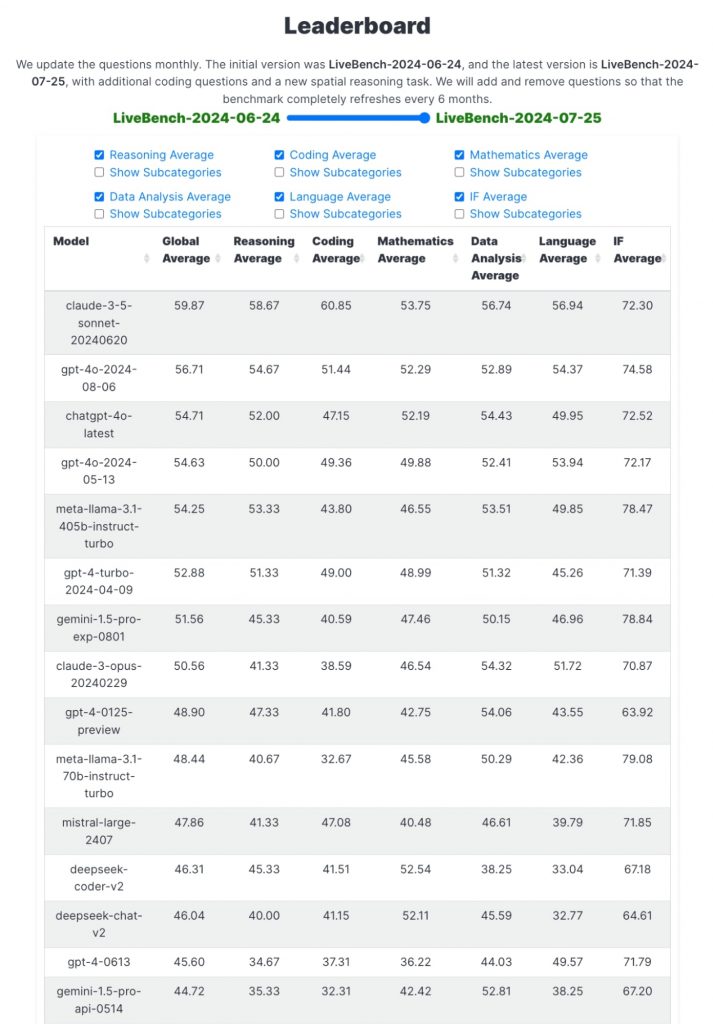
LiveBenchの最新結果(2024年8月16日時点)によると、首位はAnthropicのClaude 3.5 Sonnetで、グローバル平均スコアは59.87に上る。2位はOpenAIのGPT-4oで、グローバル平均スコアは56.71。3位はOpenAIのChatGPT-4o(最新版)で、グローバル平均スコア54.71となっている。
https://livebench.ai/
注目すべきは、メタのオープンソースモデルLlama 3.1 405B Instructが5位に食い込んでいることだ。グローバル平均スコアは54.25と、GPT-4 Turbo(52.88)やGemini 1.5 Pro Exp 0801(51.56)を上回る結果となった。Llama 3.1 405Bは、特に推論項目では53.33と、2位のGPT-4oの54.67に迫る高スコアを記録。インストラクション遵守(IF Average)では78.47と、トップクラスの成績を残している。インストラクション遵守とは、AIモデルが与えられた指示をどれだけ正確に理解し、それに従って適切な応答や行動を取ることができるかどうかを測るテスト。
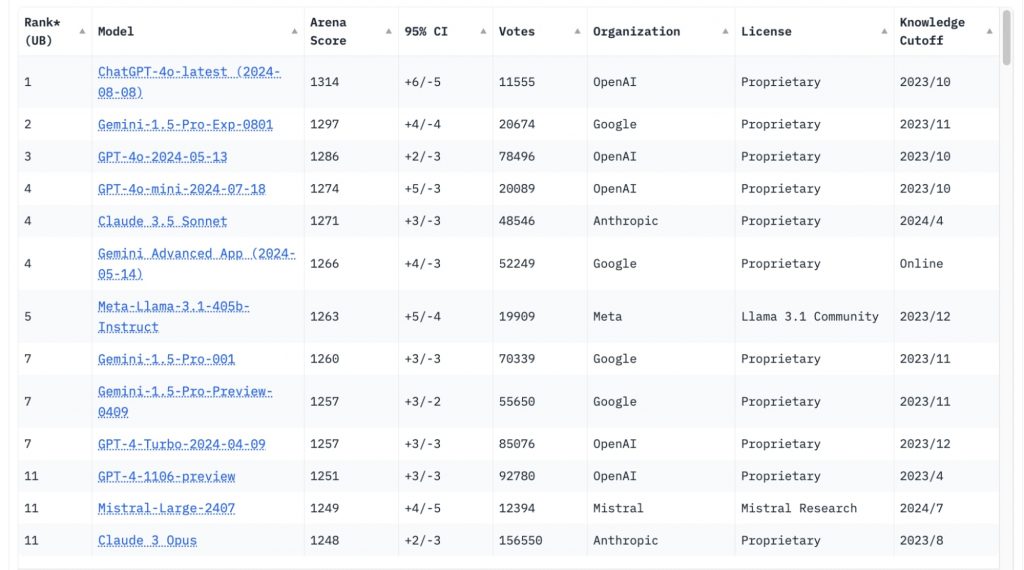
一方、LMSYSのChatbot Arena(2024年8月16日時点)でも、首位のChatGPT-4o(アリーナスコア1314)、2位のグーグルGemini 1.5 Pro-Exp(同1297)、3位のGPT-4o(2024年5月13日版、同1286)などに並び、メタのLlama 3.1 405B Instructが5位(同1263)に食い込んだほか、Llama 3.1 70B(同1246)が11位、グーグルのGemma2 27B(同1217)が19位となるなど、上位におけるオープンソースモデルの存在感が高まりを見せている。
https://chat.lmsys.org/?leaderboard
これらの結果は、クローズドソースモデルが依然として優位性を保ちつつも、オープンソースモデルが急速にそのギャップを縮めていることを示唆するもの。メタのLlamaシリーズやグーグルのGemmaの躍進は目覚ましく、AI開発競争は今後さらに激化することが予想される。
注目のオープンソースモデル、Gemma2 27B
オープンソースモデルといえば、早々にLlamaモデルの投入でリーダー的な地位を確立したメタが注目されがちだが、グーグルの取り組みも見逃せない。同社の主力オープンソースモデルの1つGemmaが飛躍的な性能向上を見せているからだ。
上記でも登場したGemma2 27Bは、270億パラメータという比較的小さな規模ながら、700億パラメータなど数倍大きなモデルに近い性能を発揮しており、特に効率性の観点から大きな関心を集めている。
たとえば、27Bモデルは、グーグルクラウドのTPUホスト1台またはNVIDIA A100 80GB Tensor Core GPU 1台で運用できるように最適化されており、分散コンピューティングインフラを必要としないシンプルさで、デプロイメントコストを大幅に削減できるのだ。
AIエンジニアであるラース・ウィーク氏の分析によると、Gemma2が特に高い能力を発揮するのが多言語理解能力であるという。英語を含む18言語での評価では、Gemma2は他のオープンソースモデルを大きく上回る性能を示した。特に、スワヒリ語、ヒンディー語、フィンランド語など、通常LLMが苦手とする言語でも高い精度を維持できたことが報告された。
具体的な性能比較では、8ビット量子化されたGemma2 9B(90億パラメータ)モデルが、メタのLlama3 8B、マイクロソフトのPhi3 14B、アリババのQwen2 7Bなどの同規模の競合オープンソースモデルを全言語で上回る結果となった。さらに、フルプレシジョンで推論を行うGemma2 27Bモデルは、さらに優れた性能を全言語で示した。
クローズドソースモデルとの比較でも、Gemma2は健闘している。もちろん、Claude 3.5 Sonnet、Gemini 1.5 Pro、GPT-4oといった上位のクローズドソースモデルには及ばないものの、GPT-3.5-turbo、Gemini 1.0 ProやGemini 1.5 Flash、Claude-3-haikuといった低コストのクローズドソースモデルと比較して、Gemma2は互角以上の性能を発揮したのだ。特に、Gemma2 27Bモデルが、GPT-3.5-turboやGemini 1.0 Proを上回る総合性能を記録した点は特筆に値する。
今後は、これらの有力オープンソースモデルに、イーロン・マスク氏のAI企業xAIが開発するGrokモデルが加わる見込みで、ベンチマーク順位の入れ替わりは一層激しくなる見込みだ。
文:細谷元(Livit)