
画像AIの発展が止まらない。
画像認識からブレイクスルーを起こした画像AIは、画像自動生成の分野でも発展を続けている。以前紹介したモザイクから元画像に類似する高画質画像を自動生成する技術も興味深かったが、今回はまた別の技術を紹介したい。
SpaceXなどで有名なイーロン・マスク氏が共同会長を務める、米国の非営利研究企業OpenAIは、半分の画像を入力するだけで残りの半分を自動生成する技術を発表した。その他の類似研究と違う点は、文章を分析する自然言語処理の技術を転用しているところだ。
文章生成に長けたGTP-2モデルを画像生成に応用


今回OpenAIが発表した技術には、GPT-2モデルが使われている。GPT-2モデルは、OpenAIが2019年に発表した自然言語処理のモデルだ。このモデルはインターネット上にあるウェブページを800万ページ分学習し、ドメイン知識に左右されない大規模な言語モデルとなっている。
アルゴリズムは、画像認識でよく用いられるRNN(Recurrent Neural Network)やCNN(Convolutional Neural Network)を使わず、どの部分に注目したのかを明示してくれるAttention(注意機構)のみを用いたTransformerを使っている。
Transformerは、Google検索のBERTという自然言語処理モデルに用いられている、自然言語処理領域において事実上の標準となっているようなモデルだ。このGPT-2モデルの、文章を分析して補完する技術を今回の研究で応用した。
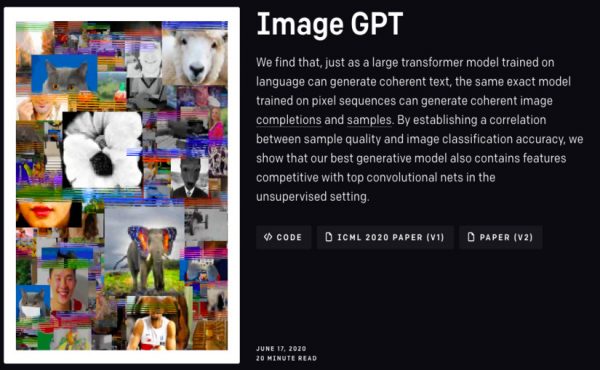
画像をまずは前処理として低解像度化し、ピクセルに入っている色情報などをモデルに学習させる。そして文を補完するのと同じように、学習済みのモデルを使って画像を補完することができた。
半分だけの画像を入力すると、残り半分を自動生成して出力する。サンプルなどを見てみると、元ネタを知らなければ普通の画像に見えるほど自然な画像が生成されているのがわかる。


現状は低解像度化した画像を学習させているため、まだ低解像度の画像しか生成できない。しかし、既存のその他画像生成モデルに比べると、高い結果を出しているのは間違いない。
今後もOpenAIは、どのようなAIを世の中に発信していくのだろうか。