

GPT-4に匹敵するモデルを22人で開発したRekaとは?
OpenAIやAnthropicといった大手だけでなく、新興のAIスタートアップ「Reka」が業界の注目を集めている。2024年4月15日の最新報道によると、同社は22人の小規模チームで、GPT-4クラスのマルチモーダル言語モデル「RekaCore」を開発した。
Rekaは、ディープマインド、グーグル、メタの研究者らによって設立されたサンフランシスコに本拠を置くAIスタートアップだ。同社は、RekaEdge、RekaFlashに続くRekaシリーズの3つ目のモデルとして、最大規模でもっとも高性能なモデル「RekaCore」を発表したのだ。
RekaのCEOで共同創業者のダニ・ヨガタマ氏は、VentureBeatとのインタビューで、「高性能なモデルを非常に短期間で開発できる能力が当社の強みだ」と語った。共同創業者でチーフサイエンティストのイ・テイ氏は、「数千のH100 GPU」を使用してRekaCoreを開発したとしている。わずか1年足らずで業界最高峰となるGPT-4やClaude 3 Opusに匹敵するモデルを開発したRekaの存在は、OpenAIやAnthropic以外のAI企業に勢いを与える可能性がある。
RekaCoreは、パラメータ数は非公開だが、「非常に大規模なモデル」だという。公開データ、ライセンスデータ、テキスト、音声、動画、画像データなどさまざまなデータでトレーニングが実施された。
12万8,000トークンのコンテキストウィンドウにより、大量の情報を一度に取り込んで処理することができ、長文書の処理に適している。コンテキストウィンドウとは、プロンプトに入力できる情報(トークン)のことで、これが多いほど、AIモデルに与えられる文脈情報も多くなり、正確な回答を生成しやすくなる。12万8,000トークンは、OpenAIの最新モデルGPT-4 Turboと同じ量で、業界でも多い方に位置する。現在最高峰は、Claude3の20万トークン。10万トークン以上あれば、数十ページの文章を読み込ませることが可能となり、ユースケースも広がる。
Rekaは、すでにいくつかの大手企業や組織と提携し、モデルの普及に努めている。データクラウド大手のSnowflakeは最近、LLMアプリケーション開発サービス「Cortex」にRekaCoreとRekaFlashを採用すると発表した。また、オラクルやAI SingaporeもRekaのモデルを利用しているという。ヨガタマ氏は、RekaFlashとRekaEdgeの発表以来、企業からの引き合いが増え、多くの顧客パイプラインが構築されていると語る。今後数週間のうちに、さらなるパートナーシップを発表する予定だ。オープンソース化の予定はないとのこと。
Reka Coreの強み・弱み
RekaCoreの最大の強みは、マルチモーダル性能の高さにあるといえるだろう。
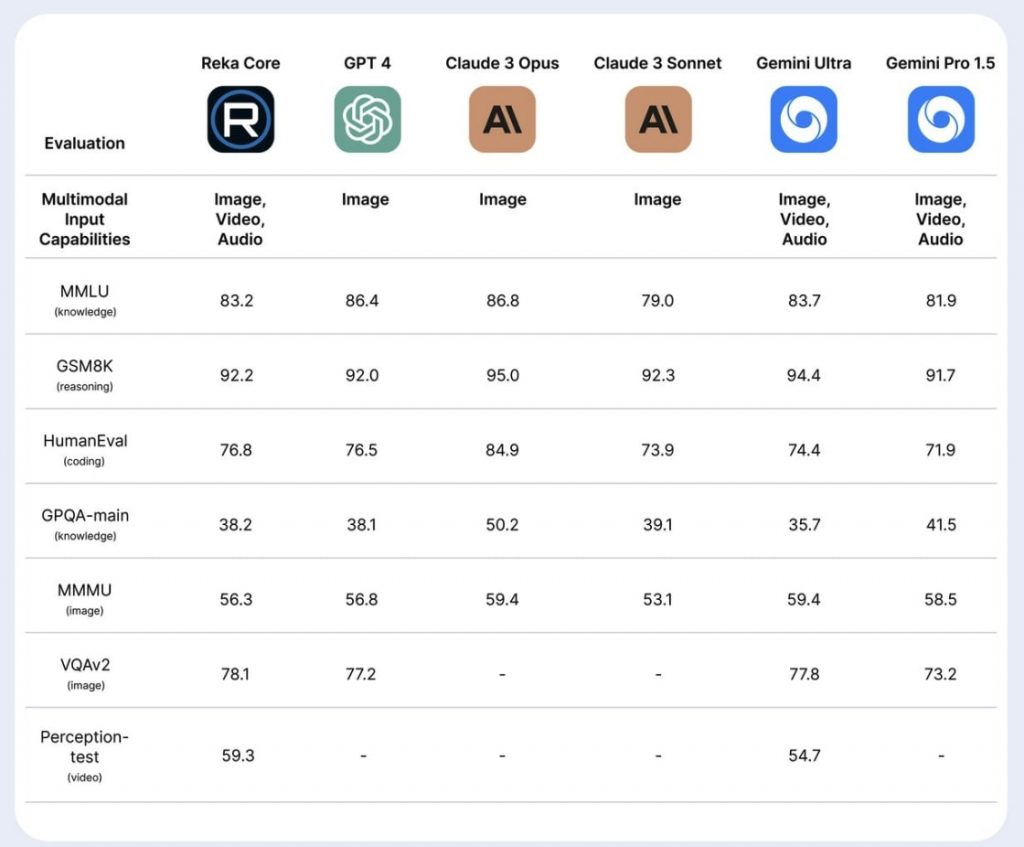
マルチモーダルとは、テキストだけでなく、画像、音声、動画など、さまざまなデータフォーマットに対応できる能力のこと。特に、単一モデルで動画まで対応できるAIは少なく、主要モデルの中ではGemini Ultraのみだった。
ここに動画認識能力を持つRekaCoreが参戦する格好となる。動画認識のPerception testでは、唯一のライバルであるGemini Ultraを大きく上回るスコア(59.3 vs 54.3)を記録。一方、写真などの静止画を対象とする画像の認識能力を測るMMMUベンチマークでは、GPT-4(56.8)、Claude 3 Opus(59.4)、Gemini Ultra(59.4)、Gemini Pro 1.5(58.5)に次ぐ56.3と主要モデルに肉薄する実力を示している。
Rekaのテクニカルレポートによれば、MMMUベンチマークのカテゴリー別のスコアでは、RekaCoreは「Art(芸術)」(86.7)、「Literature(文学)」(90.0)、「History(歴史)」(80.0)など人文系の分野で高得点を獲得。一方、「Electronics(電子工学)」(26.7)、「Physics(物理)」(36.7)、「Architecture and Engineering(建築・エンジニアリング)」(40.0)など理系の分野ではやや苦戦した。ただ、芸術理論から農業、機械工学に至るまで、幅広い分野で50%以上の高得点を維持しており、その汎用性の高さがうかがえる。


(https://publications.reka.ai/reka-core-tech-report.pdf)
ちなみに、MMMUベンチマークテストでは、以下のような問題が出題される。


また、知識タスクを測るMMLUでは83.2、基礎算数能力を測るGSM8Kでは92.2、コーディングのHumanEvalでは76.8と、GPT-4に並ぶ、または上回る高得点を叩き出した。さらに、RekaCoreは医療分野の推論タスクにおいて、専門特化型のMed-PaLM-2やGPT-4を超える実力も示した。3つのタスクの平均スコアは、Med-PaLM-2が79.4、GPT-4が81であるのに対し、RekaCoreは81.3を記録した。

https://www.reka.ai/news/reka-core-our-frontier-class-multimodal-language-model
価格面では若干の努力が必要かもしれない。RekaCoreの利用料はインプット100万トークンあたり10ドル、アウトプット100万トークンあたり25ドルとなっている。GPT-4 Turboがインプット(100万トークンあたり)10ドル、アウトプット30ドルであることを鑑みると、価格面での魅力は高いとは言えないだろう。
RekaCore、日本語の実力は?
RekaCoreを日本語環境下で使用したところ、一長一短といった評価になった。
まず「生成AIに関する最新ニュースを教えてください」というプロンプトに対し、RekaCoreはOpenAIのGPT-4やグーグルのBERT、フェイスブックの画像認識AIなどのAIニュースに関する情報を日本語で生成した。評価したいのは、日本語のプロンプトに対し日本語で回答できる多言語能力の高さ。メタの最新モデル、Llama3が英語のみの対応なのに比べ、RekaCoreは日本語にも対応できている点は評価に値する。日本語の文章も自然で読みやすく、違和感はない。

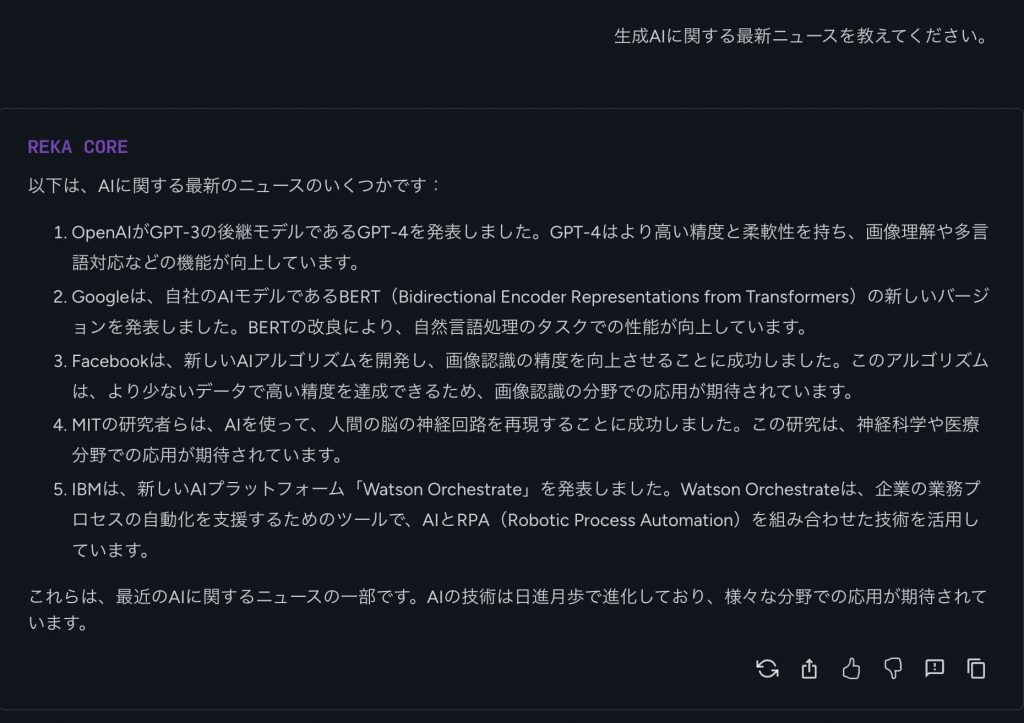
ただし、引用ソースが提示されていないため、この情報自体が正確かどうかを吟味する必要がある。ここでは、リアルタイム情報の検索に長けたPerplexityを使い、各情報の真贋を確かめてみる。

記述が確認できないものもあり、ニュース情報の検索では注意が必要といえるだろう。
もう1つ「Claude 3とは?」という質問を投げかけてみた。Claude 3とはOpenAIの競合であるAnthropicが2024年3月に発表した最新のAIモデル。RekaCoreの学習データは2023年11月までのものであるため、Claude 3の情報は持ち合わせていない。知らない情報に対して「わかりません」と回答するのが妥当なところだが、多くのAIモデルは、ありもしない情報を丁稚あげるハルシネーションを引き起こす傾向がある。RekaCoreがどのように反応するのかを調べてみた。
残念ながら、ハルシネーションが発生した。「Claude 3とは?」という質問に対し、一見正しく見える回答を生成したが、その内容はClaude 2から類推できるもので、Claude 3のことを解説しているのかはわからない。そこで「Claude3の3つのモデルを教えてください」という追加質問したところ、RekaCoreは、3つのモデル「Claude 3(Base)」「Claude 3(Large)」「Claude 3(XL)」の存在を指摘。しかし、実在する3つのモデルはOpus、Sonnet、Haikuであり、Base、Large、XLなどのモデルは存在せず、明らかなハルシネーションとなった。


日本語環境下でRekaCoreを利用する際は、高度な質問に対してはハルシネーションが発生するリスクがあることに留意が必要だろう。正確性を担保するためには、プロンプトの工夫などが欠かせない。ただし、日本語への対応自体は一定のレベルに達しており、今後のアップデートで、さらなる精度向上が期待できそうだ。
文:細谷元(Livit)