



GeminiとはどのようなAIモデルなのか?
グーグルが新たに生成AIモデル「Gemini」を発表した。OpenAIのGPT-4を意識した高い推論能力を売りとするAIモデルで、実際どれほどの実力を有するのかに注目が集まっている。
OpenAIの生成AIチャットモデルにGPT−3.5やGPT−4などといくつかのグレードがあるように、Geminiにも4つのグレードが存在する。AIモデルサイズの順に「Gemini Nano-1」「Gemini Nano-2」「Gemini Pro」「Gemini Ultra」の4つだ。
Geminiが注目される理由は、サイズが最も大きい最上位モデルとなるGemini Ultraが複数のベンチマークテストにおいて、現在市場で最も優れているといわれるOpenAIのGPT-4を超えたとされているためである。


GPT−4に対するGemini Ultraのベンチマークスコアは、テクニカルレポートのほか、Geminiの発表ページでも大々的に強調されており、それがメディアや公衆の関心を引いた。実際どのようなベンチマークスコアが示されているのか、グーグルが発表したテクニカルレポートを参考に見ていきたい。
まずテキスト生成での、AIモデルの言語理解能力を図るMMLU(Massive Multitask Language Understanding)テストでは、GPT-4が86.4%だったのに対し、Gemini Ultraは90%を獲得。MMLUとは、文学、歴史、科学、数学など57の異なる分野の知識を評価するデータセットで、特にAIモデルが多様なタスクにどれほど対応できるのかを広範に評価するもの。
Gemini Ultraが90%を獲得したということは、MMLUが提供するタスクや問題の90%を正確に回答できたことを意味。グーグルによるGeminiのテクニカルレポートでは、このMMLUテストにおける他モデルの結果も示されている。その結果は以下のようになった。
OpenAI、GPT−3.5:70%
グーグル、PaLM2:78.4%
Anthropic、Claude2:78.5%
InflectionAI、Inflection−2:79.6%
xAI、Grok1:73
メタ、Llama−2:68%
テキスト生成では、MMLUを含め9つのベンチマークテストが実施されたが、Gemini Ultraはとりわけ算数・数学とコーディングで高い能力を発揮できる可能性が示されている。
たとえばGSM8Kテストにおいて、Gemini Ultraは94.4%という100%に近いスコアを獲得し、GPT−4の92%を上回った。GSM8K(Grade School Math 8K)とは、8,000の小学校レベルの算数・数学問題によって構成されるデータセットで、AIの数学的推論能力を評価する際に広く用いられている。
また高等数学を対象とするベンチマークテストMATHでもGemini Ultraは、GPT-4(52.9%)を上回る53.2%を獲得。MATHは、他モデルが20〜30%台で苦戦する難しいベンチマークテストであるが、その中で50%を超えたことはGPT-4とともに特筆されるべきだろう。
ほとんどのベンチマークテストでGemini UltraはGPT−4を上回っているが、その差は数ポイントにとどまる。
唯一7ポイント以上の差で、GPT-4を超えたのがコーディング能力を評価するHumanEvalだ。GPT-4が67%だったのに対し、Gemini Ultraは74.4%を獲得。このベンチマークテストは、関数の実装、アルゴリズムの問題解決、データ処理タスクなど、幅広いコーディングのスキルを要求するもの。グーグルのテクニカルレポートによると、このベンチマークでの最高値はGemini Ultraの74.4%。これにAnthropicのClaude2が70%、GPT-4が67%、Grok 1が63.2%、GPT-3.5が48.1%などと続く。

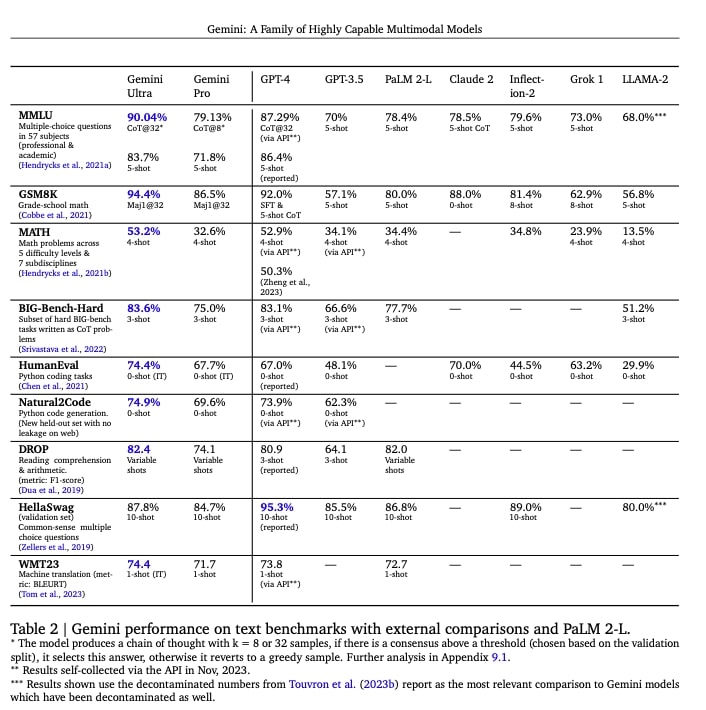
公開された9つのベンチマークテストのうち、Gemini Ultraは8つのテストでGPT−4を超えるパフォーマンスを示した。唯一、コモンセンス推論能力を評価するHellaSwagテストで、GPT-4や他モデルよりも低い数値に。HellaSwagベンチマークテストにおけるGPT-4のスコアは95.3%。これにInflection-2が89%、そしてGemini Ultraが87.8%、PaLM2が86.8%、GPT−3.5が85.5%などと続いた。
HellaSwagは、与えられたコンテキスト(文章や状況の記述)に基づいて、最も論理的または自然な続きを予測するタスクや日常的な状況や一般的な知識に関する問題などを選択式で回答させるテスト。GPT-4はコンテクスト理解能力が高いといわれているが、それがこの数値にも表れた格好となる。
海外メディア報道における厳しい評価、その理由とは?
これらの数字を根拠に「GPT-4を超える」との謳い文句で大々的に発表されたGeminiだが、メディアの評価はグーグルが予想したものにはならなかった。
主要テックメディアの1つTechcrunchは、2023年12月8日「Early impressions of Google’s Gemini aren’t great」と題した記事で、実際にGeminiを利用したユーザーの声を交え、現時点のGeminiは「期待はずれ」であると論じているのだ。他のメディアも同じような論調でGeminiを評価している。
なぜGeminiに対してこれほど厳しい評価が下されたのか。
理由の1つとして、期待とのギャップが増大してしまったことが挙げられるだろう。
グーグルはGeminiの発表ページにおいて、上記のテクニカルレポートを参照する型で、GPT-4に対して、Gemini Ultraがいかに優れているのかを強調する文言を多用している。
しかし現在、ユーザーが同社のチャットサービスBardを通じて利用できるのは、Gemini Ultraではなく、その下位互換バージョンとなるGemini Proのみ。このGemini Proのテクニカルレポート上でのベンチマークテスト結果は、GPT-4に比べ大きく劣っており、GPT-4以上のパフォーマンスを期待していたユーザーを裏切ることになり、それが多くの酷評につながったものと考えられる。
Gemini Proのベンチマークテストの結果は概して、OpenAIのGPT−3.5を上回るものの、GPT−4やGemini Ultraに比べると大きく劣っている。たとえば、上記でも触れたがMMLUベンチマークテストでは、Gemini Ultraが90%、GPT−4が87.29%と高いスコアを達成している一方、Gemini Proのスコアは79.1%と80%に満たない。
また一部のユーザーが指摘するように、発表ページにおける比較方法が平等なものにはなっておらず、これにより期待ギャップが膨らんだ可能性もある。たとえば、Geminiの発表ページでは、MMLUでのベンチマークテスト結果に関して、Gemini Ultraが90%、GPT−4が86.4%であったと示されている。しかし、Gemini Ultraの数値は「CoT@32」、GPT-4の数値は「5−shot」という方法によって得られたものであることが小さく記載されているのだ。

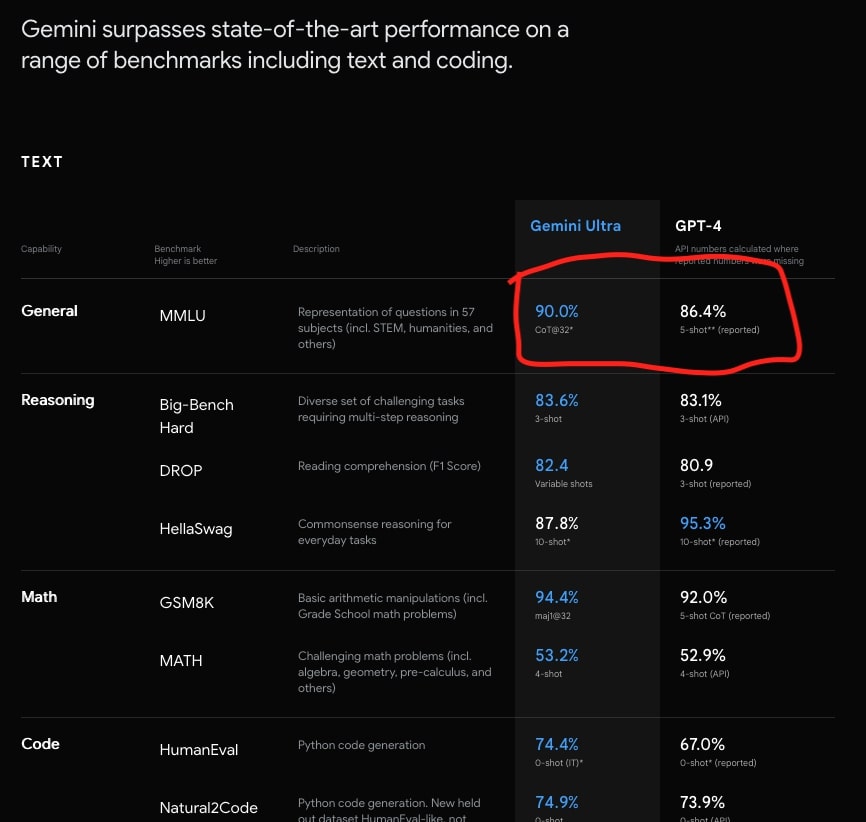
「CoT@32」とは、AIモデルが32のサンプル(トークン)を用いて「思考の連鎖(Chain of Thought)」を生成し、その中から最も論理的かつ正確と思われる回答を選択するというアプローチ。一方「5-shot」とは、AIモデルに5つの事例を与え、タスクを学習させてから、任意のプロンプトに対する回答を生成させるアプローチとなる。
この発表ページの数値に関しては、異なるアプローチによる比較であること、またGPT−4に関しては低い方の数値が記載されるなど、ミスリードするものであると指摘されている。
同じ土俵で比較するGemini Ultra、Gemini Pro、GPT-4
この点テクニカルレポートでは同等の比較がなされており、各モデルのパフォーマンス予想に適したものといえる。
CoT@32アプローチで、MMLUのベンチマークテストを行うと、Gemini Ultraは90.02%、Gemini Proは79.13%、GPT−4は87.29%となる。一方、5−shotでMMLUのベンチマークテストを行うと、Gemini Ultraは83.7%、Gemini Proは71.8%、GPT-4は86.4%という結果になる。

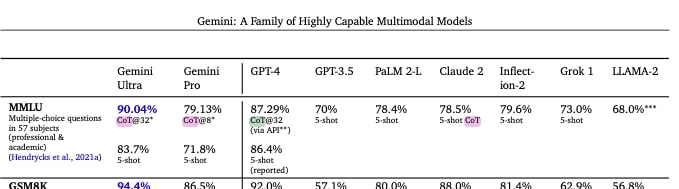
このことから、まず5-shotアプローチで比較した場合、最も高いパフォーマンスを示すのは、依然としてGPT-4であるということがわかる。またこのアプローチでは、Geminiのパフォーマンスが著しく下がってしまう傾向も判明している。Gemini Proに至っては71.8%となり、同じ5-shotアプローチによるGPT−3.5のベンチマークスコアである70%とほぼ同じ水準であることが示されているのだ。
つまり、多くのユーザーがGPT−4を超えるとの期待とともにBardを通じてGemini Proを利用してみたものの、タスクによっては、GPT−3.5と変わらない結果となり、それが大きな落胆につながったと考えられる。
それでもGemini Proは、英語から日本語への翻訳タスクでGPT−4に比べスムーズな日本語を生成する場合も多く、多言語タスクなどで利用が増える見込みがある。
Gemini Ultraの利用開始は2024年になる予定。テクニカルレポートが示す通りほとんどのタスクでGPT−4を超えることができるのであれば、OpenAIにとって脅威となるかもしれない。しかし、その頃にはOpenAIもGPT−4のアップグレード版や新モデルであるGPT−5をリリースしている可能性があり、AI分野の競争はさらに激化することが予想される。
文:細谷元(Livit)