

生成AI市場、オープンソースとクローズドソースの競争に
ブルームバーグの予測によると、生成AI市場は年間成長率42%で拡大し、2032年には1兆3,000億ドルに達する可能性がある。
2022年時点では、ITハードウェア、ソフトウェアサービスを含むテクノロジー支出に占める生成AIの割合は1%未満だったが、2032年には10%に拡大する見込みだ。


生成AI需要の急騰により、生成AIソフトウェア分野の市場規模は、2022年の14億9,300万ドルから2032年には2,800億ドルと187倍の規模に膨れ上がるという。
この生成AIソフトウェアのベースとなるのは、OpenAIが提供するChatGPTの基盤となるGPT‐3.5やGPT‐4などの大規模言語モデル(LLMs)。大規模言語モデルは、OpenAI、Anthropic、Cohereなどの主要AIスタートアップが豊富な資金力と影響力を背景に、現在市場シェアの大半を占めている状況だ。
しかし今後の市場拡大に伴い競合の参入も増え、競争は激化するものとみられる。
OpenAI、Anthropic、Cohereが先行する市場において、後発組はオープンソースモデルによって市場シェアの獲得を画策している。
OpenAI、Anthropic、Cohereなどの大規模言語モデルは、ソースコードが公開されていないクローズドソースモデル。これらの大規模言語モデルを利用するには、APIを介したアクセスが必要で、ほとんどのケースにおいて有料だ。
一方オープンソースの大規模言語モデルは、ソースコードが公開されており、基本的には無料で利用することができる。またライセンス条件にもよるが、商用利用も可能となる。
オープンソース大規模言語モデルの開発・提供で最も大きな存在感を示すのは、GAFAMの一角メタだ。マイクロソフトがOpenAIに多額の資金を投じているように、アマゾンはAnthropic、グーグルはCohereに資金を投じ戦略的な提携関係を結び、今後予想される生成AI市場の急拡大に備え動きを活発化している。メタはこれに対抗し、オープンソース戦略で生成AI市場における存在感を高める計画だ。
オープンソースの代表格、メタのLLaMa2、そのパフォーマンスとは?
メタの最新主力モデル「LLaMa2」は、クローズドソースに対抗するオープンソース大規模言語モデルの代表格と目されている。生成AI市場で現時最も優れたモデルとされるOpenAIのGPT-4に近い数値を叩き出したとして注目される存在となっているのだ。
サンフランシスコ拠点のAIスタートアップGalileo Labsは、OpenAIのGPTモデルと主要なオープンソース大規模言語モデルのパフォーマンス比較を実施、その結果を2023年11月15日に公開した。
この調査は、依然GPT-4が飛び抜けた存在であることを再確認させるものだが、同時にオープンソースモデルもGPT-4やGPT−3.5に近いパフォーマンスを発揮できることを示しており、今後のオープンソースモデルの開発にさらなる弾みをつけるものでもある。
調査では、大きく3つの方法で大規模言語モデルのパフォーマンスが計測された。
1つは、各モデルに外部からの情報を一切与えず、モデル内のデータのみで質問に回答させ、その回答精度を「Correctness Score」で評価するものだ。質問に対して、幻覚症状を起こさず、ファクトを正しく伝えられるのかが評価されている。

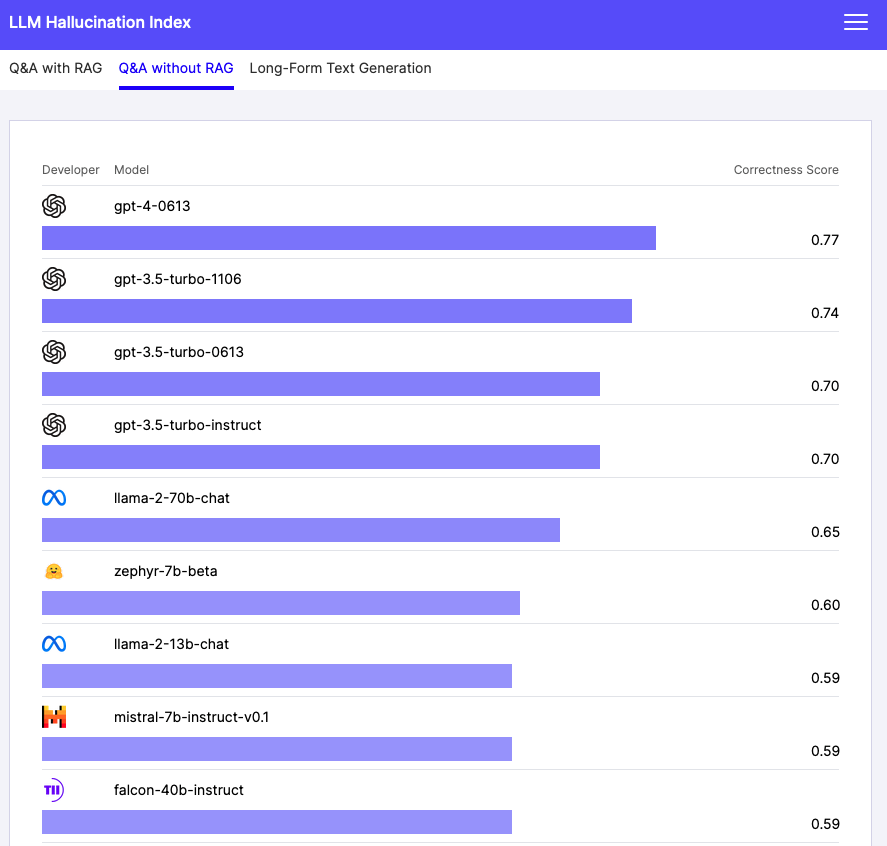
この実験で、最も高いスコアを記録したのはやはりGPT‐4。Correctness Scoreは0.77となり、高い精度で回答を生成できることが示された。これに対し、メタのLLaMa2(70b-chat)は0.65を記録。GPT-4には及ばないものの、GPT-3.5(turbo-instruct)の0.70に肉薄するスコアを獲得した。
2つ目の実験では、各モデルに外部情報を与え、外部情報に関する質問にモデルがどれほど正しく回答できるのかが計測された。ここでは「Context Adherence Score」が用いられ、モデルが回答を生成する際、与えられた外部情報を正しく認識できているのかが評価されている。

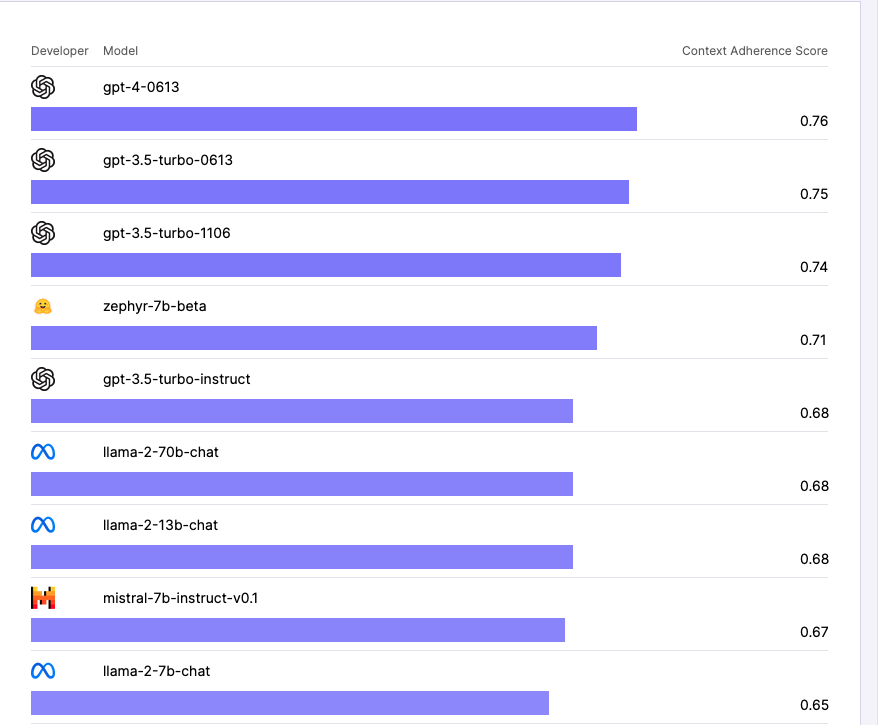
Context Adherence ScoreにおいてもGPT-4が0.76でトップ。一方この実験では、HuggingFaceのオープンソースモデル「zephyr-7b-beta」が0.71を獲得し、GPT‐3.5(turbo-instruct)の0.68を上回るパフォーマンスを示した。また、LLaMa2モデルの1つであるLLaMa2‐70b-chatモデルともう1つのLLaMa2‐13b‐chatモデルがともに0.68を記録、GPT−3.5(turbo-instruct)に並ぶ結果となったのだ。
さらに、別のオープンソースモデル「mistral-7b-instruct-v0.1」が0.67を記録するなど、外部情報が与えられた場合、オープンソースモデルのパフォーマンスが全体的に高まる傾向が示された。
LLaMa2、長文生成でGPT-4に並ぶパフォーマンスを発揮
最後の実験は、長文生成のパフォーマンステストだ。ここでは「Correctness Score」により、各モデルの長文生成能力が評価された。
3つの実験の中で、特にLLaMa2のパフォーマンスが顕著に向上しており、今後の生成AIソフトウェア開発において非常に重要な示唆を与えるものだ。
長文生成におけるCorrectness Scoreのトップは0.83を獲得したGPT-4だったが、LLaMa2(70b‐chat)が0.82とほぼ同じスコアを記録、GPT-3.5の最新版であるGPT-3.5-turbo-1106モデル(スコア0.82)に並んだだけでなく、GPT-3.5-turbo-0613(0.81)やGPT-3.5-turbo-instruct(0.74)を上回る結果となった。

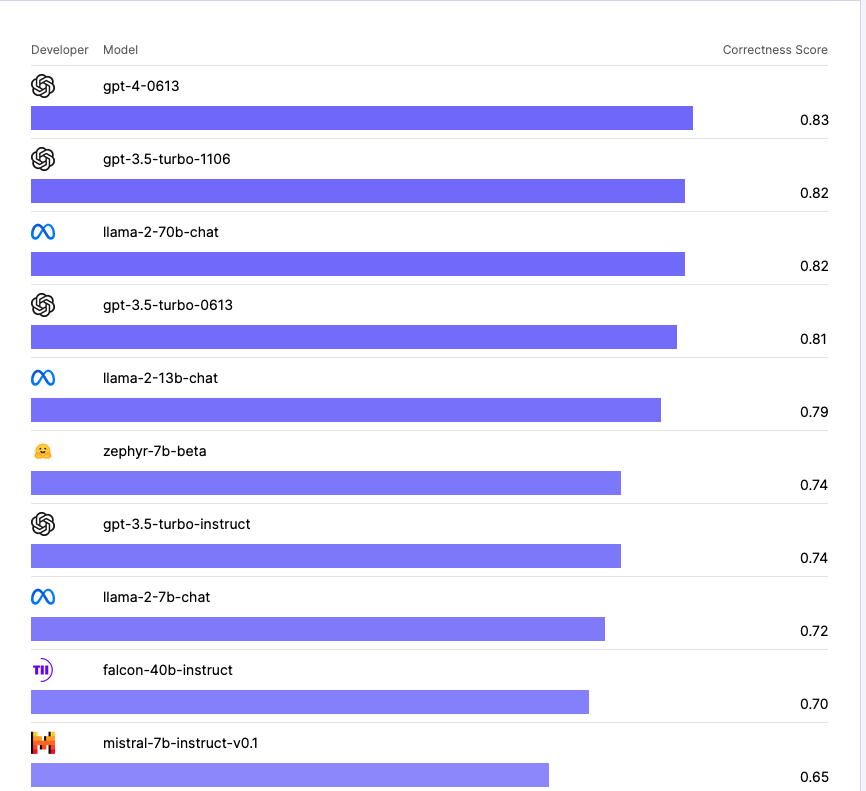
この結果は、今後の生成AIソフトウェア開発において、どのような場面でどのAIモデルを利用するのかに関するガイドラインにもなり得る。
実際Galileo Labsもこの調査結果を受け、オープンソースモデルによるコスト節約の可能性を指摘している。たとえば、一般的な質問応答においては、OpenAIモデルが無難な選択肢となるが、長文生成においては、LLaMa2を利用することで、パフォーマンスを維持しつつ、コストを大幅に下げることが可能となる。長文生成において最高パフォーマンスを記録したのはGPT‐4だが、GPT-4の利用料は非常に高額。これに対し、LLaMa2はほぼ同じパフォーマンスを維持しつつ、無料で利用できるため、コスト節約効果は非常に大きくなる。
今回の実験では、オープンソースモデルとしてメタのLLaMa2のほか、アラブ首長国連邦ドバイ政府傘下のTechnology Innovation Institute(TII)が開発したFalconモデル(Falcon-40b-instruct)、シリコンバレーのAI企業Mosaic MLが開発したMPTモデル、フランスのAI企業Mistral AIが開発したMistralモデル、そしてHugging FaceのZephyモデルが分析対象となった。
いずれもAIデベロッパー界隈では注目される存在で、各社・機関による開発活動も積極的に進められている。今後の生成AI市場は、クローズドソースモデルだけでなく、オープンソースモデルの存在感も増してくることになるだろう。
文:細谷元(Livit)