
メタのLlama3.1 405BがGPT-4に匹敵 AI市場で起こるオープンソース変革、合成データでAI開発はさらに加速へ
INDEX
GPT-4レベルのモデルをカスタマイズ可能に、メタのLlama3.1 405Bモデルがもたらす変革
生成AI市場において、これまでOpenAIのGPT-4、AnthropicのClaude、グーグルのGeminiなど、いわゆるクローズドソースモデルが圧倒的な精度を誇っており、オープンソースモデルは精度面で後塵を拝する状況が続いていた。
メタが2024年7月23日に発表したLlama3.1により、この状況が大きく変わろうとしている。Llama3.1は、3つのサイズ(パラメータ数)からなるモデルファミリー。最小かつ最速が80億パラメータのLlama3.1 8Bモデル、中型が700億パラメータのLlama3.1 70B、最大となるのが4,050億パラメータのLlama3.1 405Bモデルだ。トレーニングには、1万6,000台のNVIDIA・H100が使用されたという。
この中で特に注目されるのが、Llama3.1 405Bモデルだ。4,050億パラメータを持つこのモデルは、OpenAIの最新フラッグシップモデルGPT-4o、またAnthropicの最新モデルClaude3.5 Sonnet、グーグルのGemini1.5 Proに並ぶ性能を有するだけでなく、オープンソースという特性から、カスタマイズできる柔軟性を備えている。
Llama3.1 405Bの特徴として、12万8,000トークンのコンテキストウィンドウを持つことが挙げられる。これは約400ページのドキュメントに相当する長文を処理できることを意味する。前モデルであるLlama3 70Bのコンテキストウィンドウ、8,000トークンから大きな飛躍となる。
また、Llama3モデルは、対応言語が英語のみであったが、Llama3.1は、英語に加え、ポルトガル語、スペイン語、イタリア語、ドイツ語、フランス語、ヒンディー語、タイ語に対応する多言語対応モデルに進化した。日本語は対応言語に含まれていないが、確認したところでは、ある程度のやり取りは可能のようだ。
SambaNovaのプレイグラウンドでLlama3.1 405Bを実際に試すことができる。
Llama3.1 405B、ベンチマークの詳細
Llama3.1 405Bの性能を詳しく見ていきたい。メタによると、150以上のベンチマークデータセットを用いて評価を行ったという。これらのデータセットは広範な言語をカバーしており、さらに実世界のシナリオを想定した人間による評価も実施されている。
https://ai.meta.com/blog/meta-llama-3-1/
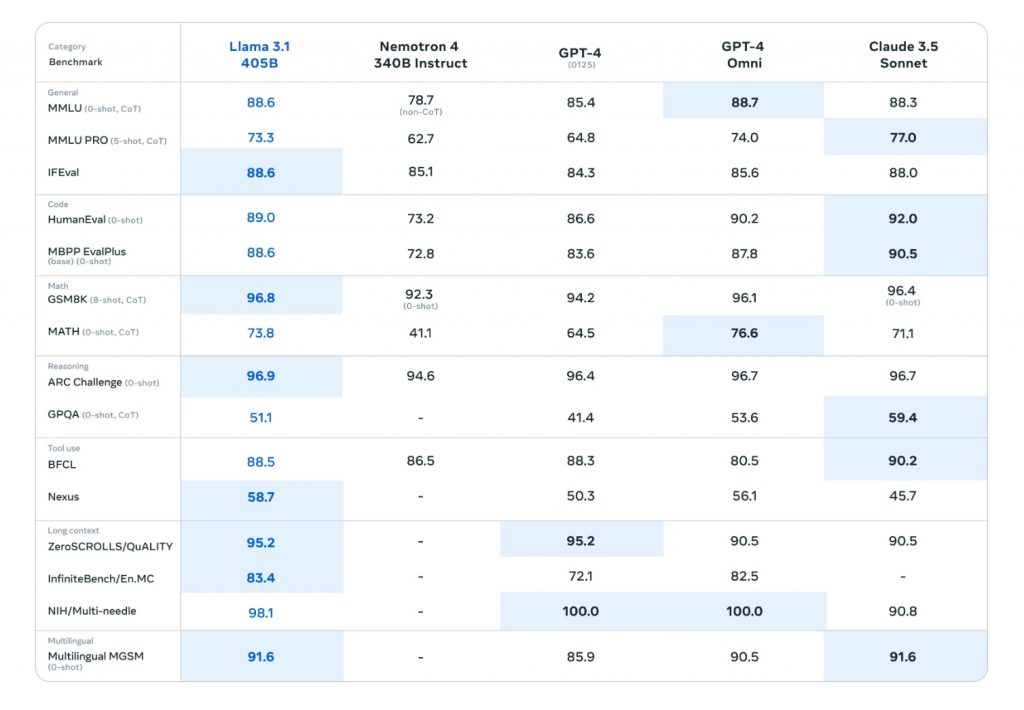
一般的な知識や推論能力を測るMMLUでは88.6%を獲得し、GPT-4oの88.7%、Claude 3.5 Sonnetの88.3%と肩を並べている。より難度の高いMMLU PROでは73.3%を記録し、GPT-4oの74.0%に肉薄する結果を示した。
コーディング能力を測るHumanEvalでは89.0%を獲得。GPT-4oの90.2%、Claude 3.5 Sonnetの92.0%には及ばないものの、トップの水準を記録。数学的問題解決能力を測るGSM8Kでは96.8%という高得点を記録し、GPT-4oの96.1%、Claude 3.5 Sonnetの96.4%を超えた。
推論能力を測るARC Challengeでは96.9%を獲得し、GPT-4oの96.7%、Claude 3.5 Sonnetの96.7%をわずかながら上回った。一方、より高度な推論能力を要するGPQAでは51.1%にとどまり、GPT-4oの53.6%、Claude 3.5 Sonnetの59.4%には及ばなかった。
長文理解能力を測るZeroSCROLLS/QuALITYでは95.2%を記録し、GPT-4(0125)と同率となった。また、多言語での数学的問題解決能力を測るMultilingual MGSMでは91.6%を獲得し、GPT-4oの90.5%を上回り、Claude 3.5 Sonnetと肩を並べた。
これらのベンチマーク結果は、Llama3.1 405Bが総合的に高い性能を持つことを示している。特に一般的な知識、コーディング、数学、長文理解、多言語能力において、クローズドソースの最先端モデルと互角以上の性能を発揮している点は注目に値する。
高度モデルが可能とするデータの合成、AI開発はさらに加速
Llama3.1 405Bのような高性能モデルの登場により、AI開発のさらなる加速が期待される。特に注目されるのが、合成データ生成への応用だ。
AIモデルの性能を左右する要素の1つはパラメータ数だが、最近それ以上にデータ品質が重要視されるようになってきている。パラメータ数が多くても、トレーニングに使うデータ品質が低いと、モデルの出力精度も低くなってしまうためだ。
OpenAIはGPT-4のパラメータ数を公にしていないが、推定では1兆以上あるといわれている。もし、この推定が正しければ、Llama3.1 405Bは4,050億という半分以下のパラメータ数で、GPT-4とほぼ同じパフォーマンスを達成したことになる。この背景には、データ品質の大幅改善があったと考えられるのだ。Llama3.1以外にも、大型モデルのパフォーマンスを超える小型モデルが続々登場しているが、それもデータ品質の改善が大きく寄与していると想定される。
今後のAI開発における重要課題は、大量の高品質データによるデータセットをどのように構築するのかということ。
そこで登場するのが、Llama3.1 405Bのような高度モデルだ。実際、メタはLlama3.1 405Bのユースケースの1つとして、合成データ生成を挙げており、AIコミュニティにおける利用を促進しようとしている。またメタ自身もLlama3.1ファミリーの開発において、「合成データ」を活用したことを明らかにしており、その効果を実証した格好となる。
合成データの自由度が高まると、これまで難しいとされてきたAIモデルの開発が一気に加速する可能性がある。
たとえば、医療分野では、患者のプライバシー保護や稀少疾患のデータ不足が常に課題となっている。高品質な大規模言語モデルを用いて精密な合成医療データを生成することで、これらの問題を解決しつつ、より精度の高い診断支援AIの開発が可能になるかもしれない。
また金融分野でも、顧客の個人情報を含まない高品質な合成データを用いることで、より安全かつ効果的な不正検知システムや信用評価モデルの開発が進むことが期待される。さらには自動運転分野では、現実世界では再現が困難な危険な交通状況を合成データとして生成し、自動運転AIの学習に活用することで、安全性の向上につながる可能性がある。高品質なモデルを用いれば、より現実的で多様な交通シナリオを生成できるだろう。
ガートナーの調査では2024年までにAI開発に使用されるデータの60%が合成データになると予測されている。Llama3.1 405Bの成功は、この予測を裏付ける一例となるかもしれない。
Llama3.1 405Bの登場によって、オープンソースモデルの可能性は飛躍的に高まったといえる。メタのザッカーバーグ氏と同じく、AIモデルのオープンソース化を標榜するイーロン・マスク氏も、米メンフィスに開設したスパコンデータセンターで、AIモデルをトレーニング中だ。このデータセンターは10万台に上るH100で構成されており、強力なAIモデルの登場が期待される。
文:細谷元(Livit)